版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/quanqxj/article/details/77718083
一.解压序列赋值给多个变量
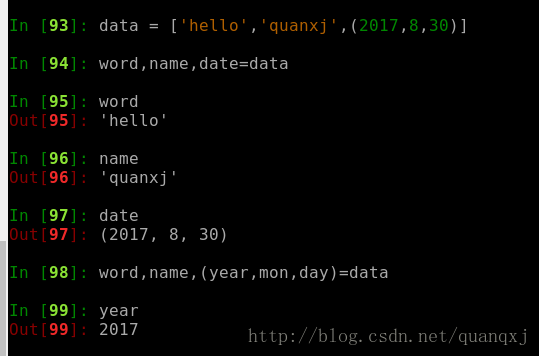
若一个包含 N 个元素的元组或者是序列,将它里面的值解压后同时赋值给 N 个变量解压序列赋值给多个变量:
二.解压可迭代对象赋值给多个变量
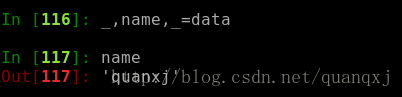
若只解压一部分,可使用变量名占位:
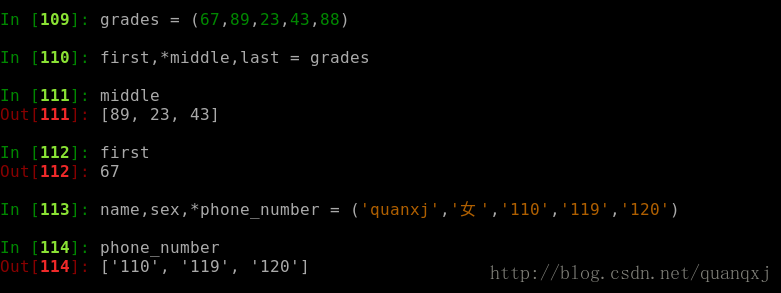
如果一个可迭代对象的元素个数超过变量个数时,通过 * 从可迭代对象中解压出 N 个元素:
扫描二维码关注公众号,回复:
5036580 查看本文章

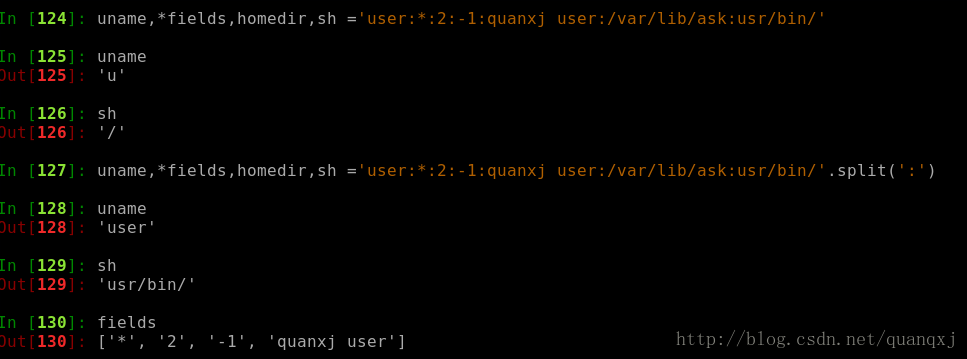
'*' 解压可以应用到字符串的分割:
分割语法实现递归算法:
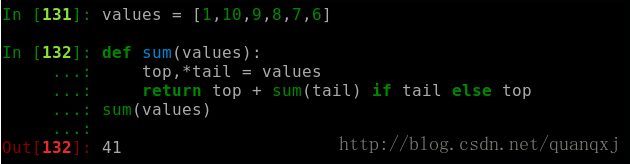
三.保留最后 N 个元素
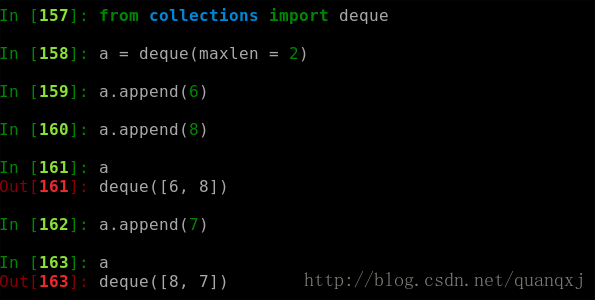
在迭代操作或者其他操作的时候,只保留最后有限几个元素的历史记录,使用 deque(maxlen=N) 构造函数会新建一个固定大小的队列。当新的元素加入并且这个队列已满的时候, 最老的元素会自动被移除掉。
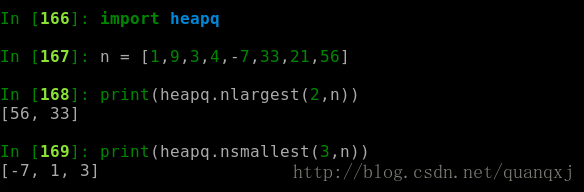
四.查找最大或最小的 N 个元素
从一个集合中获得最大或者最小的 N 个元素列表,可以使用heapq 模块有两个函数:nlargest() 和 nsmallest()
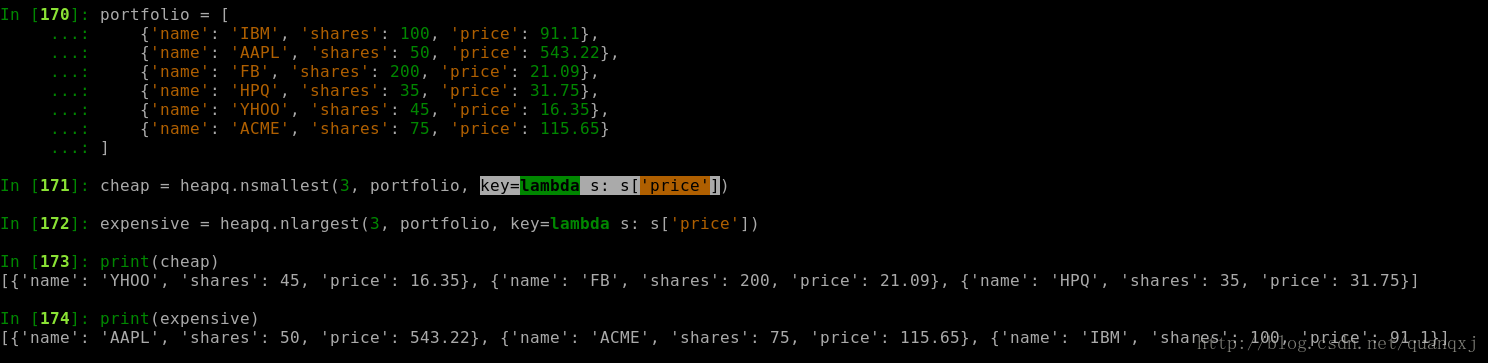
如下复杂函数中,通过指明比较参数,进行比较,以下通过‘price ’比较:
若要查找唯一的最小或最大的元素,那么使用 min() 和 max() 函数,即
min(n)
五.序列中出现次数最多的元素
collections.Counter 类就是专门为这类问题而设计的, 它有一个有用的 most_common() 方法。假设你有一个单词列表并且想找出哪个单词出现频率最高。你可以这样做:
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
]
from collections import Counter
word_counts = Counter(words)
# 出现频率最高的3个单词
top_three = word_counts.most_common(3)
print(top_three)
# Outputs [('eyes', 8), ('the', 5), ('look', 4)]
对于简单的字面模式,直接使用 str.repalce() 方法即可,比如:
>>> text = 'yeah, but no, but yeah, but no, but yeah'
>>> text.replace('yeah', 'yep')
'yep, but no, but yep, but no, but yep'
>>>
对于复杂的模式,请使用 re 模块中的 sub() 函数。 为了说明这个,假设你想将形式为 11/27/2012 的日期字符串改成 2012-11-27 。示例如下:
>>> text = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
>>> import re
>>> re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text)
'Today is 2012-11-27. PyCon starts 2013-3-13.'
>>>
sub() 函数中的第一个参数是被匹配的模式,第二个参数是替换模式。反斜杠数字比如 \3 指向前面模式的捕获组号。