**
Homework1:
**
Q1.什么是线性赋范空间?
A1: 线性空间 范数:L0(非0个数) L1(曼哈顿距离) L2(距离)
有向量的加法和数乘满足:
向量加法结合律/交换律/单位元/逆元素
标量乘法分配于向量加法上,分配于域加法,标量乘法一致于标量的域乘法
标量乘法有单位元: 1 v = v
线性赋范空间就是定义了范数的线性空间,所谓范数就是线性空间到数域的一个映射,其满足范数公理(正定性,齐次性,三角不等式),你可以理解为线性空间元素的长度。
Reference: (上交网易公开课)
http://open.163.com/movie/2013/3/T/0/M8PTB0GHI_M8PTBUHT0.html
Q2:计算机中图的定义:
A2:顶点加边 权 度
https://blog.csdn.net/Nicholem/article/details/73425404
Q3:目前哪些激活函数?试着创作一个激活函数
A3: 1、sigmoid
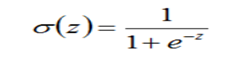
sigmoid函数曲线如下:
sigmoid激活函数,符合实际,当输入值很小时,输出接近于0;当输入值很大时,输出值接近于1。
但sigmoid激活函数有较大的缺点,是主要有两点:
(1)容易引起梯度消失。当输入值很小或很大时,梯度趋向于0,相当于函数曲线左右两端函数导数趋向于0。
(2)非零中心化,会影响梯度下降的动态性。这个可以参考CS231n.
2、tanh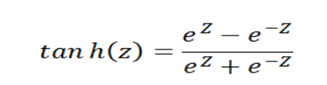
tanh函数曲线如下: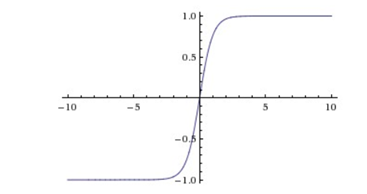
与sigmoid相比,输出至的范围变成了0中心化[-1, 1]。但梯度消失现象依然存在。
3、Relu
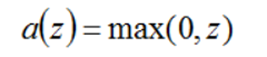
Relu修正线性单元是有许多优点,是目前神经网络中使用最多的激活函数。
函数曲线如下:

优点:(1)不会出现梯度消失,收敛速度快;
(2)前向计算量小,只需要计算max(0, x),不像sigmoid中有指数计算;
(3)反向传播计算快,导数计算简单,无需指数、出发计算;
(4)有些神经元的值为0,使网络具有saprse性质,可减小过拟合。
缺点:(1)比较脆弱,在训练时容易“die”,反向传播中如果一个参数为0,后面的参数就会不更新。使用合适的学习率会减弱这种情况。
4、Leak Relu
Leak Relu是对Relu缺点的改进,当输入值小于0时,输出值为αx,其中α是一个很小的常数。这样在反向传播中就不容易出现“die”的情况。
5.自己构造:
Y= (pi/2)arctanx
在这里插入图片描述
Q4:R^n的紧致子集
A4: 紧集是指拓扑空间内的一类特殊点集,它们的任何开覆盖都有有限子覆盖。从某种意义上,紧集类似于闭集
R^n中的紧集就是有界闭集

Q5:阅读论文《无限逼近理论》
A5: 再任意逼近的前提下,还能逼近。就为无限逼近
https://blog.csdn.net/zhf19891002/article/details/62236605
Q6:把神经网络的输入输出关系表达式描述一下。
A6:
