



安装graphviz用于可视化决策树
apt-get install graphviz
from sklearn.tree import DecisionTreeClassifier
import pydotplus
from sklearn import tree
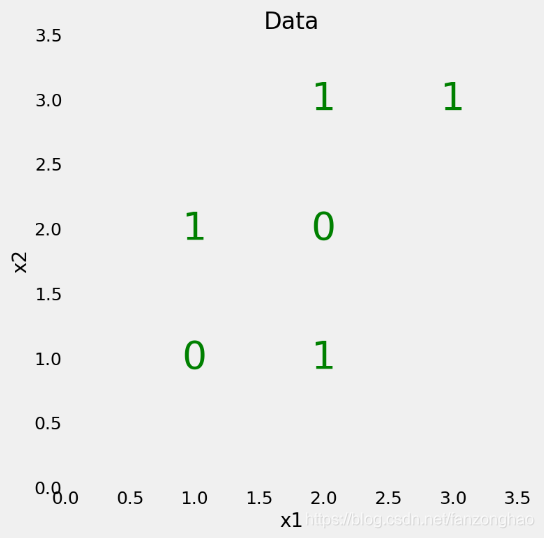
X = np.array([[2, 2],
[2, 1],
[2, 3],
[1, 2],
[1, 1],
[3, 3]])
y = np.array([0, 1, 1, 1, 0, 1])
plt.style.use('fivethirtyeight')
plt.rcParams['font.size'] = 18
plt.figure(figsize=(8, 8))
# Plot each point as the label
for x1, x2, label in zip(X[:, 0], X[:, 1], y):
plt.text(x1, x2, str(label), fontsize=40, color='g',
ha='center', va='center')
plt.grid(None)
plt.xlim((0, 3.5))
plt.ylim((0, 3.5))
plt.xlabel('x1', size=20)
plt.ylabel('x2', size=20)
plt.title('Data', size=24)
# plt.show()
dec_tree = DecisionTreeClassifier()
print(dec_tree)
dec_tree.fit(X, y)
print(dec_tree.score(X,y))
# Export as dot
dot_data = tree.export_graphviz(dec_tree, out_file=None,
feature_names=['x1', 'x2'],
class_names=['0', '1'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
with open('1.png', 'wb') as f:
f.write(graph.create_png())

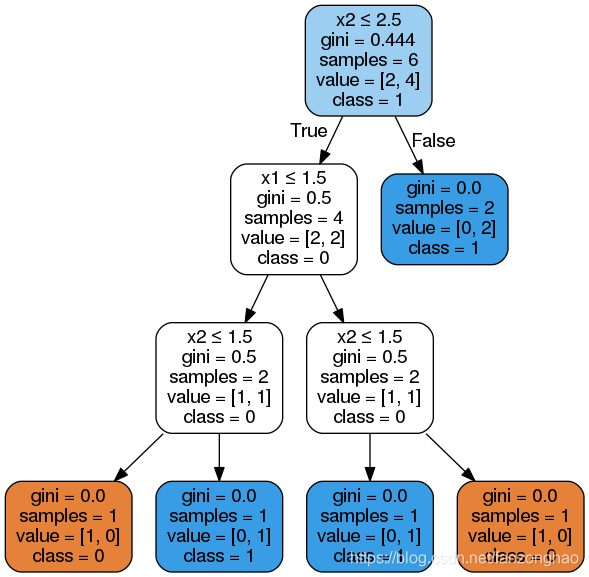
除叶节点(终端节点)之外的所有节点都有 5 部分:
-
基于一个特征的值的有关数据的问题。每个问题的答案要么是 True,要么就是 False。数据点会根据该问题的答案在该决策树中移动。
-
gini:节点的基尼不纯度。当沿着树向下移动时,平均加权的基尼不纯度必须降低。
-
samples:节点中观察的数量。
-
value:每一类别中样本的数量。比如,顶部节点中有 2 个样本属于类别 0,有 4 个样本属于类别 1。
-
class:节点中大多数点的类别(持平时默认为 0)。在叶节点中,这是该节点中所有样本的预测结果。
一个节点的基尼不纯度的公式为:
root节点的计算:
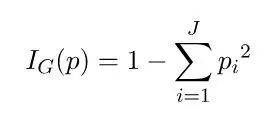
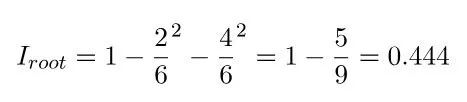
在这个决策树的第二层,最左边的节点的基尼不纯度为 0.5,这似乎表明不纯度增大了。但是,每一层应该降低的是基尼不纯度的加权平均。每个节点都会根据其样本占父节点样本的比例进行加权。所以整体而言,第二层的基尼不纯度为:
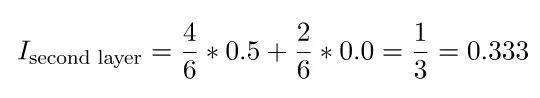
在最后一层,每个节点的基尼不纯度都会达到 0.0,这说明每个节点都只包含单一类别的样本。这符合我们的预期,因为我们并没有限制决策树的深度,让其可以按需要创建足够多的层以能分类所有数据点。尽管我们的模型能正确分类所有的训练数据点,但这并不意味着它就是完美的,因为它与训练数据可能过拟合了。
二,决策树案例2
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
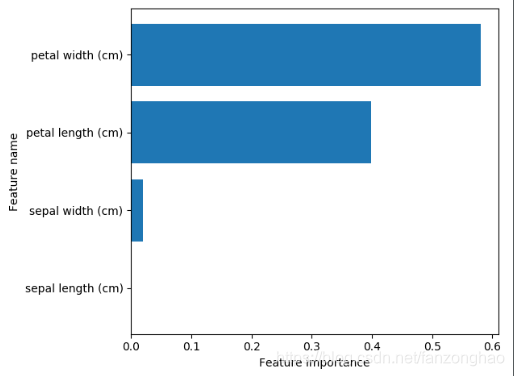
def plot_feature_importances(clf, feature_names):
"""
可视化分类器中特征的重要性
"""
c_features = len(feature_names)
plt.barh(range(c_features), clf.feature_importances_)
plt.xlabel('Feature importance')
plt.ylabel('Feature name')
plt.yticks(np.arange(c_features), feature_names)
plt.show()
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
max_depth_values = [2, 3, 4]
for max_depth_val in max_depth_values:
dt_model = DecisionTreeClassifier(max_depth=max_depth_val)
dt_model.fit(X_train, y_train)
print('max_depth=', max_depth_val)
print('训练集上的准确率: {:.3f}'.format(dt_model.score(X_train, y_train)))
print('测试集的准确率: {:.3f}'.format(dt_model.score(X_test, y_test)))
print()
dt_model = DecisionTreeClassifier(max_depth=4)
dt_model.fit(X_train, y_train)
print(iris.feature_names)
print(dt_model.feature_importances_)
plot_feature_importances(dt_model, iris.feature_names)
随机森林
随机森林是由许多决策树构成的模型。这不仅仅是森林,而且是随机的,这涉及到两个概念:
1.随机采样数据点
2.基于特征的子集分割节点
随机采样
随机森林的一大关键是每个树都在随机的数据点样本上进行训练。这些样本是可重复地抽取出来的(称为 bootstrapping),也就是说某些样本会多次用于单个树的训练(如果有需要,也可以禁止这种做法)。其思路是,通过在不同样本上训练每个树,尽管每个树依据训练数据的某个特定子集而可能有较高方差,但整体而言整个森林的方差会很低。这种在数据的不同子集上训练每个单个学习器然后再求预测结果的平均的流程被称为 bagging,这是 bootstrap aggregating 的缩写。
特征的随机子集
随机森林背后的另一个概念是:在每个决策树中,分割每个节点时都只会考虑所有特征中的一个子集。通常设定为 sqrt(n_features),意思是在每个节点,决策树会基于一部分特征来考虑分割,这部分特征的数量为总特征数量的平方根。随机森林也可以在每个节点考虑所有特征来进行训练。(在 Scikit-Learn 随机森林实现中,这些选项是可调控的。)随机森林组合了数百或数千个决策树,并会在稍有不同的观察集上训练每个决策树(数据点是可重复地抽取出来的),并且会根据限定数量的特征分割每个树中的节点。随机森林的最终预测结果是每个单个树的预测结果的平均。