2016-ICLR-Multi-Scale Context Aggregation by Dilated Convolutions
通过扩张卷积进行多尺度上下文聚合
摘要
最先进的语义分割模型基于最初设计用于图像分类的卷积网络的改编。然而,语义分割等密集预测问题在结构上与图像分类不同。在这项工作中,我们开发了一个新的卷积网络模块,专为密集预测而设计。所提出的模块使用扩张卷积来系统地聚合多尺度上下文信息,而不会丢失分辨率。该架构基于以下事实:扩张卷积支持感受野的指数扩展,而不会损失分辨率或覆盖范围。我们表明,所呈现的上下文模块提高了最先进的语义分割系统的准确性。此外,我们检查了图像分类网络对密集预测的适应性,并表明简化适应性网络可以提高准确性。
1. 引言
计算机视觉中的许多自然问题都是密集预测的实例。目标是为图像中的每个像素计算一个离散或连续的标签。一个突出的例子是语义分割,它要求将每个像素分类到一组给定的类别中(He et al, 2004; Shotton et al, 2009; Kohli et al, 2009; Krahenb ¨ uhl & Koltun, 2011)。语义分割具有挑战性,因为它需要将像素级精度与多尺度上下文推理相结合(He et al, 2004; Galleguillos & Belongie, 2010)。
最近,通过使用通过反向传播训练的卷积网络(LeCun et al, 1989)(Rumelhart et al, 1986),在语义分割中获得了显著的准确性提高。具体来说,Long 等人(2015)表明,最初为图像分类开发的卷积网络架构可以成功地重新用于密集预测。这些重新调整用途的网络在具有挑战性的语义分割基准方面大大优于现有技术。这引发了由图像分类和密集预测之间的结构差异引发的新问题。重新利用网络的哪些方面是真正必要的,哪些方面在密集操作时会降低准确性?专门为密集预测设计的专用模块能否进一步提高准确性?
现代图像分类网络通过连续池化和下采样层集成多尺度上下文信息,这些层降低分辨率直到获得全局预测(Krizhevsky et al, 2012; Simonyan & Zisserman, 2015)。相比之下,密集预测需要结合全分辨率输出进行多尺度上下文推理。最近的工作研究了两种方法来处理多尺度推理和全分辨率密集预测的冲突需求。一种方法涉及重复向上卷积,旨在恢复丢失的分辨率,同时从下采样层继承全局视角(Noh et al, 2015; Fischer et al, 2015)。这就留下了一个悬而未决的问题,即是否真的有必要进行严格的中间下采样。另一种方法涉及提供图像的多个重新缩放版本作为网络的输入,并结合为这些多个输入获得的预测(Farabet et al, 2013; Lin et al, 2015; Chen et al, 2015b)。同样,尚不清楚是否真的有必要对重新缩放的输入图像进行单独分析。
在这项工作中,我们开发了一个卷积网络模块,可以在不丢失分辨率或分析重新缩放的图像的情况下聚合多尺度上下文信息。该模块可以以任何分辨率插入到现有架构中。与从图像分类中继承的金字塔形架构不同,所呈现的上下文模块专为密集预测而设计。它是一个矩形棱柱的卷积层,没有池化或下采样。该模块基于扩张卷积,支持在不损失分辨率或覆盖范围的情况下对感受野进行指数扩展。
作为这项工作的一部分,我们还重新检查了重新调整用途的图像分类网络在语义分割方面的性能。核心预测模块的性能可能会被越来越复杂的系统无意中掩盖,这些系统涉及结构化预测、多列架构、多个训练数据集和其他增强。因此,我们研究了深度图像分类网络在受控环境中的主要适应性,并去除了阻碍密集预测性能的残留成分。结果是一个初始预测模块,它比之前的调整更简单、更准确。
使用简化的预测模块,我们通过对 Pascal VOC 2012 数据集(Everingham et al, 2010)的受控实验来评估所呈现的上下文网络。实验表明,将上下文模块插入现有的语义分割架构可以可靠地提高其准确性。
2. 扩张卷积
令 F : Z 2 → R F\ : \ \mathbb{Z}^2\rightarrow\mathbb{R} F : Z2→R 为离散函数。设 Ω r = [ − r , r ] 2 ∩ Z 2 \Omega_r=\left[-r,\ r\right]^2\cap\mathbb{Z}^2 Ωr=[−r, r]2∩Z2 并设 k : Ω r → R 是大小为 ( 2 r + 1 ) 2 k\ : \ \Omega_r\rightarrow\mathbb{R} 是大小为 \left(2r+1\right)^2 k : Ωr→R是大小为(2r+1)2 的离散滤波器。离散卷积算子 ∗ \ast ∗ 可以定义为
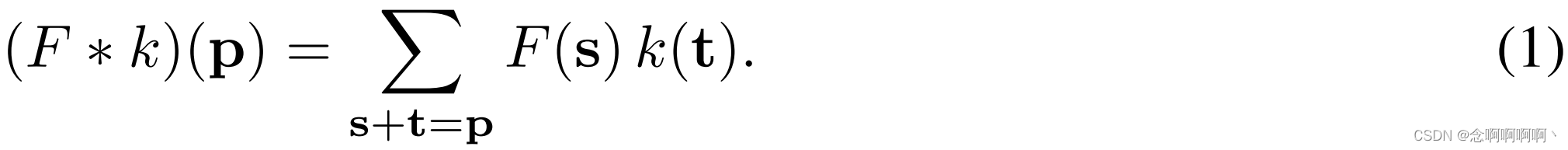
我们现在概括这个运算符。令 l l l 为膨胀因子,令 ∗ l \ast_l ∗l 定义为
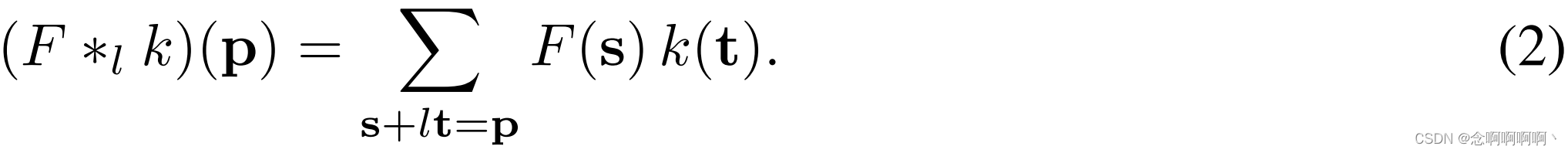
我们将 ∗ l \ast_l ∗l 称为扩张卷积或 l l l-扩张卷积。熟悉的离散卷积 ∗ \ast ∗ 就是 1 1 1-维卷积。
扩张卷积算子在过去被称为 “带扩张滤波器的卷积”。它在算法 algorithme a trous 中起着关键作用,这是一种小波分解算法(Holschneider et al, 1987; Shensa, 1992)。我们使用术语 “扩张卷积” 而不是 “带扩张过滤器的卷积” 来阐明没有构建或表示 “扩张过滤器”。卷积运算符本身被修改为以不同的方式使用过滤器参数。扩张卷积运算符可以使用不同的扩张因子在不同范围应用相同的过滤器。我们的定义反映了扩张卷积运算符的正确实现,它不涉及扩张过滤器的构造。
在最近关于用于语义分割的卷积网络的工作中,Long 等人(2015)分析了过滤器扩张但选择不使用它。Chen 等人(2015a)使用扩张来简化 Long 等人(2015)的架构。相比之下,我们开发了一种新的卷积网络架构,系统地使用扩张卷积进行多尺度上下文聚合。
我们的架构的动机是扩张卷积支持以指数方式扩展感受野而不会丢失分辨率或覆盖范围。让 F 0 , F 1 , . . . , F n − 1 : Z 2 → R F_0,F_1,.\ .\ .,F_{n-1}\ : \ \mathbb{Z}^2\rightarrow\mathbb{R} F0,F1,. . .,Fn−1 : Z2→R 为离散函数,令 k 0 , k 1 , . . . , k n − 2 : Ω 1 → R k_0,k_1,.\ .\ .,k_{n-2}\ : \ \Omega_1\rightarrow\mathbb{R} k0,k1,. . .,kn−2 : Ω1→R 是离散的 3×3 过滤器。考虑应用具有指数增长扩张的过滤器:
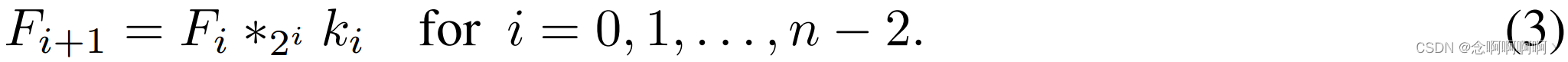
将 F i + 1 F_{i+1} Fi+1 中元素 p \mathbf{p} p 的感受野定义为 F 0 F_0 F0 中修改 F i + 1 ( p ) F_{i+1}\left(\mathbf{p}\right) Fi+1(p) 值的元素集合。设 F i + 1 F_{i+1} Fi+1 中 p \mathbf{p} p 的感受野大小为这些元素的个数。不难看出 F i + 1 F_{i+1} Fi+1 中每个元素的感受野大小为 ( 2 i + 1 − 1 ) × ( 2 i + 2 − 1 ) \left(2^{i+1}-1\right)\times\left(2^{i+2}-1\right) (2i+1−1)×(2i+2−1)。感受野是一个呈指数增长的正方形。如图 1 所示。
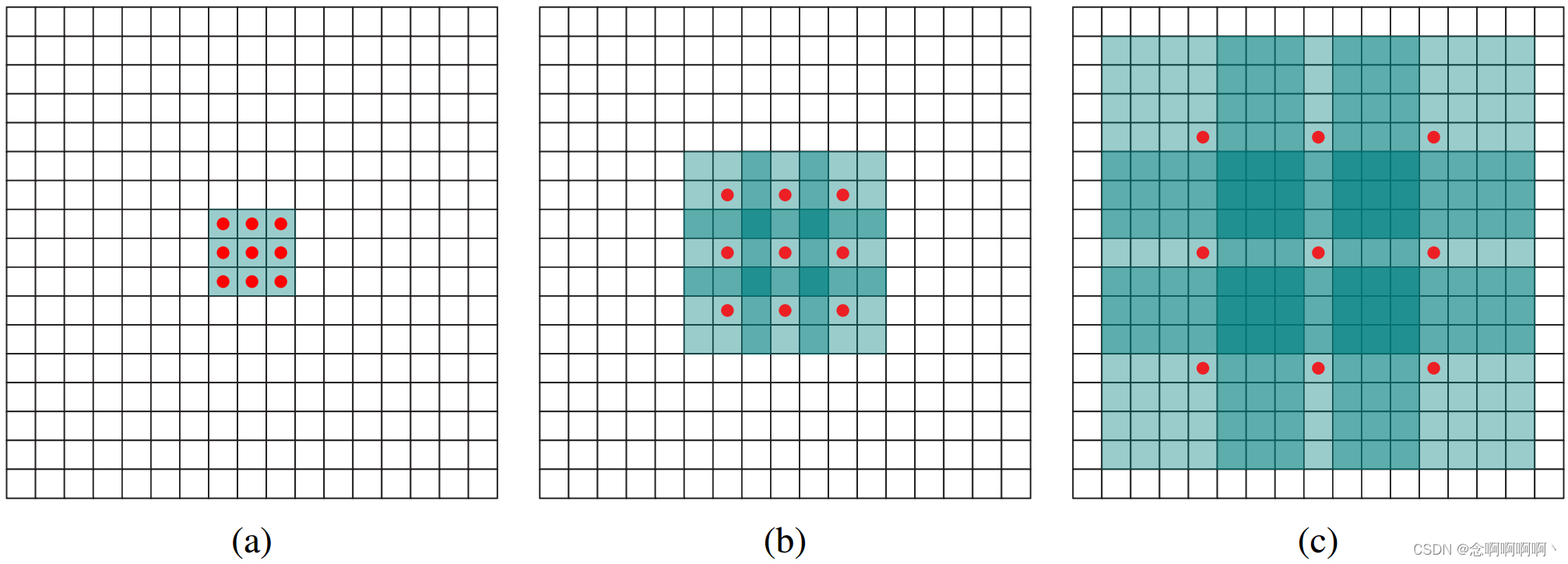
3. 多尺度上下文聚合
上下文模块旨在通过聚合多尺度上下文信息来提高密集预测架构的性能。该模块将 C C C 特征图作为输入并生成 C C C 特征图作为输出。输入和输出具有相同的形式,因此该模块可以插入到现有的密集预测架构中。
我们首先描述上下文模块的基本形式。在这个基本形式中,每一层都有 C C C 个通道。每个层中的表示是相同的,可用于直接获得密集的每类预测,尽管特征图未归一化并且模块内部没有定义损失。直观地说,该模块可以通过将特征图传递给公开上下文信息的多个层来提高特征图的准确性。
基本上下文模块有 7 层,应用具有不同膨胀因子的 3×3 卷积。扩张是 1、1、2、4、8、16 和 1。每个卷积在所有层上运行:严格来说,这些是 3 × 3 × C 3\times3\times C 3×3×C 卷积,在前两个维度上有扩张。这些卷积中的每一个后面都跟着逐点截断 m a x ( ⋅ , 0 ) max(·,0) max(⋅,0)。最后一层执行 1 × 1 × C 1\times1\times C 1×1×C 卷积并产生模块的输出。该体系结构总结在表 1 中。请注意,在我们的实验中,为上下文网络提供输入的前端模块以 64×64 分辨率生成特征映射。因此,我们在第 6 层之后就停止了感受野的指数扩张。
我们最初尝试训练上下文模块未能提高预测准确性。实验表明,标准的初始化程序并不容易支持模块的训练。卷积网络通常使用来自随机分布的样本进行初始化(Glorot & Bengio, 2010; Krizhevsky et al, 2012; Simonyan & Zisserman, 2015)。然而,我们发现随机初始化方案对上下文模块无效。我们发现了一个具有清晰语义的替代初始化更有效:

其中 a a a 是输入特征图的索引, b b b 是输出特征图的索引。这是一种身份初始化形式,最近被提倡用于循环网络(Le et al, 2015)。此初始化设置所有过滤器,以便每一层都将输入直接传递到下一层。一个自然的问题是,这种初始化可能会使网络处于反向传播无法显着改善简单传递信息的默认行为的模式。然而,实验表明情况并非如此。反向传播可靠地收集网络提供的上下文信息,以提高处理后特征图的准确性。
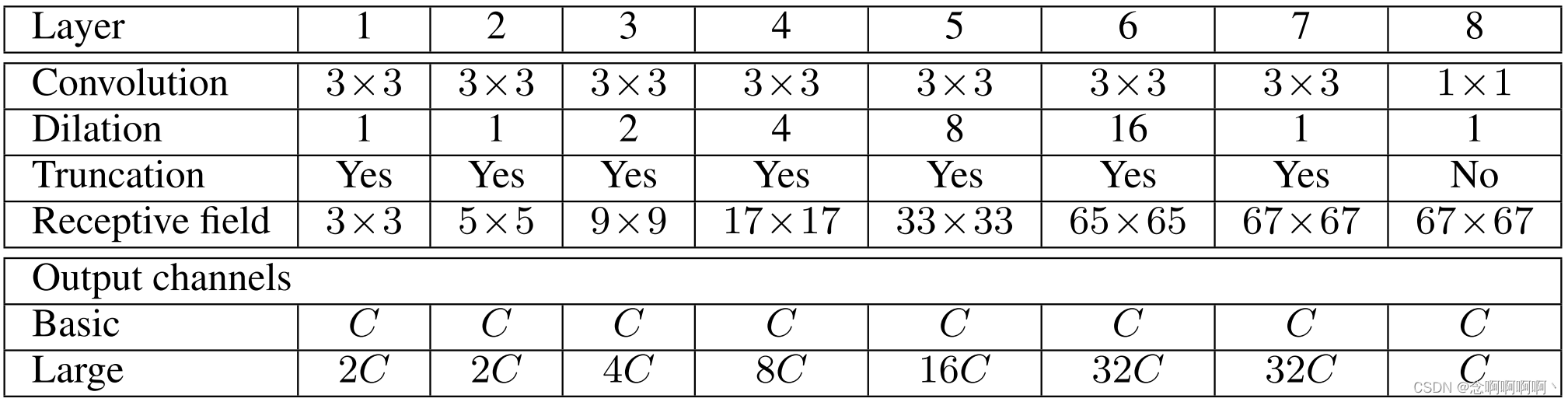
这样就完成了基本上下文网络的呈现。我们的实验表明,即使是这个基本模块也可以在数量和质量上提高密集预测的准确性。鉴于网络中的参数数量较少,这一点尤其值得注意:总共 ≈ 64 C 2 \approx64C^2 ≈64C2 个参数。
我们还训练了一个更大的上下文网络,它在更深层使用了更多的特征图。表 1 总结了大型网络中的特征图数量。我们概括了初始化方案以解决不同层中特征地图数量的差异。设 c i c_i ci 和 c i + 1 c_{i+1} ci+1 是两个连续层中特征图的数量。假设 C C C 整除 c i c_i ci 和 c i + 1 c_{i+1} ci+1。初始化是
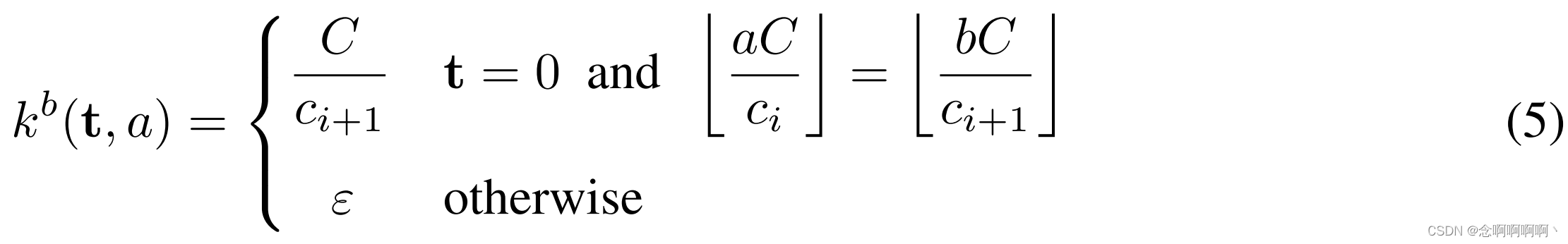
这里 ε ∼ N ( 0 , σ 2 ) \varepsilon\sim\mathcal{N}\left(0,\ \sigma^2\right) ε∼N(0, σ2) 和 σ ≪ C / c i + 1 \sigma\ll C/c_{i+1} σ≪C/ci+1。随机噪声的使用打破了具有共同前身的特征图之间的联系。
4. 前端(front-end)
我们实现并训练了一个前端预测模块,该模块将彩色图像作为输入并生成 C = 21 C=21 C=21 个特征图作为输出。前端模块遵循 Long 等人(2015)和 Chen 等人(2015a)的工作,但单独实施。我们调整了 VGG-16 网络(Simonyan & Zisserman, 2015)以进行密集预测,并删除了最后两个池化层(pooling)和跨越层(striding)。具体来说,这些池化层和跨越层中的每一个都被移除,并且对于每个被消融的池化层,所有后续层中的卷积都被扩大了 2 倍。因此,在两个消融池层之后的最后一层中的卷积被扩大了 4 倍。这使得可以使用原始分类网络的参数进行初始化,但会产生更高分辨率的输出。前端模块将填充图像作为输入并生成分辨率为 64×64 的特征图。我们使用反射填充(reflection padding):通过反射每个边缘的图像来填充缓冲区。
我们的前端模块是通过去除分类网络中不利于密集预测的残留而获得的。最重要的是,我们完全删除了最后两个池化层和跨步层,而 Long 等人保留了它们,而 Chen 等人用扩张替换了跨步但保留了池化层。我们发现通过移除池化层来简化网络可以使其更加准确。我们还删除了中间特征图的填充。中间填充用于原始分类网络,但在密集预测中既不必要也不合理。
这个简化的预测模块是在 Pascal VOC 2012 训练集上训练的,并通过 Hariharan 等人(2011)创建的注释进行了扩充。我们没有使用来自 VOC-2012 验证集的图像进行训练,因此只使用了 Hariharan 等人(2011)注释的一个子集。训练是通过随机梯度下降(SGD)进行的,小批量大小为 14,学习率为 10-3,动量为 0.9。该网络经过 60K 次迭代训练。
我们现在将我们的前端模块的准确性与 Long 等人(2015)的 FCN-8s 设计和 Chen 等人(2015a)的 DeepLab 网络进行比较。对于 FCN-8s 和 DeepLab,我们评估了原作者在 VOC-2012 上训练的公共模型。图 2 显示了不同模型对来自 VOC-2012 数据集的图像产生的分割。表 2 报告了 VOC-2012 测试集上模型的准确性。
我们的前端预测模块比之前的模型更简单、更准确。具体来说,我们的简化模型在测试集上的性能优于 FCN-8s 和 DeepLab 网络超过 5 个百分点。有趣的是,在不使用 CRF 的情况下,我们简化的前端模块在测试集上的排行榜精度优于 DeepLab + CRF 超过一个百分点(67.6% 对 66.4%)。


5. 实验
我们的实施基于 Caffe 库(Jia et al, 2014)。我们对扩张卷积的实现现在是标准 Caffe 分布的一部分。
为了与最近的高性能系统进行公平比较,我们训练了一个前端模块,该模块具有与第 4 节中描述的相同的结构,但在来自 Microsoft COCO 数据集的额外图像上进行了训练(Lin et al, 2014)。我们将 Microsoft COCO 中的所有图像与至少一个来自 VOC-2012 类别的对象一起使用。来自其他类别的带注释的对象被视为背景。
训练分两个阶段进行。在第一阶段,我们对 VOC-2012 图像和 Microsoft COCO 图像一起进行训练。训练由 SGD 进行,小批量大小为 14,动量为 0.9。以 10-3 的学习率执行 100K 次迭代,以 10-4 的学习率执行 40K 次后续迭代。在第二阶段,我们仅在 VOC-2012 图像上对网络进行微调。以 10-5 的学习率对 50K 次迭代进行了微调。来自 VOC-2012 验证集的图像未用于训练。
通过此过程训练的前端模块在 VOC-2012 验证集上实现了 69.8% 的平均 IoU,在测试集上实现了 71.3% 的平均 IoU。请注意,这个级别的准确性是由前端单独实现的,没有上下文模块或结构化预测。我们再次将这种高精度部分归因于去除了最初为图像分类而不是密集预测开发的残留成分。
Controlled evaluation of context aggregation。我们现在执行对照实验来评估第 3 节中介绍的上下文网络的效用。我们首先将两个上下文模块(基本和大型)分别插入前端。由于上下文网络的感受野是 67×67,我们用宽度为 33 的缓冲区填充输入特征图。零填充和反射填充在我们的实验中产生了相似的结果。上下文模块接受来自前端的特征图作为输入,并在训练期间获得此输入。在我们的实验中,上下文模块和前端模块的联合训练并没有产生显著的改善。学习率设置为 10-3。如第 3 节所述初始化训练。
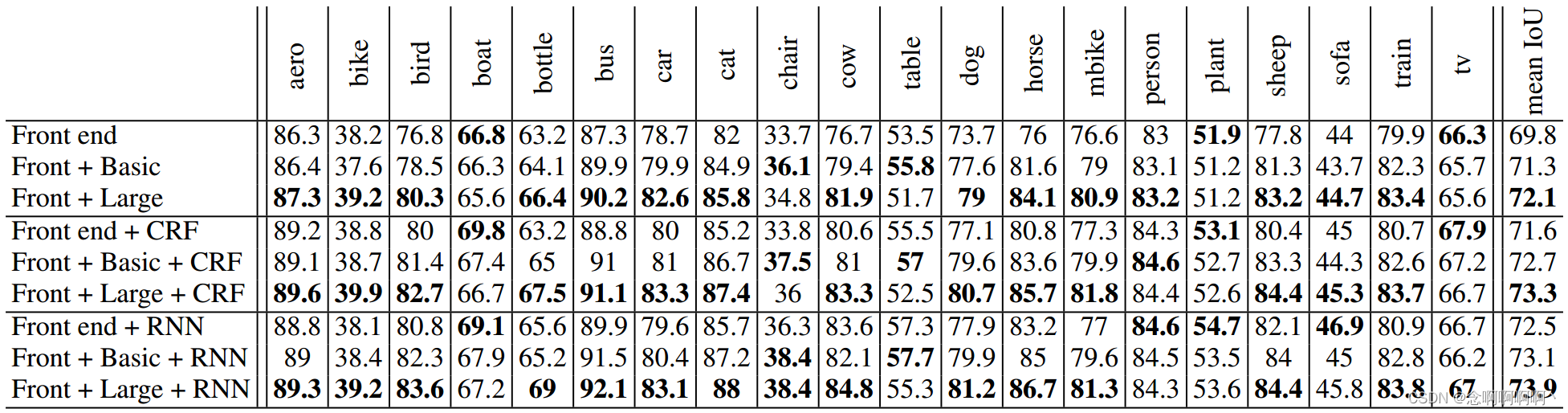
表 3 显示了将上下文模块添加到三种不同的语义分割架构中的效果。第一个架构(顶部)是第 4 节中描述的前端。它执行没有结构化预测情况下的语义分割,类似于 Long 等人(2015)的原始工作。第二种架构(表 3,中间)使用密集 CRF 来执行结构化预测,类似于 Chen 等人(2015a)的系统。我们使用 Krahenb ¨ uhl & Koltun(2011)的实现,并通过在验证集上进行网格搜索来训练 CRF 参数。第三种架构(表 3,底部)使用 CRF-RNN 进行结构化预测(Zheng 等人,2015 年)。我们使用 Zheng 等人(2015)的实现并在每种 条件下训练 CRF-RNN。
实验结果表明上下文模块提高了三种配置中每一种的准确性。基本上下文模块提高了每个配置的准确性。大上下文模块大幅提高了准确性。实验表明上下文模块和结构化预测是协同的:上下文模块在有或没有后续结构化预测的情况下提高准确性。定性结果如图 3 所示。

在测试集上的评估。我们现在通过将结果提交给 Pascal VOC 2012 评估服务器来对测试集进行评估。结果报告在表 4 中。我们使用大型上下文模块进行这些实验。正如结果所示,上下文模块在前端的准确度上有显着提升。单独的上下文模块,没有后续的结构化预测,优于 DeepLab-CRF-COCO-LargeFOV(Chen et al, 2015a)。具有密集 CRF 的上下文模块,使用 Krahenb ¨ uhl & Koltun(2011)的原始实现,与最近的 CRF-RNN(Zheng et al, 2015)表现不相上下。上下文模块与 CRF-RNN 相结合,进一步提高了 CRF-RNN 性能的准确性。
6. 结论
我们已经检查了用于密集预测的卷积网络架构。由于模型必须产生高分辨率输出,我们认为在整个网络中进行高分辨率操作既可行又可取。我们的工作表明,扩张卷积运算符特别适合密集预测,因为它能够在不损失分辨率或覆盖范围的情况下扩展感受野。我们利用扩张卷积设计了一种新的网络结构,当插入现有的语义分割系统时,它可以可靠地提高准确性。作为这项工作的一部分,我们还表明,通过移除为图像分类开发的残留组件,可以提高现有用于语义分割的卷积网络的准确性。
我们认为,所提出的工作是朝着不受图像分类前体约束的密集预测专用架构迈出的一步。随着新数据源的出现,未来的架构可能会进行端到端的密集训练,从而不再需要对图像分类数据集进行预训练。这可以实现架构的简化和统一。具体来说,端到端密集训练可以使类似于所呈现的上下文网络的完全密集架构能够始终以全分辨率运行,接受原始图像作为输入,并以全分辨率生成密集标签分配作为输出。
最先进的语义分割系统为未来的发展留下了巨大的空间。图 4 显示了我们最准确配置的失败案例。我们将发布我们的代码和经过训练的模型以支持该领域的进展。

参考文献
Badrinarayanan, Vijay, Handa, Ankur, and Cipolla, Roberto. SegNet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv:1505.07293, 2015.
Brostow, Gabriel J., Fauqueur, Julien, and Cipolla, Roberto. Semantic object classes in video: A high-definition ground truth database. Pattern Recognition Letters, 30(2), 2009.
Chen, Liang-Chieh, Papandreou, George, Kokkinos, Iasonas, Murphy, Kevin, and Yuille, Alan L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015a.
Chen, Liang-Chieh, Yang, Yi, Wang, Jiang, Xu, Wei, and Yuille, Alan L. Attention to scale: Scale-aware semantic image segmentation. arXiv:1511.03339, 2015b.
Cordts, Marius, Omran, Mohamed, Ramos, Sebastian, Rehfeld, Timo, Enzweiler, Markus, Benenson, Rodrigo, Franke, Uwe, Roth, Stefan, and Schiele, Bernt. The Cityscapes dataset for semantic urban scene understanding. In CVPR, 2016.
Everingham, Mark, Gool, Luc J. Van, Williams, Christopher K. I., Winn, John M., and Zisserman, Andrew. The Pascal visual object classes (VOC) challenge. IJCV, 88(2), 2010.
Farabet, Clement, Couprie, Camille, Najman, Laurent, and LeCun, Yann. Learning hierarchical features for ´ scene labeling. PAMI, 35(8), 2013.
Fischer, Philipp, Dosovitskiy, Alexey, Ilg, Eddy, Hausser, Philip, Hazrba, Caner, Golkov, Vladimir, van der ¨ Smagt, Patrick, Cremers, Daniel, and Brox, Thomas. Learning optical flow with convolutional neural networks. In ICCV, 2015.
Galleguillos, Carolina and Belongie, Serge J. Context based object categorization: A critical survey. Computer Vision and Image Understanding, 114(6), 2010.
Geiger, Andreas, Lenz, Philip, Stiller, Christoph, and Urtasun, Raquel. Vision meets robotics: The KITTI dataset. International Journal of Robotics Research, 32(11), 2013.
Glorot, Xavier and Bengio, Yoshua. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
Hariharan, Bharath, Arbelaez, Pablo, Bourdev, Lubomir D., Maji, Subhransu, and Malik, Jitendra. Semantic contours from inverse detectors. In ICCV, 2011.
He, Xuming, Zemel, Richard S., and Carreira-Perpin˜an, Miguel ´ ´A. Multiscale conditional random fields for image labeling. In CVPR, 2004.
Holschneider, M., Kronland-Martinet, R., Morlet, J., and Tchamitchian, Ph. A real-time algorithm for signal analysis with the help of the wavelet transform. In Wavelets: Time-Frequency Methods and Phase Space. Proceedings of the International Conference, 1987.
Jia, Yangqing, Shelhamer, Evan, Donahue, Jeff, Karayev, Sergey, Long, Jonathan, Girshick, Ross B., Guadarrama, Sergio, and Darrell, Trevor. Caffe: Convolutional architecture for fast feature embedding. In Proc. ACM Multimedia, 2014.
Kohli, Pushmeet, Ladicky, Lubor, and Torr, Philip H. S. Robust higher order potentials for enforcing label consistency. IJCV, 82(3), 2009.
Krahenb ¨ uhl, Philipp and Koltun, Vladlen. Efficient inference in fully connected CRFs with Gaussian edge ¨ potentials. In NIPS, 2011.
Krizhevsky, Alex, Sutskever, Ilya, and Hinton, Geoffrey E. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
Kundu, Abhijit, Vineet, Vibhav, and Koltun, Vladlen. Feature space optimization for semantic video segmentation. In CVPR, 2016.
Ladicky, Lubor, Russell, Christopher, Kohli, Pushmeet, and Torr, Philip H. S. Associative hierarchical CRFs for object class image segmentation. In ICCV, 2009.
Le, Quoc V., Jaitly, Navdeep, and Hinton, Geoffrey E. A simple way to initialize recurrent networks of rectified linear units. arXiv:1504.00941, 2015.
LeCun, Yann, Boser, Bernhard, Denker, John S., Henderson, Donnie, Howard, Richard E., Hubbard, Wayne, and Jackel, Lawrence D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4), 1989.
Lin, Guosheng, Shen, Chunhua, Reid, Ian, and van dan Hengel, Anton. Efficient piecewise training of deep structured models for semantic segmentation. arXiv:1504.01013, 2015.
Lin, Tsung-Yi, Maire, Michael, Belongie, Serge, Hays, James, Perona, Pietro, Ramanan, Deva, Dollar, Piotr, ´ and Zitnick, C. Lawrence. Microsoft COCO: Common objects in context. In ECCV, 2014.
Liu, Buyu and He, Xuming. Multiclass semantic video segmentation with object-level active inference. In CVPR, 2015.
Long, Jonathan, Shelhamer, Evan, and Darrell, Trevor. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
Noh, Hyeonwoo, Hong, Seunghoon, and Han, Bohyung. Learning deconvolution network for semantic segmentation. In ICCV, 2015.
Ros, German, Ramos, Sebastian, Granados, Manuel, Bakhtiary, Amir, V ´ azquez, David, and L ´ opez, Anto- ´ nio Manuel. Vision-based offline-online perception paradigm for autonomous driving. In WACV, 2015.
Rumelhart, David E., Hinton, Geoffrey E., and Williams, Ronald J. Learning representations by backpropagating errors. Nature, 323, 1986.
Shensa, Mark J. The discrete wavelet transform: wedding the a trous and Mallat algorithms. ` IEEE Transactions on Signal Processing, 40(10), 1992.
Shotton, Jamie, Winn, John M., Rother, Carsten, and Criminisi, Antonio. TextonBoost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. IJCV, 81 (1), 2009.
Simonyan, Karen and Zisserman, Andrew. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
Sturgess, Paul, Alahari, Karteek, Ladicky, Lubor, and Torr, Philip H. S. Combining appearance and structure from motion features for road scene understanding. In BMVC, 2009.
Tighe, Joseph and Lazebnik, Svetlana. Superparsing – scalable nonparametric image parsing with superpixels. IJCV, 101(2), 2013.
Zheng, Shuai, Jayasumana, Sadeep, Romera-Paredes, Bernardino, Vineet, Vibhav, Su, Zhizhong, Du, Dalong, Huang, Chang, and Torr, Philip. Conditional random fields as recurrent neural networks. In ICCV, 2015.
附录 A 城市场景理解
在本附录中,我们报告了三个用于城市场景理解的数据集的实验:CamVid 数据集(Brostow et al, 2009)、KITTI 数据集(Geiger et al, 2013)和新的 Cityscapes 数据集(Cordts et al, 2016)。作为精度度量,我们使用平均 IoU(Everingham et al, 2010)。我们只在训练集上训练我们的模型,即使验证集可用。本节报告的结果不使用条件随机场或其他形式的结构化预测。它们是通过结合了前端模块和上下文模块的卷积网络获得的,类似于表 3 中评估的 “Front + Basic” 网络。经过训练的模型可以在 https://github.com/fyu/dilation 找到。
我们现在总结用于训练前端模块的训练程序。此过程适用于所有数据集。使用随机梯度下降进行训练。每个小批量包含 8 个来自随机采样图像的作物。每个作物的大小为 628×628,并从填充图像中随机采样。使用反射填充填充图像。中间层不使用填充。学习率为 10−4,动量设置为 0.99。迭代次数取决于数据集中的图像数量,并在下面为每个数据集报告。
用于这些数据集的上下文模块均来自 “Basic” 网络,使用表 1 中的术语。每层中的通道数是预测类 C C C 的数量。(例如,Cityscapes 数据集的 C = 19 C=19 C=19)上下文模块中的每一层都被填充,使得输入和响应映射具有相同的大小。上下文模块中的层数取决于数据集中图像的分辨率。下面针对每个数据集总结了由前端和上下文模块组成的完整模型的联合训练。
A.1 CAMVID
我们使用 Sturgess 等人(2009)的拆分,将数据集划分为 367 个训练图像、100 个验证图像和 233 个测试图像。使用了 11 个语义类。图像被下采样到 640×480。
上下文模块有 8 层,类似于本文正文中用于 Pascal VOC 数据集的模型。整体训练流程如下。首先,对前端模块进行 20K 次迭代训练。然后完整的模型(前端 + 上下文)由大小为 852 × 852 且批大小为 1 的采样联合训练。联合训练的学习率设置为 10−5,动量设置为 0.9。
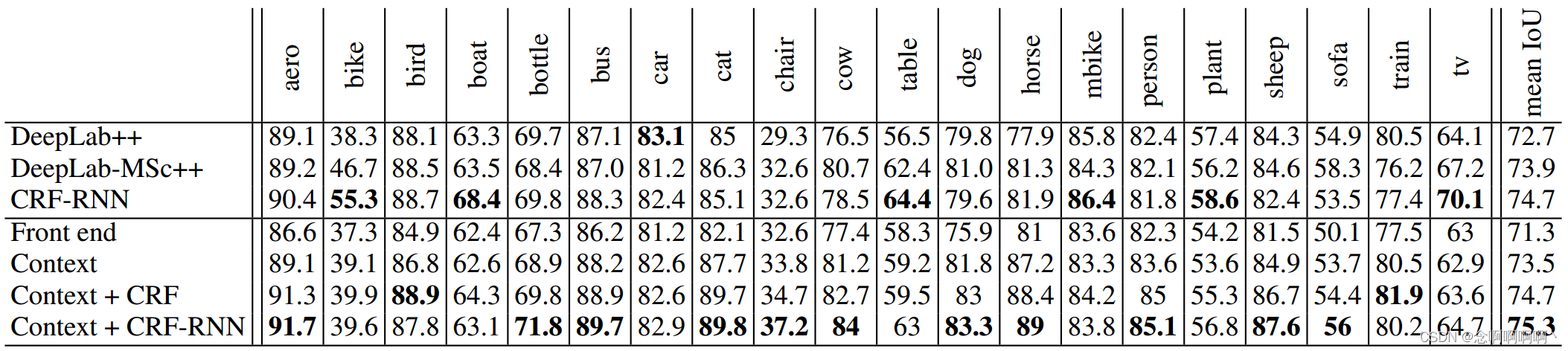
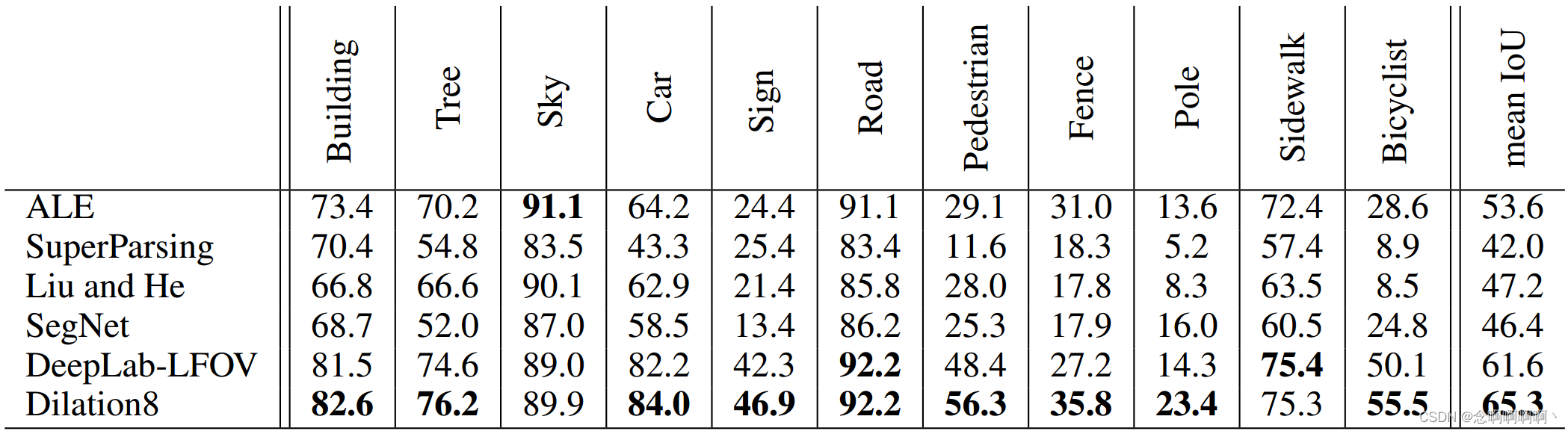
表 5 报告了 CamVid 测试集的结果。我们将完整的卷积网络(前端 + 上下文)称为 Dilation8,因为上下文模块有 8 层。我们的模型优于之前的工作。该模型在 Kundu 等人(2016)最近的工作中被用作一元分类器。
A.2 KITTI
我们使用 Ros 等人(2015)的训练和验证拆分:100 张训练图像和 46 张测试图像。这些图像都是从 KITTI visual odometry / SLAM 数据集中收集的。图像分辨率为1226×370。由于与其他数据集相比垂直分辨率较小,我们删除了表 1 中的第 6 层。生成的上下文模块有 7 层。完整的网络(前端 + 上下文)称为 Dilation7。
前端经过 10K 次迭代训练。接下来,前端和上下文模块联合训练。对于联合训练,裁剪大小为 900×900,动量设置为 0.99,而其他参数与 CamVid 数据集使用的参数相同。联合训练进行了 20K 次迭代。
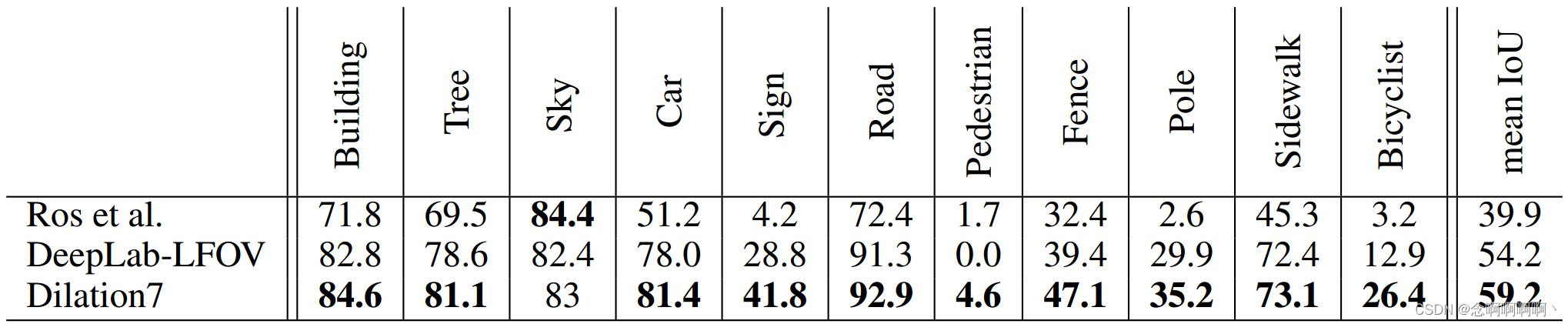
结果如表 6 所示。如表所示,我们的模型优于之前的工作。
A.3 CITYSCAPES
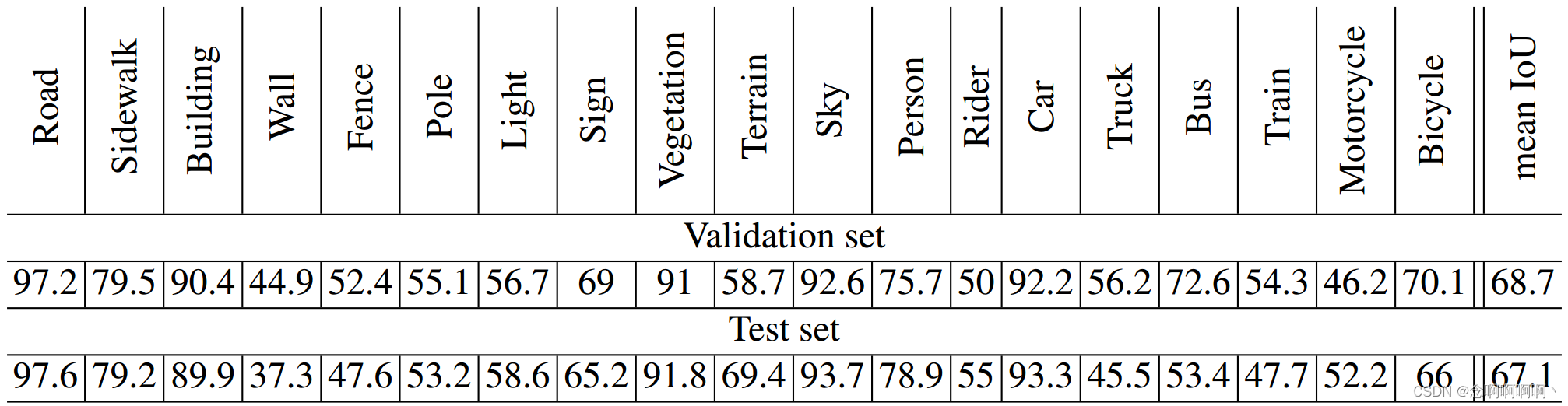
Cityscapes 数据集包含 2975 张训练图像、500 张验证图像和 1525 张测试图像(Cordts et al, 2016)。由于图像分辨率高(2048×1024),我们在表 1 中的第 6 层之后向上下文网络添加了两层。这两层的膨胀分别为 32 和 64。上下文模块中的总层数为 10,我们将完整模型(前端 + 上下文)称为 Dilation10。
Dilation10 网络分三个阶段进行训练。首先,对前端预测模块进行了 40K 次迭代训练。其次,上下文模块在整个(未裁剪)图像上进行了 24K 次迭代训练,学习率为 10−4,动量为 0.99,批量大小为 100。第三,完整模型(前端 + 上下文)联合训练了 60K 次迭代 在一半图像上(输入大小 1396×1396,包括填充),学习率为 10−5,动量为 0.99,批量大小为 1。
图 5 可视化了训练阶段对模型性能的影响。表 7 和表 8 给出了定量结果。
Cordts 等人(2016)将 Dilation10 的性能与之前在 Cityscapes 数据集上的工作进行了比较。在他们的评估中,Dilation10 优于所有先前的模型(Cordts et al, 2016)。Dilation10 在 Kundu 等人(2016)最近的工作中也被用作一元分类器,它使用结构化预测来进一步提高准确性。