十四、Storm
14.1 DAG
-
理解有向无环图Directed Acyclic Graph(DAG)
- DAG是一个没有 有向循环的、有限的有向图 。
- 它由有限个顶点和有向边组成,每条有向边都从一个顶点指向另一个顶点;
- 从任意一个顶点出发都不能通过这些有向边回到原来的顶点。
- 有向无环图就是从一个图中的任何一点出发,不管走过多少个分叉路口,都没有回到原来这个点的可能性。
-
条件
- 每个顶点出现且只出现一次
- 若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
-
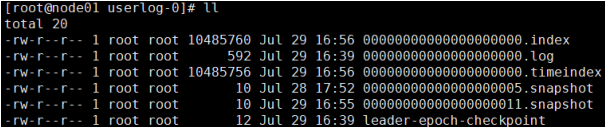
计算一个DAG的拓扑关系
- 1→4表示4的入度+1,4是1的邻接点
- 首先将边与边的关系确定,建立好入度表和邻接表。
- 从入度为0的点开始删除,如上图显然是1的入度为0,先删除。
- 判断有无环的方法,对入度数组遍历,如果有的点入度不为0,则表明有环。
- { 1, 2, 4, 3, 5 }
-
弊端
- 双花
- 影子链
14.2 Storm介绍
14.2.1 Storm的简介

-
介绍
-
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop
- 随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流
-
按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义
- Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和高效。同样,Storm也为实时计算提供了一些简单高效的原语,而且Storm的Trident是基于Storm原语更高级的抽象框架,类似于基于Hadoop的Pig框架,让开发更加便利和高效
-
-
应用场景
- 实时分析,在线机器学习,连续计算,分布式RPC,ETL等等
- 推荐系统(实时推荐,根据下单或加入购物车推荐相关商品)、金融系统、预警系统、网站统计(实时销量、流量统计,如淘宝双11效果图)、交通路况实时系统等等
- 流数据处理,Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去。
- 分布式rpc,由于storm的处理组件是分布式的,而且处理延迟极低,所以可以作为一个通用的分布式rpc框架来使用。
- 持续计算,任务一次初始化,一直运行,除非你手动kill它
-
Storm集群和Hadoop集群的比较
- Storm 集群和hodoop集群看起来类似,但是hadoop上运行的是mapreduce jobs ,而在storm上运行的是拓扑topology ,两者之前的区别是mapreduce jobs 运行完程序(离线数据)之后会结束,而topology不会结束(实时数据),除非手动kill,或者出现异常。
-
Storm案例之WordCount
- storm任务从数据源每次读取一个完整的英文句子;将这个句子分解为独立的单词,最后,实时的输出每个单词以及它出现过的次数
14.2.2 Storm的优点
- 可靠性
- Storm 实现的一些特征决定了它的性能和可靠性的,Storm 使用 Netty 传送消息,这就消除了中间的排队过程,使得消息能够直接在任务自身之间流动,在消息的背后,是一种用于序列化和反序列化Storm 的原语类型的自动化且高效的机制
- 容错性
- Storm 的一个最有趣的地方是它注重容错和管理,Storm 实现了有保障的消息处理,所以每个元组(Turple)都会通过该拓扑(Topology)结构进行全面处理;
- 故障检测
- 如果一个元组还未处理会自动从Spout处重发,Storm 还实现了任务级的故障检测,在一个任务发生故障时,消息会自动重新分配以快速重新开始处理
14.2.3 Storm的特性
- 适用场景广泛
- storm可以实时处理消息和更新DB,对一个数据量进行持续的查询并返回客户端(持续计算)
- 对一个耗资源的查询作实时并行化的处理(分布式方法调用,即DRPC),storm的这些基础API可以满足大量的场景
- 可伸缩性高:
- Storm的可伸缩性可以让storm每秒可以处理的消息量达到很高。
- Storm使用ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展。
- 保证无数据丢失:
- 实时系统必须保证所有的数据被成功的处理。storm保证每一条消息都会被处理。
- 异常健壮:
- storm集群非常容易管理,轮流重启节点不影响应用。
- 容错性好:
- 在消息处理过程中出现异常, storm会进行重试
- 语言无关性:
- Storm的topology和消息处理组件(Bolt)可以用任何语言来定义, 这一点使得任何人都可以使用storm.
14.3 Storm的物理架构
-
Storm架构原理
- 与Hadoop主从架构一样,Storm也采用Master/Slave体系结构,分布式计算由Nimbus和Supervisor两类服务进程实现,Nimbus进程运行在集群的主节点,负责任务的指派和分发,Supervisor运行在集群的从节点,负责执行任务的具体部分,架构图如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cel0Reao-1657548136348)(https://typora-js.oss-cn-shanghai.aliyuncs.com/imgs/2022/07/11/20220711172527)]
-
Storm架构和Hadoop架构的比较
结构 Hadoop Storm 主节点 JobTracker Nimbus 从节点 TaskTracker Supervisor 应用程序 Job Topology 工作进程名称 Child Worker 计算模型 Map / Reduce Spout / Bolt
14.3.1 nimbus
- 理解
- Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
- 集群的主节点,对整个集群的资源使用情况进行管理
- 但是nimbus是一个无状态的节点,所有的一切都存储在Zookeeper
14.3.2 supervisor
- 理解
- Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker
- 一个Supervisor节点中包含多个Worker进程。默认是4个
- 一般情况下一个topology对应一个worker
14.3.3 woker
- 理解
- 工作进程(Process),每个工作进程中都有多个Task
14.3.4 Task
- 理解
- 在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。
- worker中每一个spout/bolt的线程称为一个task
- 同一个spout/bolt的task可能会共享一个物理线程(Thread),该线程称为executor
14.3.5 Storm的并行机制
-
理解
- Topology由一个或多个Spout/Bolt组件构成。运行中的Topology由一个或多个Supervisor节点中的Worker构成
-
组件关系
- Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor.slots.ports数量;
- 默认情况下一个Supervisor节点运行4个Worker,由defaults.yaml/storm.yaml中的属性决定:
- supervisor.slots.ports:6700 6701 6702 6703
- 在代码中可以使用new Config().setNumWorkers(3),最大数量不能超过配置的supervisor.slots.ports数量。
- 默认情况下一个Supervisor节点运行4个Worker,由defaults.yaml/storm.yaml中的属性决定:
- worker:工作进程,即jvm.为特定拓扑的一个或者多个组件Spout/Bolt产生一个或者多个Executor。默认情况下一个Worker运行一个Executor
- Executor:线程Thread,为特定拓扑的一个或者多个组件Spout/Bolt实例运行一个或者多个Task。默认情况下一个Executor运行一个Task。
- Task:任务
- Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor.slots.ports数量;
14.3.6 配置拓扑的并行度
-
配置worker的数量
//注意此参数不能大于supervisor.slots.ports数量。 Config config = new Config(); config.setNumWorkers(3); -
执行器Executor数量
TopologyBuilder builder = new TopologyBuilder(); //设置Spout的Executor数量参数parallelism_hint builder.setSpout(id, spout, parallelism_hint); //设置Bolt的Executor数量参数parallelism_hint builder.setBolt(id, bolt, parallelism_hint); -
任务Task数量
TopologyBuilder builder = new TopologyBuilder(); //设置Spout的Executor数量参数parallelism_hint,Task数量参数val builder.setSpout(id, spout, parallelism_hint).setNumTasks(val); //设置Bolt的Executor数量参数parallelism_hint,Task数量参数val builder.setBolt(id, bolt, parallelism_hint).setNumTasks(val); -
下图的代码如下
//启动Topology Config conf = new Config(); //设置项目需要的进程数 conf.setNumWorkers(2); topologyBuilder.setBolt("Blue", new WordcountBoltLine(), 2); topologyBuilder.setBolt("Green", new WordcountBoltLine(), 2).setNumTasks(4) topologyBuilder.setBolt("Yellow", new WordcountBoltLine(), 6)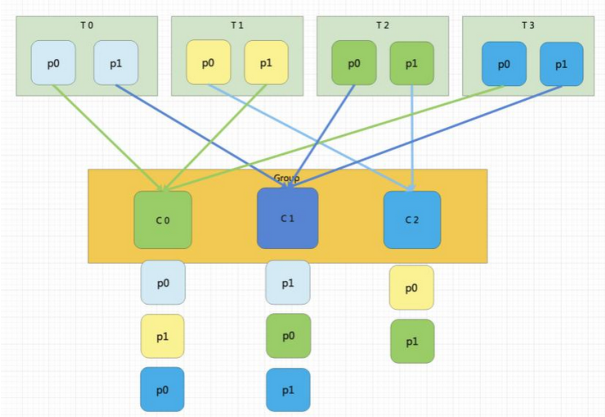
-
设置Storm的worker进程和Executor
Storm一个很好的特性是可以增加或减少工作进程Worker和Executor的数量而不需要重启集群或
拓扑,这样的行为成为再平衡(rebalancing)/* * “myTopology” 拓扑使用5个Worker进程 * “blue-spout” Spout使用3个Executor * “yellow-blot” Bolt使用10个Executor */ storm rebalance myTopology -n 5 -e blue-spout=3 -e yellow-blot=10
14.4 Storm的计算架构
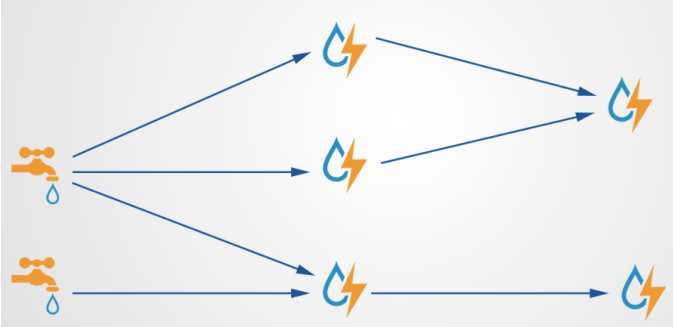
- 流式计算框架
- 客户端将数据发送给MQ(消息队列),然后传递到Storm中进行计算
- 最终计算的结果存储到数据库中(HBase,Mysql)
- 客户端不要求服务器返回结果,客户端可以一直向Storm发送数据
- 客户端相当于生产者,Storm相当于消费者
14.4.1 Topology
-
理解
- 实时应用程序的逻辑被封装在 Storm topology(拓扑)中。Storm topology(拓扑)类似于 MapReduce 作业。
- 两者之间关键的区别是 MapReduce 作业最终会完成, 而 topology(拓扑)任务会永远运行(除 非 kill 掉它)。
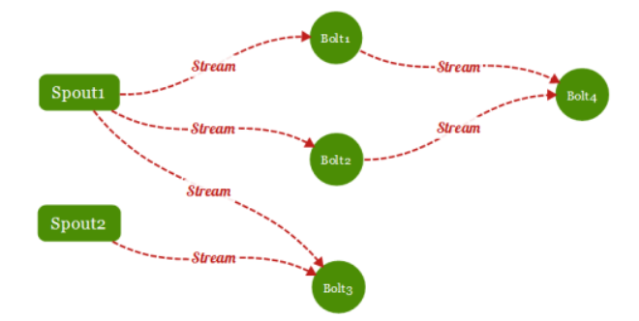
- 一个拓扑是 Spout 和 Bolt 通过 stream groupings连接起 来的有向无环图
- 拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k08DiETU-1657548136357)(https://typora-js.oss-cn-shanghai.aliyuncs.com/imgs/2022/07/11/20220711190029)]
14.4.2 Stream
-
理解
- 数据流(Streams)是 Storm 中最核心的抽象概念。
- 一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。
- 数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义
-
两张图理解Stream
———————————————————————————————————————
其中包含:
-
Spout: Storm中的消息源,用于为Topology生产消息(数据),一般是从外部数据源(如Message
Queue、RDBMS、NoSQL、Realtime Log )不间断地读取数据并发送给Topology消息(tuple元组)。 -
Bolt: Storm中的消息处理者,用于为Topology进行消息的处理,Bolt可以执行过滤,聚合, 查询数据库等操作,而且可以一级一级的进行处理。
14.4.3 Tuple
- 理解
- Stream中最小数据组成单元
- 每个tuple可以包含多列,字段类型可以是: integer, long, short, byte, string, double, float,boolean和byte array
14.4.4 Spout
-
理解
- 数据源(Spout)是拓扑中数据流的来源
- 一个 Spout可以发送多个数据流
-
来源
- 一般spout会从一个外部的数据源读取元组然后将他们发送到拓扑中
-
可靠与不可靠数据源
根据需求不同,spout即可以定义为可靠的数据源,也可以定义为不可靠的数据源
- 一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;
- storm在检测到一个tuple被整个topology成功处理的时候调用ack, 否则调用fail。
- 不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理
- 一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;
14.4.5 Bolt
-
理解
- Bolt用来处理拓扑中所有的数据
- 通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能
-
数据流转
- 一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
- 第一级Bolt的输出可以作为下一级Bolt的输入。而Spout不能有上一级
-
特点
- Bolt 几乎能够完成任何一种数据处理需求。
- Bolts的主要方法是execute(死循环)连续处理传入的tuple,
- 成功处理完每一个tuple调用OutputCollector的ack方法,以通知storm这个tuple被处理完成了。
- 处理失败时,可以调fail方法通知Spout端可以重新发送该tuple。
14.4.6 StreamGroup
- 理解
- 为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。
- 数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
14.4.7 Reliablity
- 可靠性
- Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。
- 通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。
- 每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
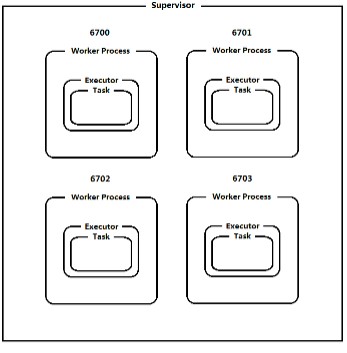
14.4.8 并行元素(Worker、Executor、Task)的关系
一个Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
- Worker(进程)
- Executor(线程)
- Task
下图简要描述了这3者之间的关系:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4YvBCK9y-1657548136360)(https://typora-js.oss-cn-shanghai.aliyuncs.com/imgs/2022/07/11/20220711201148)]
- 1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
- executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
- 一个 task 执行实际的数据处理 - 在您代码中实现的每个 spout 或 bolt 在整个集群上都执行了许多的 task(任 务), 组件的 task(任务)数量在 topology(拓扑)的整个生命周期中总是相同的, 但组件的 executors(线程) 数量可能会随时间而变化。 这意味着以下条件成立: #threads ≤ #tasks. 默认情况下,tasks(任务)数量与 executors(执行器)设置成一样,即1个executor线程只运行1个task。
14.5 Storm的数据分发策略
14.5.1 ShuffleGrouping
-
理解
- 随机分组,随机派发stream里面的tuple,保证每个bolttask接收到的tuple数目大致相同。轮询,平均分配
-
优点
- 为tuple选择task的代价小;
- bolt的tasks之间的负载比较均衡;
-
缺点
- 上下游components之间的逻辑组织关系不明显
14.5.2 FieldsGrouping
-
理解
- 按字段分组
- 比如,按"user-id"这个字段来分组,那么具有同样"user-id"的tuple会被分到相同的Bolt里的一个task,而不同的"user-id"则可能会被分配到不同的task
-
优点
- 上下游components之间的逻辑组织关系显著
-
缺点
- 付出为tuple选择task的代价;
- bolt的tasks之间的负载可能不均衡,根据field字段而定;
14.5.3 AllGrouping
-
理解
- 广播发送,对于每一个tuple,所有的bolts都会收到
-
优点
- 上游事件可以通知下游bolt中所有task;
-
缺点
- tuple消息冗余,对性能有损耗,请谨慎使用;
14.5.4 GlobalGrouping
-
理解
- 全局分组,把tuple分配给taskid最低的task。
-
优点
- 所有上游消息全部汇总,便于合并、统计等
-
缺点
- bolt的tasks之间的负载可能不均衡,id最小的task负载过重;
14.5.5 DirectGrouping
-
理解
- 指向型分组,这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。
- 只有被声明为DirectStream的消息流可以声明这种分组方法。
- 而且这种消息tuple必须使用emitDirect方法来发射。
- 消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)
-
优点
- Topology的可控性强,且组件的各task的负载可控;
-
缺点
- 当实际负载与预估不符时性能削弱
14.5.6 Localorshufflegrouping
-
理解
- 本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的tasks。否则,和普通的ShuffleGrouping行为一致
-
优点
- 相对于ShuffleGrouping,因优先选择同进程task间传输而降低tuple网络传输代价,
- 但因寻找同进程的task而消耗CPU和内存资源,因此应视情况来确定选择
ShuffleGrouping或LocalOrShuffleGrouping;
-
缺点
- 上下游components之间的逻辑组织关系不明显;
14.5.7 NoneGrouping
- 理解
- 不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shufflegrouping是一样的效果。有一点不同的是storm会把使用nonegrouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行(未来Storm如果可能的话会这样设计)
14.5.8 customGrouping
- 理解
- 自定义,相当于mapreduce那里自己去实现一个partition一样。
14.6 Storm高可用集群搭建
14.7 Storm的通信机制
14.7.1 Worker进程间通信原理
-
理解
- worker进程间消息传递机制,消息的接收和处理的流程如下图
-
worker进程
- 为了管理流入和传出的消息,每个worker进程都有一个独立的接收线程和发送线程
- 接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中
- 发送线程负责从worker的transfer-queue中读取消息,并通过网络发送给其他worker
-
executor线程
- 每个executor有独立的incoming-queue 和outgoing-queue
- Worker接收线程将收到的消息通过task编号传递给对应的executor的incoming-queues
- executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue
- 当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中
-
worker进程和executor线程的并发
- 每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数
-
通信技术
- netty:Netty是一个NIO client-server(客户端服务器)框架
- https://blog.csdn.net/qq_28959087/article/details/86501141
14.7.2 Worker进程内通信原理
- Disruptor是一个Queue。
- Disruptor是实现了“队列”的功能,而且是一个有界队列(长度有限)。而队列的应用场景自然就是“生产者-消费者”模型
- Disruptor一种线程之间信息无锁的交换方式
- (使用CAS(Compare And Swap/Set)操作)
- Disruptor主要特点
- 没有竞争=没有锁=非常快。
- 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
- Disruptor 核心技术点
- Disruptor可以看成一个事件监听或消息机制,在队列中一边生产者放入消息,另外一边消费者并行取出处理.
- 底层是单个数据结构:一个ring buffer(环形数据缓冲区)
https://www.cnblogs.com/jony-zhang/p/3817208.html
14.8 Storm的容错机制
14.8.1 集群节点宕机
- Nimbus宕机
单点故障
从1.0.0版本以后,Storm的Nimbus是高可用的。 - 非Nimbus节点
故障时,该节点上所有Task任务都会超时,Nimbus会将这些Task任务重新分配到其他服务器
上运行
14.8.2 进程故障
- Worker
- 每个Worker中包含数个Bolt(或Spout)任务。
- Supervisor负责监控这些任务,当worker失败后会尝试在本机重启它
- 如果启动过程中仍然一直失败,并且无法向Nimbus发送心跳,Nimbus会将该Worker重新分配到其他服务器上
- Supervisor
- 无状态(所有的状态信息都存放在Zookeeper中来管理)
- 快速失败(每当遇到任何异常情况,都会自动毁灭)
- 快速失败(fail-fast)
- 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改)
- 则会抛出Concurrent Modification Exception
- java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改
- 安全失败(fail-safe)
- 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的
- 而是先复制原有集合内容,在拷贝的集合上进行遍历
- java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
- 快速失败(fail-fast)
- Nimbus
- 无状态(所有的状态信息都存放在Zookeeper中来管理)
- 快速失败(每当遇到任何异常情况,都会自动毁灭)
14.8.3 任务级容错
- Bolt任务crash引起的消息未被应答。
此时,acker中所有与此Bolt任务关联的消息都会因为超时而失败,对应的Spout的fail方法将被调用。 - acker任务失败。
如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。Spout的fail方法将被调用。 - Spout任务失败。
在这种情况下,与Spout任务对接的外部设备(如MQ)负责消息的完整性。
14.8.4 消息的完整性
-
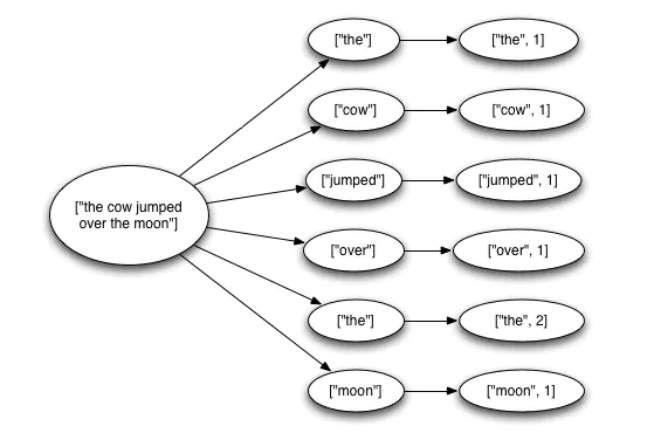
消息的完整性定义
- 每个从Spout(Storm中数据源点)发出的Tuple(Storm中最小的消息单元)可能会生成成千上万个新的Tuple
- 形成一颗Tuple树,当整颗Tuple树的节点都被成功处理了,我们就说从Spout发出的Tuple被完全处理了
-
消息完整性机制–Acker
- acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,
- 如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了
- 相反则会告知spout该消息处理成功了。
-
XOR异或
-
异或的运算法则为:0异或0=0,1异或0=1,0异或1=1,1异或1=0(同为0,异为1)
-
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次
-
验证方式:
- spout或者bolt在处理完tuple后,都会告诉acker我已经处理完了该源tuple(tupleId=1),如果emit一个tuple的话,同时会告诉acker我发射了一个tuple(如tupleId=2),如果在大量的高并发的消息的情况下,传统的在内存中跟踪执行情况的方
式,内存的开销会非常大,甚至内存溢出 - acker巧妙的利用了xor的机制,只需要维护一个msgId的标记位即可,处理方法是acker在初始的时候,对每个msgId初始化一个校验值ack-val(为0),在处理完tuple和emittuple的时候,会先对这两个个值做xor操作,生成的中间值再和acker中的当前校验值ack-val做xor生成新的ack-val值,当所有的tuple都处理完成都得到确认,那么最后的ack-val自然就为0了
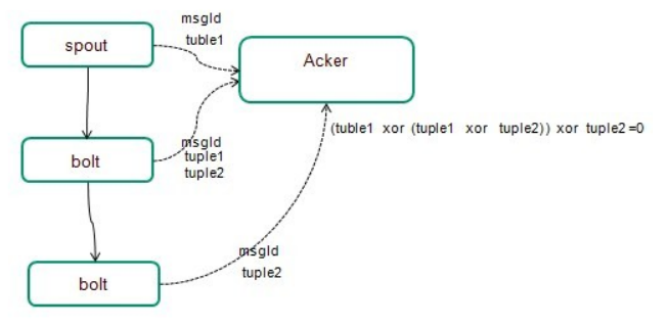
- spout或者bolt在处理完tuple后,都会告诉acker我已经处理完了该源tuple(tupleId=1),如果emit一个tuple的话,同时会告诉acker我发射了一个tuple(如tupleId=2),如果在大量的高并发的消息的情况下,传统的在内存中跟踪执行情况的方
-