安装
1 :解压安装包 tar -zxvf apache-storm-0.9.5.tar.gz
2 :修改配置文件 vi storm/conf/storm.yaml
#指定storm使用的zk集群
storm.zookeeper.servers:
- "hadoop01"
- "hadoop02"
- "hadoop03"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "hadoop01"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx1024m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx768m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
配置文件修改左侧需要保留空格,否则启动报错
3 :分发安装包
scp -r /usr/apps/apache-storm-0.9.5 hadoop02@root:/usr/apps
scp -r /usr/apps/apache-storm-0.9.5 hadoop03@root:/usr/apps
4 :启动集群
在nimbus.host所属的机器上启动 nimbus 服务
一般启动 storm nimbus ; 后台启动 nohup storm nimbus &
在nimbus.host所属的机器上启动 ui 服务
一般启动 storm ui ; 后台启动 nohup storm ui &
在supervisor.host所属的机器上启动 supervisor 服务
一般启动 storm supervisor ; 后台启动 nohup storm supervisor &
4 :查看集群
访问nimbus.host:/8080,即可看到storm的ui界面
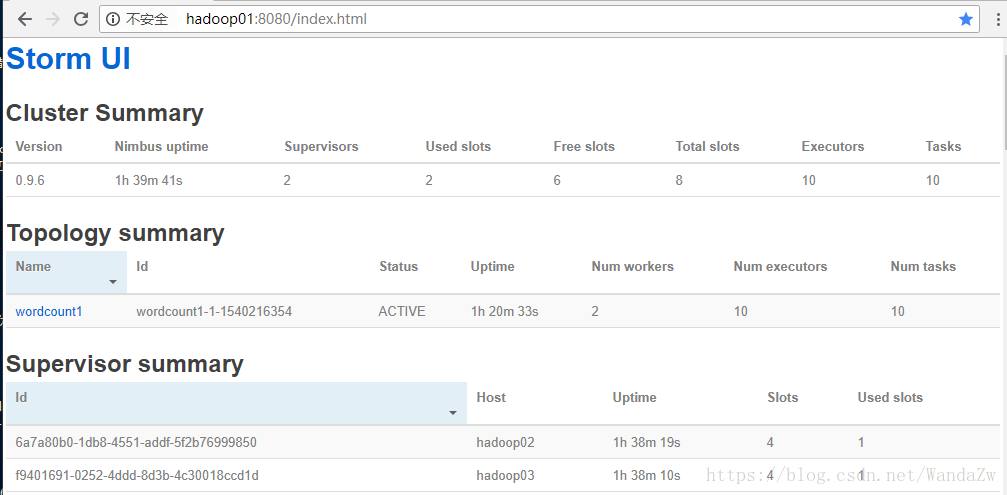
单词统计Demo
1:Spout 文件读取
package cn.itcast.storm;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import org.apache.commons.lang.StringUtils;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class MyLocalFileSpout extends BaseRichSpout {
private SpoutOutputCollector spoutOutputCollector;
private BufferedReader bufferedReader ;
/**
* 初始化方法(被循环调用的方法)
* @param map
* @param topologyContext
* @param spoutOutputCollector
*/
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
try {
this.bufferedReader = new BufferedReader( new FileReader( new File("D:/bigDataJob/wordcount/input/1.txt") ));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
/**
* Storm实时计算的特性就是对数据一条一条的处理
* while(true){ this.nextTuple(); }
*/
@Override
public void nextTuple() {
try {
String line = bufferedReader.readLine();
if(StringUtils.isNotBlank( line )){
//每调用一次就会发送一次数据
List<Object> list = new ArrayList<Object>();
list.add( line );
spoutOutputCollector.emit( list );
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//定义发送的数据是什么
outputFieldsDeclarer.declare( new Fields( "juzi" ));
}
}
2:Bolt 文件切割
package cn.itcast.storm;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class MySplitBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
// 数据如何获取
String juzi = (String) tuple.getValueByField("juzi");
// 进行切割
String[] strings = juzi.split( " " );
// 发送数据
for( String word : strings ){
// Values对象帮我们自动生成list
basicOutputCollector.emit( new Values(word,1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare( new Fields( "word","num" ));
}
}3:Bolt 单词统计
package cn.itcast.storm;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
public class MyWordCountBolt extends BaseBasicBolt {
Map<String,Integer> map = new HashMap<String,Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String word = (String) tuple.getValueByField( "word" );
Integer num = (Integer) tuple.getValueByField( "num" );
Integer integer = map.get( word );
if( integer==null || integer.intValue()==0 ){
map.put( word,num );
}else{
map.put( word ,integer.intValue()+num );
}
System.out.println( map );
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
// 不需要定义输出字段
}
}4:任务提交工具类
package cn.itcast.storm;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
public class StormTopologyDriver {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
//1、准备任务信息
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("mySpout", new MyLocalFileSpout());
topologyBuilder.setBolt("bolt1", new MySplitBolt()).shuffleGrouping("mySpout");
topologyBuilder.setBolt("bolt2", new MyWordCountBolt()).shuffleGrouping("bolt1");
//2、任务提交
//提交给谁?提交什么内容?
Config config = new Config();
//config.setNumWorkers(2);
StormTopology stormTopology = topologyBuilder.createTopology();
// 本地模式
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcount", config, stormTopology);
//集群模式
//StormSubmitter.submitTopology("wordcount1", config, stormTopology);
}
}