Image-text Retrieval: A Survey on Recent Research and Development
图像文本检索研究进展综述
2022.03
本文已把文献的引用逐个换成相应的论文标题,方便查找和阅读
摘要
本文从四个方面对ITR方法进行了全面和最新的调查。通过将ITR系统剖析为两个过程:特征提取和特征对齐,我们从这两个角度总结了ITR方法的最新进展。在此基础上,对ITR系统的效率研究作为第三个角度进行了介绍。为了与时俱进,我们还从第四个角度对跨模态预训练的ITR方法进行了开创性的概述。最后,我们概述了ITR的通用基准数据集和评估指标,并对有代表性的ITR方法进行了准确性比较。本文最后还讨论了一些关键但研究不多的问题。
1.简介
跨模态图像-文本检索(ITR)是根据给定的用户在一种模态中的表达,从另一模态中检索出相关样本,通常包括两个子任务:图像-文本(i2t)和文本-图像(t2i)检索。ITR在搜索领域具有广泛的应用前景,是一个有价值的研究课题。由于语言和视觉的深度模型的繁荣,在过去的几年里,我们见证了ITR的巨大成功。例如,伴随着BERT的兴起,基于transformer的跨模态预训练范式获得了发展,其预训练-微调的形式被扩展到下游的ITR任务中,加速了其发展。
先前综述局限性: 1)除ITR任务之外,还探讨了其他多模态任务,如视频文本检索和视觉问题回答,导致ITR调查不太深入;2)预训练范式在现有综述中基本没有被开发,它确实是现在的主流。有鉴于此,我们在本文中对ITR任务进行了全面的、最新的调查,特别是对预训练范式进行了综述。
一个ITR系统通常由图像/文本处理分支的特征提取过程和集成模块的特征对齐过程组成。在这样一个ITR系统的背景下,我们从四个角度构建分类法来概述ITR方法。图1显示了ITR方法的分类骨架。
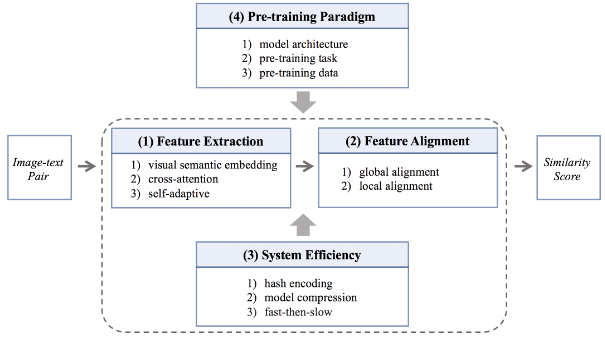
图1:从四个角度说明ITR方法的分类骨架
(1) 特征提取。现有的提取鲁棒性和鉴别性的图像和文本特征的方法分为三类。1)基于视觉语义嵌入的方法致力于独立学习特征。2)与此相反,交叉注意力方法是以交互方式学习特征。3)自适应方法旨在以自适应的模态学习特征。
(2)特征对齐。多模态数据的异质性使得整合模块对于图像和文本特征的对齐非常重要。现有的方法有两种变体。1)全局对齐驱动的方法在各模态间对齐全局特征。2)除此之外,一些方法试图在一个细粒度的层面上明确地找到局部对齐,即所谓的涉及局部对齐的方法。
(3) 系统效率。效率在一个优秀的ITR系统中起着至关重要的作用。除了关于提高ITR准确性的研究外,一系列的工作以三种不同的方式追求高效的检索系统。1)哈希编码方法通过对浮点格式的特征进行二进制化来降低计算成本。2)模型压缩方法强调低能耗和轻量级运行。3)先快后慢的方法通过先粗粒度的快速检索,再细粒度的慢速检索来进行检索。
(4) 预训练范式。为了站在研究发展的前沿,我们还对最近备受关注的ITR任务的跨模态预训练方法进行了深入研究。与传统的ITR相比,预训练的ITR方法可以从大规模跨模态预训练模型隐含的丰富知识中获益,即使没有复杂的检索工程,也能产生令人鼓舞的性能。在ITR任务的背景下,跨模态预训练方法仍然被应用于上述三个角度的分类法。然而,为了更清楚地描述预训练ITR方法的特点,我们从三个维度对它们进行重新分类:模型结构、预训练任务和预训练数据。
接下来,我们将在第二节中总结基于上述前三个角度的分类法的ITR方法,并在第三节中特别提到预训练ITR方法,即第四个角度。第4节详细介绍了常见的数据集、评价指标和代表性方法之间的准确度比较,然后在第5节给出结论和未来工作。
2.图像-文本检索
2.1特征提取
提取图像和文本特征是ITR系统中的第一个也是最关键的过程。如图2所示,在视觉语义嵌入、交叉注意力和自适应这三种不同的发展趋势下,ITR的特征提取技术正在蓬勃发展。
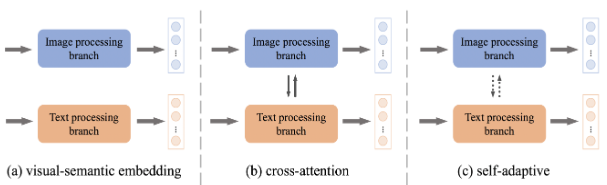
图2:不同特征提取架构的说明
视觉语义嵌入(VSE)。对图像和文本特征进行独立编码是ITR的一种直观和直接的方式。这种基于VSE的方法被广泛开发,大致有两个方面。
1)在数据方面,一系列的工作[Learning fragment self-attention embeddings for image-text matching. In ACM MM, 2019; Probabilistic embeddings for cross-modal retrieval. In CVPR, 2021]试图挖掘高阶数据信息来学习强大的特征。他们在学习特征时对所有的数据对一视同仁。相比之下,一些研究者[Vse++: Improving visual-semantic embeddings with hard negatives. In BMVC, 2017]提出对信息量大的数据对进行加权,以提高特征的辨识度,还有一些研究者[Learning cross-modal retrieval with noisy labels. In CVPR, 2021]更关注数据对中不匹配的噪声对应关系来进行特征提取。最近,乘着大规模跨模态预训练技术的东风,一些作品[Scaling up visual andvision-language representation learning with noisy text su-pervision. InICML, 2021;Wenlan: Bridging vision and language by large-scale multi-modal pre-training, 2021]直接利用大规模网络数据对图像和文本特征提取器进行预训练,在下游的ITR任务中表现出令人印象深刻的性能。
2)关于损失函数,排名损失常用于基于VSE的方法[ deep visual-semantic embedding model. InNeurIPS, 2013;Vse++: Improving visual-semantic embeddings with hard negatives. In BMVC, 2017],并约束了学习特征的模态间数据关系。除此之外,[Learning two-branch neural networks for image-text matching tasks. In TPAMI, 2018.]提出了一种带有邻域约束的最大边际排名损失,以更好地提取特征。[Dualpath convolutional image-text embeddings with instance loss. In TOMM, 2020.]提出了一个明确考虑模态内数据分布的实例损失。
由于独立的特征编码,基于VSE的方法实现了高效的ITR系统,其中大量图库样本的特征可以被离线预计算。然而,由于对图像和文本数据之间的交互探索较少,它可能带来次优的特征和有限的ITR性能。
交叉注意(CA)。[Stacked cross attention for image-text matching. In ECCV, 2018]首次尝试考虑密集的成对跨模态交互,并在当时产生了巨大的准确性改进。此后,人们提出了各种CA方法来提取特征。采用transformer架构,研究者可以简单地对图像和文本的串联进行transformer架构的操作,从而学习跨模态的语境化特征。它开辟了一条丰富的关于类似transformer的CA方法的研究路线[Vilbert: Pretraining task-agnostic visiolin-guistic representations for vision-and-language tasks. In NeurIPS,2019;Uniter: Universal image-text representation learning. In ECCV, 2020]。此外,在交叉注意力中注入一些额外的内容或操作来辅助特征提取也是一个新的研究方向。[Saliency-guided attention network for image-sentence matching. In ICCV, 2019]采用了一个视觉显著性检测模块来指导跨模态关联。[Rosita: Enhancing vision-and-language semantic alignments via cross-and intra-modal knowledge integration. In ACM MM, 2021]整合了模态内和跨模态知识来共同学习图像和文本特征。
CA方法缩小了数据异质性的差距,并倾向于获得高准确率的检索结果,但由于每个图像-文本对都必须在线输入交叉注意力模块,因此成本过高。
自适应(SA)。在基于VSE和CA的方法中,没有固定的计算流程来提取特征,[Dynamic modality interaction modeling for image-text retrieval. In SIGIR, 2021]从头开始,建立了一个自适应的模态交互网络,其中不同的对可以自适应地输入到不同的特征提取机制中。它有力地继承了上述两组方法的各自优点,被归类为SA方法。
2.2特征对齐
在特征提取之后,需要对跨态式的特征进行对齐,以计算成对的相似度,实现检索。全局对齐和局部对齐是两个方向。
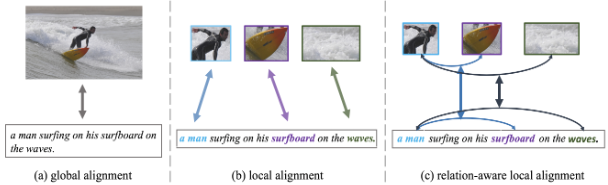
图3:不同特征对齐架构的说明
全局对齐。在全局对齐驱动的方法中,图像和文本从全局角度被匹配,如图3(a)所示。早期的作品[Vse++: Improving visual-semantic embeddings with hard negatives.In BMVC, 2017;Learning two-branch neural networks for image-text matching tasks. In TPAMI, 2018]通常配备了一个清晰简单的双流全局特征学习网络,通过全局特征之间的比较来计算成对的相似度。后来的研究[Adversarial representation learning for text-to-image matching. In ICCV, 2019;Dual-path convolutional image-text embeddings with instance loss. In TOMM, 2020]着重于改进这种双流网络结构,以更好地对齐全局特征。然而,上述仅有全局对齐的方法总是表现出有限的性能,因为文本描述通常包含图像的更细粒度的细节,这很容易被全局对齐所平滑。然而,也有一个例外。最近在预训练-微调范式中的全局对齐方法[Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, 2021]倾向于产生令人满意的结果,这归因于预训练数据规模的扩大。
总而言之,仅将全局对齐应用于ITR可能会导致细粒度对应模型的不足,并且对于计算可靠的成对相似度来说相对较弱。将其他维度的对齐作为全局对齐的补充是一种解决方案。
局部对齐。如图3(b)所示,图像中的区域或patches与句子中的单词相互对应,即所谓的局部对齐。全局对齐和局部对齐构成了ITR的互补解决方案,这是一种流行的选择,被归类为涉及局部对齐的方法。
采用vanilla注意力机制[Stacked cross attention for image-text matching. In ECCV, 2018;Camp: Cross-modal adaptive message passing for text-image retrieval. In ICCV, 2019;Uniter: Universal image-text representation learning. In ECCV, 2020;Vilt: Vision-and-language transformer without convolution or region supervision. In ICML, 2021]是探索语义区域/patch词对应关系的一种琐碎的方法。然而,由于语义的复杂性,这些方法可能不能很好地捕捉最佳的细粒度的对应关系。其一,有选择地关注局部成分是寻找最优局部对齐的一种解决方案。[Focus your attention: A bidirectional focal attention network for image-text matching. In ACM MM, 2019]首次尝试有选择地对齐不同模态的局部语义。[Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In CVPR, 2020]和[context-aware attention network for image-text retrieval. In CVPR, 2020]也不甘落后。前者学会了用一个迭代的局部对齐方案来关联局部成分。后者注意到一个物体或一个词在不同的全局语境下可能有不同的语义,并提出根据全局语境自适应地选择信息丰富的局部组件进行局部对齐。此后,一些与上述目标相同的方法被相继提出,如设计一种对齐引导的掩蔽策略[Kaleido-bert: Vision-language pre-training on fashion domain. In CVPR, 2021]或开发一种注意力过滤技术[Similarity reasoning and filtration for image-text matching. In AAAI, 2021]。另外,全面实现局部对应也是一种近似于最优局部对齐的途径。[Unified visual-semantic embeddings: Bridging vision and language with structured meaning representations. In CVPR,2019]启用了不同层次的文本组件与图像的区域对齐。[Step-wise hierarchical alignment network for image-text matching. In IJCAI, 2021]提出了一个分步的分层对齐网络,实现了局部到局部、全局到局部和全局到全局的对齐。
除此以外,如图3(c)所示,还有另一种类型的局部对齐,即关系感知的局部对齐,可以促进细粒度的对齐。这些方法[Probing inter-modality: Visual parsing with self-attention for vision-and-language pre-training. In NeurIPS, 2021;Multi-modality cross attention network for image and sentence matching. In CVPR, 2020]探索模态内的关系以促进模态间的对齐。此外,一些方法[Visual semantic reasoning for image-text matching. In ICCV, 2019;Ernie-vil: Knowledge enhanced vision-language representations through scene graph. In AAAI, 2021;Similarity reasoning and filtration for image-text matching. In AAAI, 2021]将图像/文本数据建模为图结构,其边缘传达关系信息,并通过图卷积网络推断出与局部和全局对齐的关系感知的相似性。除此之外,[Learning relation alignment for calibrated cross-modal retrieval. In ACL-IJCNLP, 2021]考虑了关系的一致性,即物体之间的视觉关系和文字之间的关系的一致性。
2.3检索效率
将第2.1节的特征提取与第2.2节的特征对齐结合起来,构成一个完整的ITR系统,并关注检索的准确性。除此之外,检索效率是获得一个优秀的ITR系统的关键,从而引发了一系列以效率为重点的ITR方法。
哈希编码。哈希二进制编码在模型的计算和存储上有优势,减轻了人们对ITR的哈希编码方法的日益担忧。这些研究学习将样本的特征映射到一个紧凑的哈希编码空间,以实现高效率的ITR。[Pairwise relationship guided deep hashing for cross-modal retrieval. In AAAI, 2017]同时学习了图像和文本的实值特征和二进制哈希特征,以实现相互之间的受益。[Attention-aware deep adversarial hashing for cross-modal retrieval. In ECCV, 2018]引入了一个注意力模块来寻找被关注的区域和词语,以促使二进制特征学习。除了这些在有监督设置下的方法,无监督的跨模态哈希也是一个关注点。[Self-supervised adversarial hashing networks for cross-modal retrieval. In CVPR,2018]将对抗网络结合无监督的跨模态哈希,以最大限度地提高两种模态之间的语义相关性和一致性。[Deep graph-neighbor coherence preserving network for unsupervised cross-modal hashing. In AAAI,2021]设计了一个图-邻接网络来探索样本的邻接信息,用于无监督哈希学习。哈希编码的方法有利于提高效率,然而也会因为二进制代码的简化特征表示而导致准确率下降。
模型压缩。随着跨模态预训练时代的到来,ITR在准确性方面有了巨大的飞跃,但却牺牲了效率。预训练的ITR方法通常以笨重的网络结构为特征,这就催生了模型压缩方法。一些研究者[Playing lottery tickets with vision and language. In AAAI,2022]引入了lottery ticket hypothesis,以争取更小更轻的网络架构。此外,基于共识,即图像预处理过程在预训练架构中占据了最主要的计算资源消耗,一些研究人员[Pixel-bert: Aligningimage pixels with text by deep multi-modal transformers, 2020;Seeing out of the box: End-to-end pre-training for vision-language representation learning. InCVPR, 2021]专门优化了图像预处理过程以提高检索效率。然而,即使采用了轻量级的架构,这些通常使用交叉注意力来进行更好的特征学习的方法,由于特征提取的二次执行,大多数仍然需要花费很长的参考时间。
先快后慢。上述两组方法不能在效率和准确度之间实现最佳的折衷,因此产生了第三组方法:快慢结合的方法。鉴于2.1节中的VSE和CA方法分别具有效率和准确度的优势,一些研究者[Thinking fast and slow: Efficient text-to-visual retrieval with transformers. In CVPR, 2021;Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021]提出先用快速的VSE技术筛选出大量的简单负面图库,然后用缓慢的CA技术检索出正面图库,从而争取在效率和准确度之间达到良好的平衡。
3.预训练图像-文本检索
对于ITR任务,早期的范式是对已经分别在计算机视觉和自然语言处理领域预训练的网络进行微调。转折点出现在2019年,人们对开发一个通用的跨模态预训练模态并将其扩展到下游的ITR任务的兴趣大增[Vilbert: Pretraining task-agnostic visiolin-guistic representations for vision-and-language tasks. InNeurIPS, 2019;Visualbert: A simple and performant baseline for vision and language, 2019]。在强大的跨模态预训练技术下,ITR任务的性能经历了爆炸性的增长,不需要任何的花哨功能。目前,大多数预训练的ITR方法都采用transformer架构作为构建模块。在此基础上,研究主要集中在模型架构、预训练任务和预训练数据方面。
模型架构。一批作品[Vilbert: Pretraining task-agnostic visiolin-guistic representations for vision-and-language tasks. InNeurIPS, 2019;Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021]对双流模型架构感兴趣,即两个独立的编码,然后在图像和文本处理分支上进行可选的后期交互。同时,将图像和文本处理分支封装为一个的单流架构越来越受欢迎[Visualbert: A simple and performant baseline for vision and language, 2019;Unicoder-vl: A universal encoderfor vision and language by cross-modal pre-training. InAAAI, 2020;Vilt: Vision-and-language transformer without con-volution or region supervision. InICML, 2021]。大多数方法严重依赖图像预处理过程,通常涉及目标检测模块或卷积架构,以提取初步的视觉特征,并作为后续transformer的输入。由此产生的问题有两个方面。首先,这个过程比后续过程消耗更多的计算资源,导致模型的低效率。然后,来自目标检测的预定义视觉词汇限制了模型的表达能力,导致精度低下。
令人鼓舞的是,关于改进图像预处理过程的研究最近开始流行起来。在提高效率方面,[Seeing out of the box: End-to-end pre-training for vision-language representation learning. InCVPR, 2021]采用快速视觉字典来学习整个图像的特征。[Pixel-bert: Aligning image pixels with text by deep multi-modal transformers.2020]直接将图像像素与transformer中的文本对齐。另外,[Vilt: Vision-and-language transformer without convolution or region supervision. InICML, 2021;Fashionbert: Text and image matching with adaptive loss for cross-modal retrieval. In SIGIR, 2020]将图像的patch级特征送入transformer,[Kd-vlp: Improving end-to-end vision-and-language pretraining with object knowledge distillation. In EMNLP, 2021]将图像分割成网格,与文本对齐。在提高精确度方面,[Vinvl: Revisiting visual representations in vision-language models. In CVPR, 2021]开发了一个改进的目标检测模型来提升视觉特征。[E2e-vlp: End-to-end vision-language pre-training enhanced by visual learning. In ACL-IJCNLP, 2021]将目标检测和图像加标题的任务放在一起,以增强视觉学习。[Probing inter-modality: Visual parsing with self-attention for vision-and-language pre-training. In NeurIPS, 2021]在学习图像特征时,通过采用自注意力机制探索视觉关系。考虑到所有这些,[An empirical study of training end-to-end vision-and-language transformers.2021]透彻地研究了这些模型设计,提出了一个端到端的新transformer框架,实现了效率和准确性的共赢。跨模态预训练模型架构的进步推动了ITR在性能上的进步。
预训练任务。预训练pretext 任务指导模型以端到端的方式学习有效的多模态特征。预训练模型是为多个跨模态的下游任务而设计的,因此通常会调用各种pretext 任务。这些pretext任务主要分为两类:图像-文本匹配和遮蔽建模。
ITR是跨模式预训练领域的一个重要的下游任务,其相关的pretext任务,即图像-文本匹配,在预训练模型中受到好评。 一般来说,在类似transformer的结构上附加一个ITR任务特定的头,通过比较不同模态的全局特征来区分输入图像-文本对是否语义匹配。 它可以被看作是一个图像-文本粗粒度匹配的pretext任务[Vilbert:Pretraining task-agnostic visiolin-guistic representations for vision-and-language tasks.InNeurIPS, 2019;Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In AAAI, 2020;Uniter: Universal image-text representation learning. In ECCV, 2020;Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021;Vilt: Vision-and-language transformer without convolution or region supervision. In ICML, 2021] 。 此外,它还被扩展到图像-文本细粒度匹配的pretext任务:ptach-单词对齐[Vilt: Vision-and-language transformer without convolution or region supervision. In ICML, 2021],区域-单词对齐[Uniter: Universal image-text representation learning. In ECCV, 2020]和区域-短语对齐[Kd-vlp: Improving end-to-end vision-and-language pretraining with object knowledge distillation. In EMNLP, 2021]。毫无疑问,预训练的图像-文本匹配pretext任务与下游的ITR任务建立了直接的联系,这缩小了任务无关的预训练模型和ITR之间的差距。
受自然语言处理预训练的启发,遮蔽语言建模pretext任务常用于跨模态预训练模型中。对应的是,在这种情况下也出现了遮蔽视觉建模pretext任务。两者被统称为遮蔽建模任务。 在遮蔽语言建模任务中[Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NeurIPS, 2019;Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In AAAI, 2020;Vinvl: Revisiting visual representations in vision-language models. In CVPR, 2021],输入文本遵循一个特定的遮蔽规则,随机遮蔽掉一个句子中的几个词,然后这个pretext任务驱动网络根据未遮蔽的词和输入图像来预测遮蔽的词。 在遮蔽视觉建模任务中,网络对被遮蔽区域的嵌入特征进行回归[Uniter: Universal image-text representation learning. In ECCV, 2020]或预测其语义标签[Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In AAAI, 2020]或同时进行[Kd-vlp: Improving end-to-end vision-and-language pretraining with object knowledge distillation. In EMNLP, 2021]。 遮蔽建模任务隐含地捕捉了图像和文本之间的依赖关系,为下游的ITR任务提供了强有力的支持。
预训练数据。数据层面的研究是跨模态预训练领域的一个积极趋势。一方面,图像和文本数据中的模态内和跨模态知识在预训练的ITR方法中得到了充分的利用[Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020;Rosita: Enhancing vision-and-language semantic alignments via cross-and intra-modal knowledge integration. In ACM MM, 2021]。另一个方面,许多研究集中在增加预训练数据的规模。 除了最广泛使用的大规模域外数据集,特别是用于预训练模型的数据集[Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In AAAI, 2020;Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021],原本用于微调和评估下游任务的域内数据集被添加到预训练数据中,以便更好地进行多模态特征学习[Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020;Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021]。除此之外,丰富的非配对单模态数据也可以被添加到预训练数据中,以学习更多的通用特征[Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning.2020]。除此以外,一些研究者[Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data.2020;Scaling up visual andvision-language representation learning with noisy text su-pervision. InICML, 2021;Filip: Fine-grained inter-active language-image pre-training. InICLR, 2022]为预训练模型收集新的更大规模的数据,这样简单粗暴的操作通常会在各种下游的跨模态任务中带来出色的表现,包括ITR。一般来说,数据层面的关注对跨模态预训练模型有积极影响,自然会促进下游的ITR任务。
4.数据集和评估
4.1数据集
研究人员已经为ITR提出了各种数据集。我们将最经常使用的数据集总结如下。1) COCO Captions包含123,287张图片,这些图片来自微软的Common Objects in COntext (COCO)数据集,每张图片都有人工生成的五个标题。在去除罕见的单词后,标题的平均长度为8.7。该数据集被分成82,783张训练图像、5000张验证图像和5000张测试图像。研究人员在5倍的1K测试图像和完整的5K测试图像上评估他们的模型。2) Flickr30K包括从Flickr网站上收集的31,000张图片。每张图片都包含五个文本描述。该数据集分为三部分,1000张图片用于验证,1000张图片用于测试,其余用于训练。
4.2评价指标
R@K是ITR中最常用的评价指标,是排名表中第K位的召回率的缩写,定义为前K位检索结果中正确匹配的比例。
4.3准确性比较
我们从特征提取和特征对齐两个方面对有代表性的和最新的ITR方法的准确性进行比较。
特征提取。我们在表1中列出了比较结果。在基于VSE的方法中,ALIGN [Scaling up visual andvision-language representation learning with noisy text su-pervision. InICML, 2021]由于对超过10亿个图像-文本对进行了大规模的预训练,远远超过了其他预训练方法的数据量,因此在准确性上比其他方法有了很大的提高。对于CA方法之间的比较,我们可以看到,随着时间的推移,这些方法的准确性在逐渐提高。对于基于VSE的方法和CA方法之间的比较,1)SCAN[Stacked cross attention for image-text matching. In ECCV, 2018]作为CA方法的首次尝试,与当时基于VSE的方法LTBN[Learning two-branch neural networks for image-text matching tasks. In TPAMI, 2018]相比,在准确率上有所突破;2)从整体上看,除了ALIGN,CA方法在R@1上比基于VSE的方法有压倒性的优势,这归功于CA方法中对跨模式特征互动的深入探索。然而,作为一个例外,基于VSE的方法对超大规模的数据进行预训练,可能会抵消由于对跨模态交互的探索较少而导致的性能下降,这一点在ALIGN的结果中得到了有力的支持。为了比较SA方法和基于VSE和CA的方法,在相同的设置下,即传统的ITR,SA方法DIME[Dynamic modality interaction mod-eling for image-text retrieval. InSIGIR, 2021]在Flickr30k上优于基于VSE和CA的方法,而在COCO Captions上则劣于SAN[Saliency-guided attention network for image-sentence matching. In ICCV, 2019]。SA技术存在着进一步发展的空间。
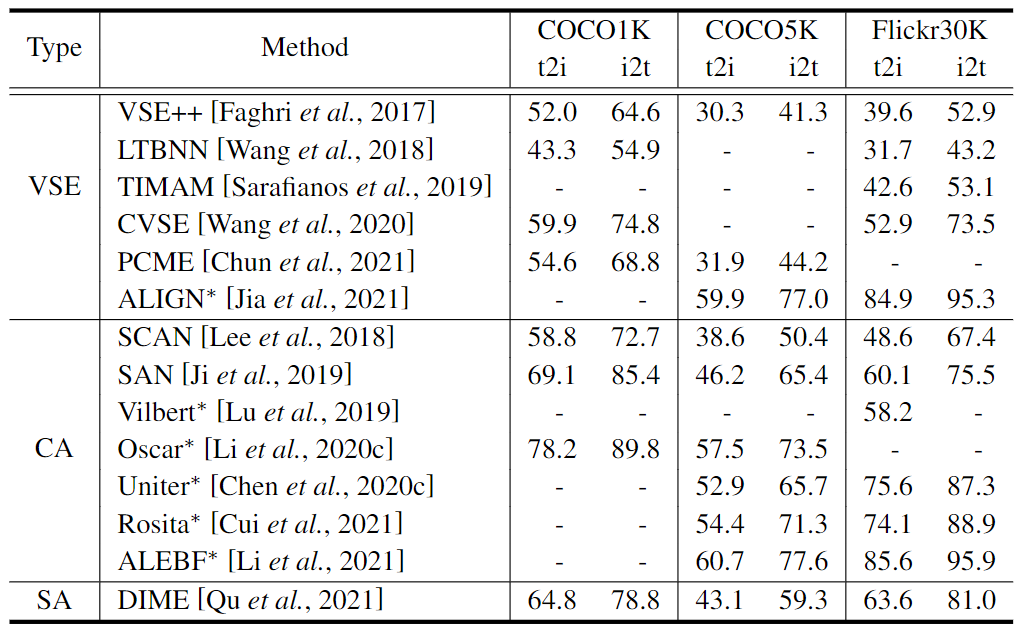
表1:从特征提取的角度看,在R@1的ITR方法之间的准确性比较。标有"∗"的方法代表预训练方法。我们显示了原始论文中报告的每种方法的最佳结果
特征对齐。比较结果见表2。在全局对齐驱动的方法中的比较方面,即使全局对齐采用基本的双流结构,ALIGN的R@1仍然在其他方法之上,包括TIMAM[dversarial representation learning for text-to-image matching. In ICCV, 2019]和PCME[Probabilistic embeddings for cross-modal retrieval. In CVPR, 2021],有着全局对齐的复杂网络结构。在涉及局部对齐的方法中进行比较,ALBEF[Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021]显示出优秀的性能。 值得注意的是,Uniter[Uniter: Universal image-text representation learning. In ECCV, 2020]和ViLT[Vilt: Vision-and-language transformer without con-volution or region supervision. InICML, 2021]只用了vanilla注意力机制就能得到不错的结果。 相比之下,SCAN[Stacked cross attention for image-text matching. In ECCV, 2018]和CAMP[Camp: Cross-modal adaptive message passing for text-image retrieval. InICCV, 2019]采用类似的机制,在R@1时表现不佳。 Uniter和ViLT以预训练-微调形式进行ITR任务,预训练跨模态数据的丰富知识对下游的ITR任务有利。从全局对齐驱动的方法和局部对齐的方法之间的比较来看,后者在整体上显示出比前者更好的性能,表明局部对齐对于实现高准确率的ITR的重要性。
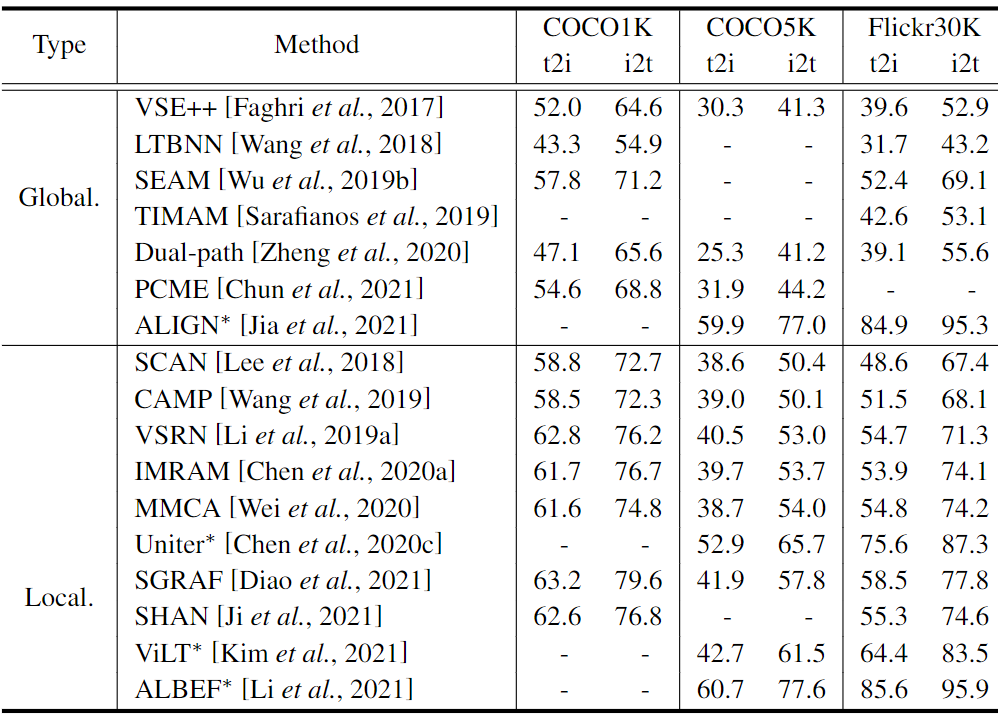
表2:从特征对齐的角度看,在R@1的ITR方法之间的准确性比较。标有"∗"的方法代表预训练方法。Global.和Local.分别是全局对齐方式和局部对齐方式的简称。我们展示了原始论文中报告的每种方法的最佳结果
此外,我们在图4中总结了ITR从2017年到2021年的发展趋势。这些年来,我们可以看到一个明显的精度提高的趋势。 具体来说,2020年的大跃进要归功于预训练ITR技术。此后,预训练ITR方法的准确率继续保持发展势头。由此可见,预训练ITR技术在促进ITR发展方面起着主导作用。 它离不开不断扩大的训练数据规模的支持。 我们可以看到,随着预训练ITR的出现,训练数据量急剧增加。
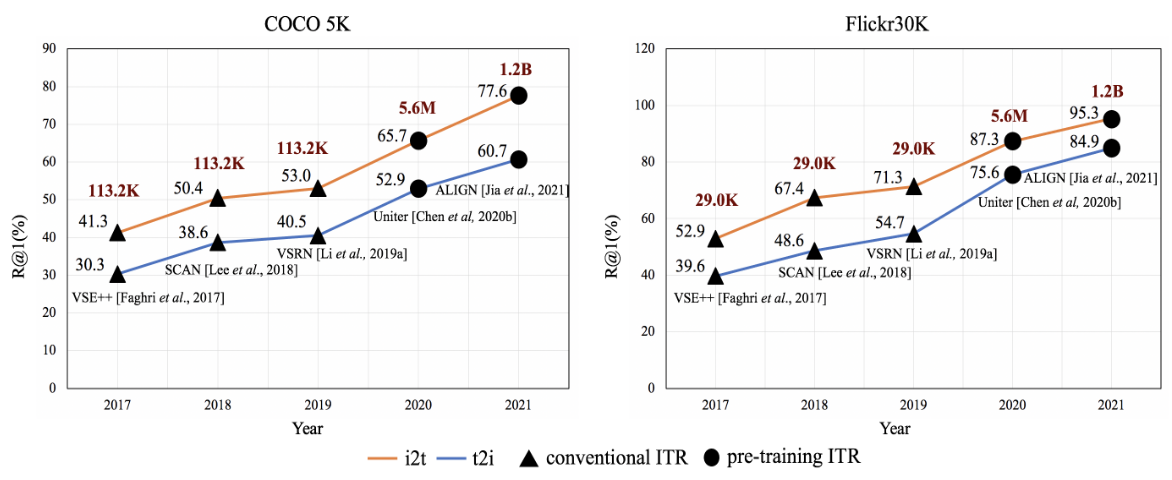
图4:ITR近年来的发展趋势。线图上方黑色的数字是该方法的R@1值,红色的数字是多模态训练数据的数量。
5.结论和未来工作
在本文中,我们从特征提取、特征对齐、系统效率和预训练范式四个方面对ITR方法进行了全面的综述。我们还总结了ITR中广泛使用的数据集和评价指标,在此基础上,我们定量分析了代表性方法的性能。报告的结论是,ITR技术在过去几年中取得了长足的发展,特别是随着跨模态预训练时代的到来。然而,在ITR中仍然存在着一些较少探索的问题。我们对未来可能的发展做了以下一些有趣的观察。

图5:COCO标题中的噪音数据说明。(a) 根据橙色标示的配对文本描述,很难捕捉到图像中的内容。(b) 除了带有实心箭头的正面图像-文本对,对于带有虚线箭头的负面图像-文本对,似乎也是对应的。
数据。目前的ITR方法基本上是数据驱动的。换句话说,研究人员设计并优化网络,以寻求基于现有基准数据集的最佳检索方案。首先,跨模式数据的异质性和语义的模糊性不可避免地会给数据集带来噪音。例如,如图5所示,图像存在难以捉摸的文字描述,COCO Captions中的图像和文字之间存在多种对应关系。因此,在某种程度上,目前的ITR方法在这类数据集上的结果仍然是有争议的。已经有一些关于数据多样性的探索[Polysemous visual-semantic embedding for cross-modal retrieval. In CVPR, 2019;Probabilistic embeddings for cross-modal retrieval. In CVPR, 2021;Learning cross-modal retrieval withnoisy labels. InCVPR, 2021],然而只考虑训练数据而忽略了测试数据。另外,除了普通的数据信息,即图像和文本,图像中出现的场景文本是ITR的宝贵线索,这在现有的方法中通常被忽略。[Stacmr: scene-text aware cross-modal retrieval. In WACV,2021]是将场景文本信息明确纳入ITR模型的先驱性工作。这些研究为数据层面的ITR的进一步发展留下了空间。
知识。人类具有在视觉和语言之间建立语义联系的强大能力。这得益于他们累积的常识性知识,以及因果推理的能力。自然地,将这种高层次的知识纳入ITR模型对于提高其性能是很有价值的。CVSE[Consensus-aware visual-semantic embedding for image-text matching. InECCV,2020]是一项开创性的工作,它计算了图像标题语料库中的统计相关性,作为ITR的常识性知识。然而,这种常识性知识受到语料库的限制,并不完全适合ITR。未来,为ITR量身定做常识性知识并建立因果推理模型可能是有希望的。
新范式。在目前的趋势下,与传统的ITR方法相比,预训练ITR方法在准确性上有压倒性的优势。在一个大规模的跨模态模型上进行预训练再微调,成为实现最先进的检索结果的一个基本范式。然而,这种范式在微调阶段需要大量的标记数据,很难应用于现实世界的场景。寻求和开发一种新的资源友好型ITR范式是有意义的。例如,最近崭露头角的prompt-based tuning技术,具有出色的few-shot能力,为开发这样一种新的范式提供了指导,即所谓的预训练-提示。