
简介
这是社会网络管理与分析的作业。老师要求每组各举一个小世界网络的例子。因为以前刚好下载过武汉公交路线的数据,因此我们组讲的是这个示例。
小世界网络的定义和性质可以参考wiki百科:小世界网络
如果一个网络满足:
- 其平均聚集系数远大于在同一个顶点集合中构造的随机图的平均聚集系数;
- 并且,其平均最短路径长度和这个随机图基本相同
那么这个网络便可以称为小世界网络。
公交信息通过百度地图API获取,包括公交路线的坐标的经纬度坐标(可以生成GIS中的线要素),每个公交站点的经纬度坐标和名称。武汉公交站点的名称基本上都是以该站点所在街道开头命名,很有规律,例如建设大道双墩,解放大道中山公园等,这为数据处理和网络分析提供了很大方便。
将真实的地理路网映射到抽象的网络有好几种方法,每种方法都有一定的优缺点。这里用到的方法类似于路名对偶法,将一条道路作为网络中的结点,道路与道路的交叉路口作为相连的边。如下图所示。
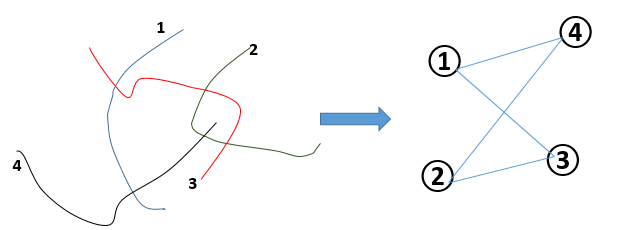
但是手头上的数据只是公交路网的数据,毕竟和真实的道路交通网络还有差别,而且身边缺少一些工具,因此采用了简化的路名对偶法来映射公交道路网络。当然这样的映射会造成一些问题。
公交路网映射方法
基本上,武汉公交站点名称的前缀都是该站点所在道路名称,且该名称都是以道、路、街结尾,因此用这三个字将每条公交路线的站点名称截断,得到该公交路线经过的街道名称,然后再删除重复的道路名称。
映射时基于如下假设:在同一条公交线路中,相邻的两条道路必是相连的。因此遍历所有公交线路的所有站点,按顺序将公交线路中的站点两两相连。这样就将公交路网映射到了网络图中。
但是这样简化的映射方法会产生一些问题:
- 无法完全反应真实的道路信息
- 会产生一个非连通图(因为道路交通网应该是一个连通图)
在这个作业中通过取网络图中结点最多的连通子图来解决。
数据处理
python的网络分析库Networkx功能强大好用。因为python对中文支持不太好,所以用anjuke库将结点名称全部转为拼音。Networkx可以从这里下载:Networkx
Networkx的基本操作如下:
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph() # 定义一个图
vertex1 = 1 # 结点可以是字符串,也可以是数字
vertex2 = 2
G.add_node(vertex1) # 添加一个结点
G.add_node(vertex2)
G.add_edge(vertex1, vertex2) # 以vertex1和vertex2为顶点添加一条边
# 绘制网络,使用spring布局,结点大小设置为10,透明度设置为0.6
nx.draw_networkx_nodes(G,pos=nx.spring_layout(G), nodesize = 10, alpha = 0.6)
plt.show() # 使用matplot将图绘制出来全部的处理代码如下:
# _*_ coding: utf-8 _*_
import networkx as nx
import codecs
from anjuke import pinyin #汉字转拼音
import matplotlib.pyplot as plt
originalPath = "StationName_distinct_utf.txt" # 去除重复项的中文顶点文件
pinyinPath = "StationName_distinct_pinyin.txt" # 去除重复项的拼音顶点文件
NameNoPath = "StationNameNo_distinct.txt" # 公交路线和站点名称文件,中文
# 汉字转拼音
def ConvertPinyin(originalPath, pinyinPath):
fileOriginal = codecs.open(originalPath, "r", "utf-8")
fileNodes_pinyin = open(pinyinPath, "w")
fileOriginal.seek(0,0)
line = fileOriginal.readline()
converter = pinyin.Converter()
while line:
name = converter.convert(line)
fileNodes_pinyin.write(name)
print name
line = fileOriginal.readline()
fileOriginal.close()
fileNodes_pinyin.close()
# 存储格式:每一行都是一个站点名
def CreateNodes(originalPath):
fileOriginal = codecs.open(originalPath, "r", "utf-8")
fileOriginal.seek(0,0)
vertex = fileOriginal.readline()
vertex = vertex.strip()
while vertex:
G.add_node(vertex)
vertex = fileOriginal.readline()
fileOriginal.close()
# 根据公车的行使特征,每两个相邻的站点的道路应该是相连的,当然也有不相连的,这里简化了
# 存储格式:第一列为公交编号,第二列为站名(去除重复项),tab符分隔
def CreateEdges(originalPath):
fileOriginal = codecs.open(originalPath, "r", "utf-8")
fileOriginal.seek(0,0)
line = fileOriginal.readline()
if line.strip() == "":
return
converter = pinyin.Converter() # 转拼音
preBusNo = line.split("\t")[0]
preStopName = line.split("\t")[1]
preStopName = converter.convert(preStopName)
while line:
content = line.split("\t")
curBusNo = content[0]
curStopName = converter.convert(content[1]) # 转拼音
if preBusNo == curBusNo: # 同一条路线
if preStopName != curStopName: # 若相邻的两条路不同,则他们相连,有交点,构成一条边
G.add_edge(preStopName, curStopName)
#print preStopName + "----" + curStopName
preStopName = curStopName
else: # 若不是同一条路线
preBusNo = curBusNo
preStopName = curStopName
line = fileOriginal.readline()
fileOriginal.close()
#创建一个图
G = nx.Graph()
#ConvertPinyin(originalPath, pinyinPath)
CreateNodes(originalPath)
CreateEdges(NameNoPath)
print nx.number_of_nodes(G) #输出图的顶点数
print nx.number_of_edges(G) #输出图的边数
print nx.number_connected_components(G) #输出图的连通子图数量
lst = list(nx.connected_component_subgraphs(G)) #提取图中所有连通子图,返回一个列表,默认按照结点数量由大到小排序
H = lst[0] #取顶点数最多连通子图来分析
print nx.number_of_nodes(H)
print nx.number_of_edges(H)
print nx.average_shortest_path_length(H) #计算平均最短路径长度
print nx.average_clustering(H) #计算平均聚集系数
nx.draw_networkx_nodes(H,pos=nx.spring_layout(H), nodesize = 10, alpha = 0.6) #使用spring绘制图
plt.show()
#plt.savefig("path.png")结果与分析
最后得到的网络共有476个结点,941条边。即,一共有476条路,941个交叉路口。原始的非连通图有900多个结点。如下图所示。

然后通过Networkx计算了该网络的平均最短路径长度和平均聚集系数。
平均最短路径长度:5.454
平局聚集系数:0.195
平均最短路径长度表示任意选择两条路,坐公交车的话平均要经过大概5个路口就可以到达。小世界网络中,平均最短路径长度要远远小于结点数。而平均聚集系数要远远大于同一个顶点集合的随机图的平均聚集系数。下面用WS网络模型来验证。
WS模型是用来解释小世界网络的一个模型,1998年由瓦茨和斯特罗加茨提出。WS模型基于一个假设:小世界模型是介于规则网络和随机网络之间的一个网络。因此模型从一个完全规则的网络出发,以一定的概率将网络中的连接打乱重连。作业中使用Networkx生成了WS网络模型。概率p分别设为0.1(接近规则网络),0.4和0.9(接近随机网络)。每个结点的平均邻居设为5。python代码如下:
import networkx as nx
import matplotlib.pyplot as plt
# 生成一个WS网络,结点数476,平均邻居数为5,概率p为0.9
WS = nx.random_graphs.watts_strogatz_graph(476, 5, 0.9)
print nx.average_shortest_path_length(WS) #计算平均最短路径长度
print nx.average_clustering(WS) #计算平均聚集系数
nx.draw_networkx(WS,pos=nx.spring_layout(WS),nodesize = 10, width = 0.8, with_labels = False, node_color = 'b', alpha = 0.6)
plt.show()结果图如下。
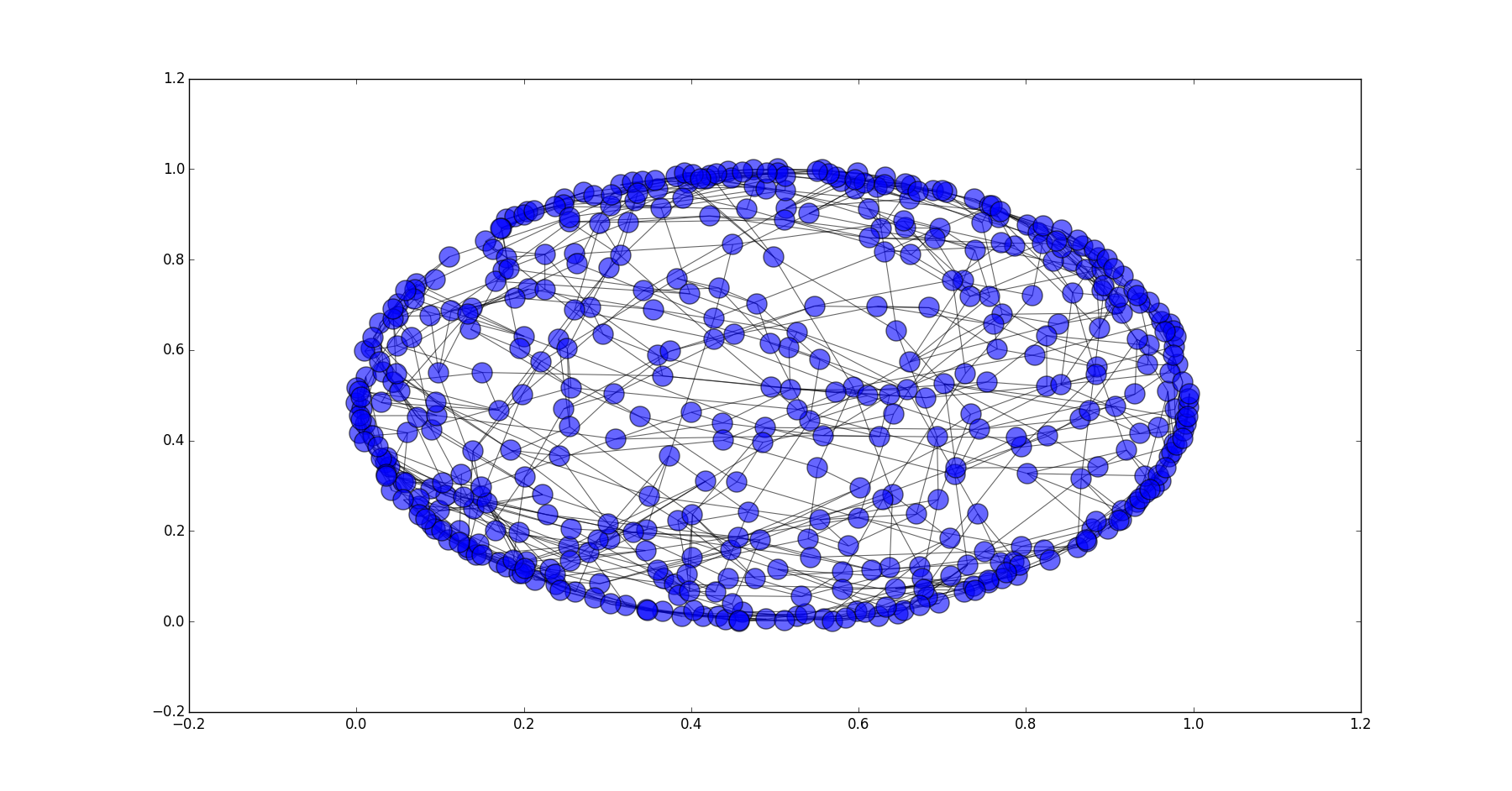
p=0.1时的WS网络
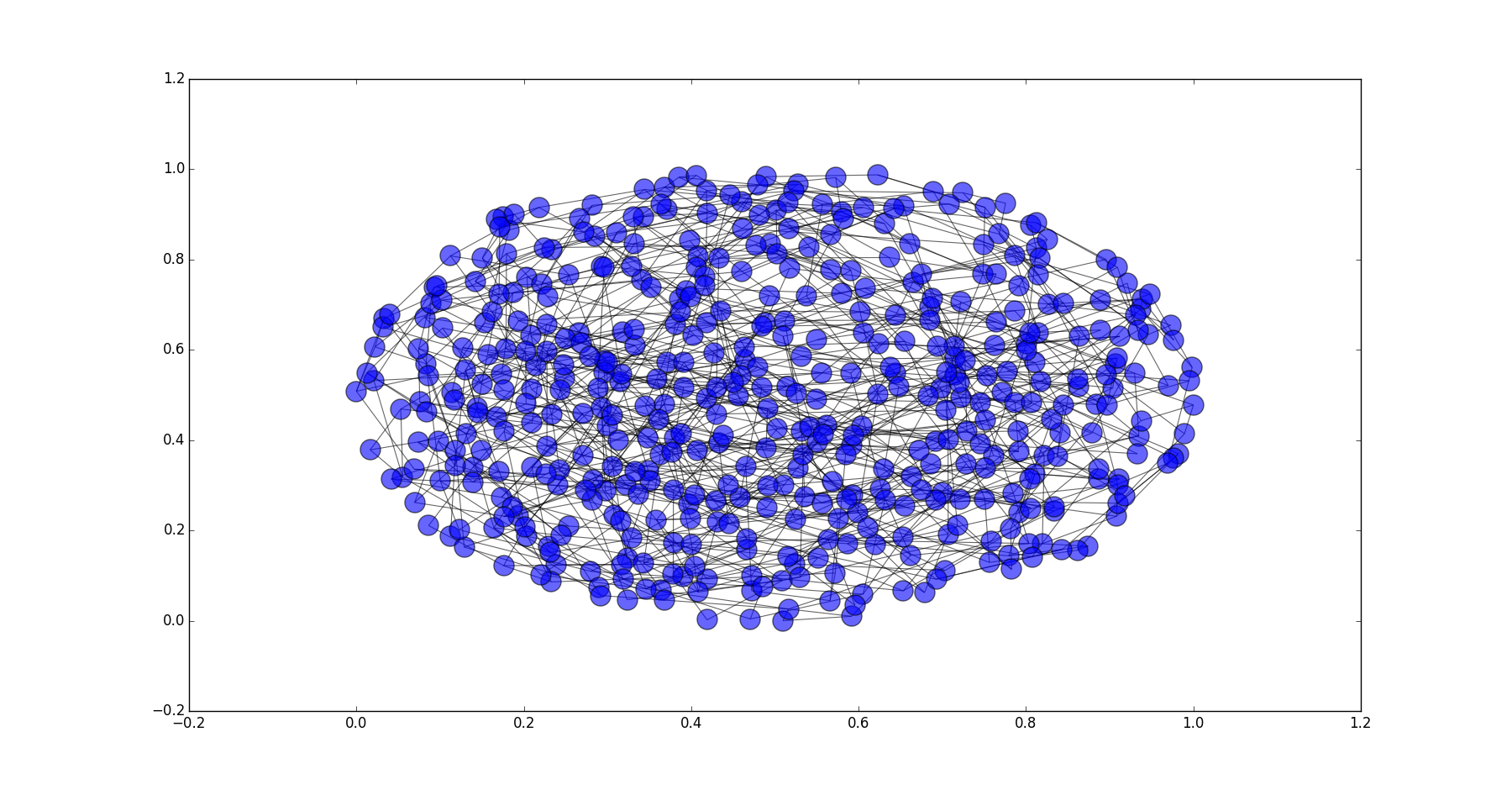
p=0.4时的WS网络
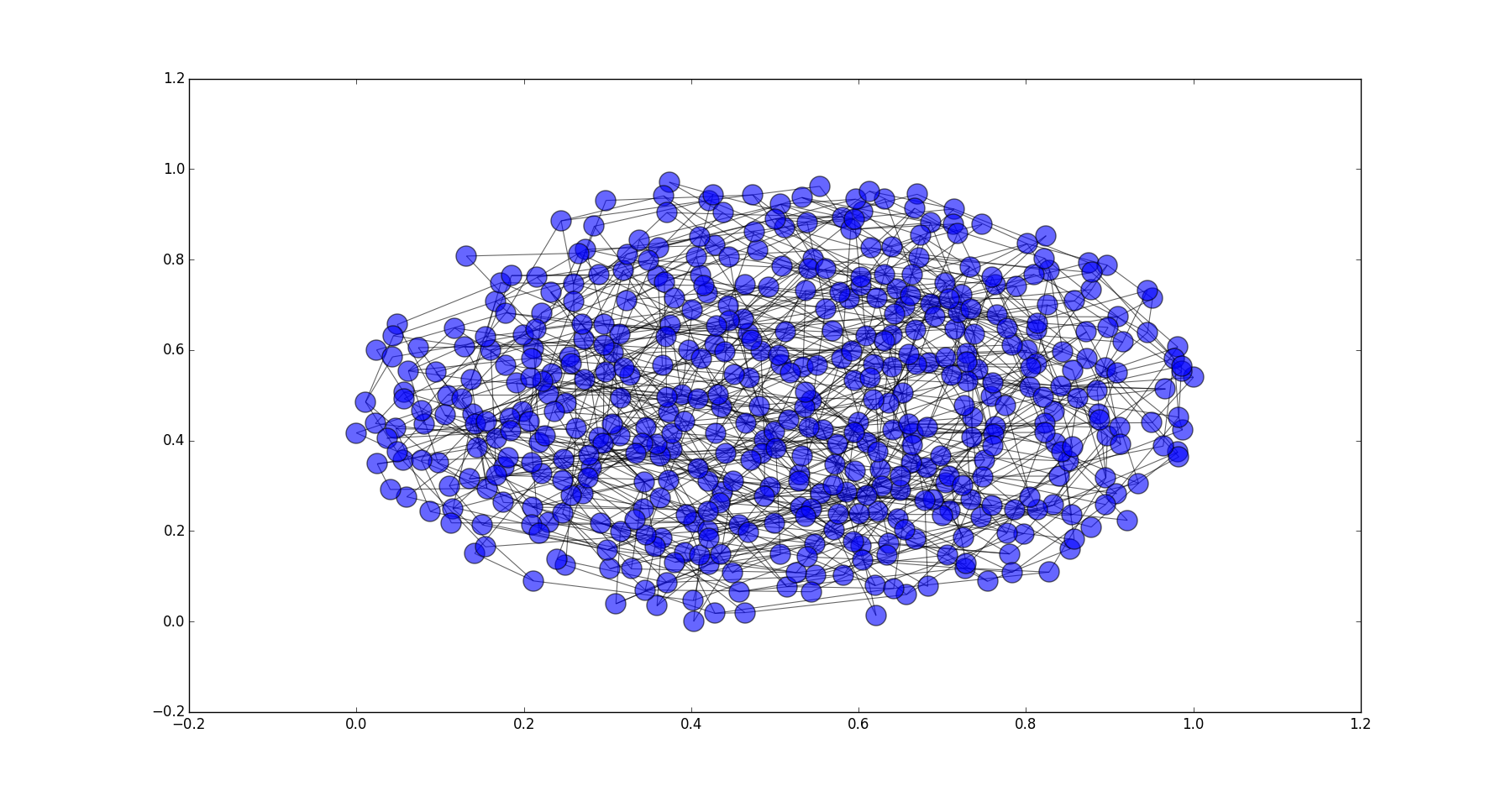
p=0.9时的WS网络
三种概率的WS网络和武汉公交网络的平均最短路径长度和平均聚集系数如下:
| 项目 | 公交路网 | WS(p=0.1) | WS(p=0.4) | WS(p=0.9) |
|---|---|---|---|---|
| 平均最短路径长度 | 5.454 | 7.66 | 5.080 | 4.745 |
| 平均聚集系数 | 0.195 | 0.378 | 0.105 | 0.006 |
可以看到当p=0.4时的WS网络和武汉公交路网的指标接近。而当p=0.4的网络的平均最短路径长度与p=0.9(随机网络)的WS网络相当,但平均聚集系数要大于p=0.9的WS网络。符合前面提到的小世界网络特征。而武汉公交路网的指标也与p=0.4的WS网络相当,因此公交路网也符合小世界网络的特征。