1.产生的背景
对于大量的海量数据的批处理,传统上使用的hadoop、hive等,优点是吞吐量大、自动容错的特点,但是同时缺点也十分的明显,只适合一些离线的数据处理,对于一些实时数据处理并不擅长,由此产生的Storm、SparkStreaming、Fink等实时的计算系统。
2.简介
Apache Storm 是一个Twitter的开源分布式、实时、可扩展、容错的操作系统。Strom处理数据非常的快,每秒可以处理超过百万的数据组。
Storm的应用场景:实时分析、在线机器学习、持续计算、分布式RPC、ETL等。
特点:快、可扩展、容错性、保证数据能够被处理。
官网: http://storm.apache.org/
下载:http://storm.apache.org/downloads.html
文档:http://storm.apache.org/releases/1.2.2/index.html
3.Apache Storm的集群架构群

解释说明:
Apache Storm:分布式集群主要节点由控制节点(nimbus节点)和工作节点(Supervisor),控制节点可以一个,工作节点可以多个组成,而Zookeeper主要负责nimbus节点和Supervisor工作节点的协调工作。
Nimbus节点负责资源分配和任务分配,通过Zookeeper监控Supervisor的状态,Supervisor节点定期接受Nimbus节点分配任务,
并从Nimbus下载代码,并启动对应的Worker进程监控worker的状态,每一个worker是一个独立的JVM进程,Worker中运行Spout/Bolt线程Task任务,Storm使用zookeeper来协调整个集群,状态信息(Nimbus分布的任务、Supervisor、worker的心跳等)都保存在Zookeeper上。
Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有的Worker,一个Supervisor节点中包含多个Worker进程。
Worker:进程,每一个Worker都是一个以独立的JVM进程,进程里面会包含一个或者多个executor线程,一个executor会处理一个或者多个Task任务。Config.TOPOLOGY_WORKERS 设置worker数量。
Task:任务,在Storm中每一个Spout/Bolt对应多个Task任务执行,每一个任务都与一个线程相应,Spout/Bolt设置多个并行度(setSpout/setBolt),就有对应的多个Task,Spout的 netTuole()或者Bolt的 execute()会被执行。
Zookeeper:Storm集群的信息状态都保存在Zookeeper上,通过Zookeeper分布式协调系统来管理Storm的稳定性。
4.Apache Storm的设计思想
Apache Storm是一个开源分布式、实时计算应用,实时计算应用它是由Topology、Stream、Spout、Bolt、Stream grouping等元素组成的。
由此:


开发步骤:
1.构建TopologyBuilder对象
2.通过设置Spout和Bolt来构建Topology对应的DAG.
3.使用TopologyBuilder对象创建StormTopology对象
4.本地创建LocalCluster对象,集群的直接使用StormSubmitter.submitTopology()来提交第三步创建的Topology对象余下的就通过我们填空进行补充即可。
注意:
1.创建的TopologyName在一个Storm集群中必须要唯一
2.创建的在一个topology中的各个组件(spout或者bolt)的id必须要唯一
3.Topology中 各组件id的名称最好不要以_或者_开头,因为这是一些系统保留的命名方式。
关于Vaules的说明:
Vaules的多个值,代表的多列的内容,必须要在declare方法中做一一对应的声明。
解释说明核心抽象:Topology和Stream
Storm的Topology是一个分布式的实时计算应用、计算拓扑,Storm的拓扑的对实时应用计算的应用的逻辑封装,他的作用于MapReduce的任务job相似,区别是job运行之后会结束,而Topology会在集群内一直运行,直到手动终止, storm kill topology-name。
一个Topology是Spouts和Bolts组成的图状结构,而链接Spout和Bolt的则是Stream Groupings。
运行一个拓扑只要把代码打包一个 jar,然后在storm集群环境下,执行命令storm jar topology-jar-path class.....
拓扑运行模式:本地模式和分布式模式
1.本地模式:
LocalCluster localcluster =new LocalCluster();
Localcluster.submitTopology("WcTopo",config.builder.createTopology());
Localcluster.shutdown();
2.集群模式:
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
Streams 是storm最核心的抽象概念,一个Stream是分布式环境中并行创建和处理的一个没有边界的tuple序列Stream是由Tuple支持的类型有IntegerLong、Short、Byte、Double、Float、Boolean、Byte Arrays 当然Tuple也支持可序列化的对象。
数据流可以由一种能够表达数据流元组的域的模式来定义。
Tuple是数据流中的一个基本处理单元,包含了多个Filed和对应的值,可以理解为key-value的map,因为Bolt通过declareOutputFields 事先定义好往下传的字段名称,所以在 构建Tuple时,只要传入对应的value。
- declareOutputFields 事先定义好往下传的字段名称
/**
* 定义数据流的字段名称和顺序
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word"));
}
2、然后通过emit 发送结果数据
/**
- 该方法就是接受到一行字符串,然后按照空格切割成多个单词
- 每个单词都通过 outputCollector 往外发送给下一个处理单元
*/
@Override
public void execute(Tuple tuple) {
String line = tuple.getStringByField("line"); String[] words = line.trim().split(" "); for(String word : words){
this.outputCollector.emit(new Values(word));
}
}
Spouts 数据源
数据源(spout)是拓扑中数据流的来源,Spout是拓扑的数据流 的源头,Spout不断的从外部读取数据(数据库、kafka等外部资源),拓扑中进行实时的处理。
Spout是主动模式,Spout继承BaseRichSpout 或者实现IRchSpout接口不断的调用netTuple()函数,然后通过emit发送数据流。
参数说明:
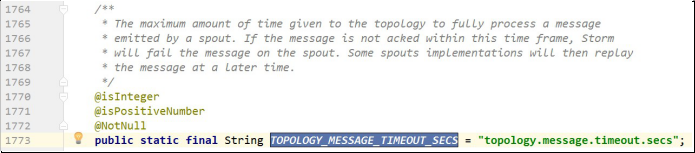
1.Config.TOPOLOGY_MESSAGE_TIME_SECS:Y一个Tuple元组全部完成的最大等待时间,默认是30秒。
2.Config.TOPOLOGY_MAX_SPOUT_PENDING:设置一次等候单个spout任务的元组最大的数量(等候意味着这元组没有被acked或者fail),设置这个值可以防止益处。
Bolts
Bolt接收Spout或者上游的Bolt发来的Tuple(数据流),拓扑中所有的数据处理均由Bolt完成的。
通过数据过滤(filter)函数处理(function)聚合( aggregations)联结(joins)数据库交互等工能。Bolt几乎能够完成任何一种数据需求,一个Bolt可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个Bolt并通过多个步骤完成。
Bolt 是被动模式,Bolt 继承 BaseBasicBolt 类或者实现 IRichBolt 接口等来实现,当 Bolt 接收Spout 或者上游的 Bolt 发来的 Tuple(数据流)时调用 execute 方法,并对数据流进行处理完, OutputCollector 的 emit 发送数据流,execute 方法在Bolt 中负责接收数据流和发送数据流。
Stream Grouping
Storm 是通过 Stream Grouping 把 spouts 和 Bolts 串联起来组成了流数据处理结构。为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。
Storm 对 Stream groupings 定义了 8 种数据流分组方式:
- Shuffle grouping(随机分组):对 Tuple(数据流)随机的分发到下一个 bolt 的Tasks(任务),每个任务同等机会获取Tuple,保证了集群的负载均衡。
- Fields grouping(字段分组):对指定的字段对数据流进行分组,相同的字段对应的数据流都会交给同个 bolt 中 Task 来处理,不同的字段的数据流会分发到不同的Task 来处理。
3、Partial Key grouping(部分字段分组):按字段进行分组,这种跟 Fields grouping 很相似,但这种方式会考虑下游 Bolt 数据处理的均衡性问题,会提供更好的资源利用。
4、All grouping(完全分组):Tuple(数据流)会被同时的发送到下一个 bolt 中的所有 Task(任务)。这种会导致网络传输量很大,慎重使用。
5、Global grouping(全局分组):Tuple(数据流)会被发送到下一个 Bolt 的 Id 最小的 Task(任务)。
6、None grouping(无分组):使用这种方式说明你不关心数据流如何分组。目前这种方式的结果与随机分组完全等效,不过未来可能会考虑通过非分组方式来让 Bolt 和它所订阅的Spout 或 Bolt 在同一个线程中执行。
7、Direct grouping(直接分组):通过 OutputCollector emitDirect 方法指定下一个 bolt 的具体
Task 来处理。
8、Local or shuffle grouping(本地或随机分组):如果目标 Bolt 有一个或更多的任务在相同的 Worker 进程中,Tuple 就发送给这些 Task,否则 Tuple 会被随机分发(跟Shuffle grouping 一样)
Reliability 可靠性
Storm 为了保证 Spout 发送的 Tuple 能够成功的处理,通过 Tuple 树跟踪每个Tuple 是否被成功的处理。Storm 有配置一个 Tuple 元组全部完成的最大等待时间,如果超过这个时间,就默认这个Tuple 失败,重新发送 Tuple。通过这种机制保证了 Tuple 的可靠性。可以参考官方文档对数据处理说明.
5.Apache Strom
1、安装ZooKeeper
详见安装 ZooKeeper 的文档
2、下载 Storm 安装包下载:
http://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.2.2/apache-storm- 1.2.2.tar.gz
3、上传安装包到集群服务器put c:/apache-storm-1.2.2.tar.gz
4、解压缩到安装目录
tar -zxvf /home/hadoop/apache-storm-1.2.2.tar.gz -C ~/apps/
5.修改配置文件
[hdp01@hdp01 conf]$ cd /home/hadoop/apps/apache-storm-1.2.2/conf
[hdp01@hdp01 conf]$ ll total 16
-rw-r--r-- 1 hadoop hadoop 1128 Feb 17 04:21 storm_env.ini
-rwxr-xr-x 1 hadoop hadoop 930 Feb 17 04:21 storm-env.ps1
-rwxr-xr-x 1 hadoop hadoop 947 Feb 17 04:21 storm-env.sh-rw-r--r-- 1 hadoop hadoop 3945 May 7 11:16 storm.yaml [hadoop@hadoop05 conf]$ vim storm.yaml
增加以下几行数据:
配置zookeeper节点
storm.zookeeper.servers:
- "hadoop02"
- "hadoop03"
- "hadoop04"
配置nimbus的主节点
nimbus.seeds: ["hadoop03", "hadoop04"]
配置strom的本地存储jar路径
storm.local.dir: "/home/hdp01/apps/apache-storm-1.0.2/local-tmp"
表示supervisor最多可以几个进程
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
注意格式 参数解释:
storm.zookeeper.servers 表示 storm 集群依赖的 zookeeper
nimbus.seeds 表示 storm 集群的主节点的主机名,用来做准备切换的
Hdp01@hdp01]vi storm-env.sh
增加2行即可:
export JAVA_HOME=/home/hdp01/apps/jdk1.8.0_73
export STORM_CONF_DIR="/home/hdp01/apps/apache-storm-1.0.2/conf"
6、分发安装包
[hadoop@hadoop05 ~]$ scp -r apache-storm-1.2.2/ hadoop02:$PWD [hadoop@hadoop05 ~]$ scp -r apache-storm-1.2.2/ hadoop03:$PWD
7、配置环境变量
export STORM_HOME=/home/hadoop/apps/apache-storm-1.2.2 export PATH=$PATH:$STORM_HOME/bin
- 启动
Hdp01@hdp01] nohuo apps/apache-storm-1.2.2/bin/strom nimbus >/dev/null 2>&1 &
Hdp01@hdp01] nohuo apps/apache-storm-1.2.2/bin/strom ui >/dev/null 2>&1 &
Hdp01@hdp02] nohuo apps/apache-storm-1.2.2/bin/strom nimbus >/dev/null 2>&1 &
Hdp01@hdp02] nohuo apps/apache-storm-1.2.2/bin/strom supervisor >/dev/null 2>&1 &
Hdp01@hdp02] nohuo apps/apache-storm-1.2.2/bin/strom logviewer >/dev/null 2>&1 &
Hdp01@hdp03] nohuo apps/apache-storm-1.2.2/bin/strom supervisor >/dev/null 2>&1 &
Hdp01@hdp03] nohuo apps/apache-storm-1.2.2/bin/strom supervisor >/dev/null 2>&1 &
Hdp01@hdp03] nohuo apps/apache-storm-1.2.2/bin/strom logviewer >/dev/null 2>&1 &
