由于检索目标在图像中出现的位置以及大小是变化不定的,因此采用多尺度的局部特征代替整张图像的特征在一定程度上可以改善检索效果。
该论文是采用多尺度局部特征提取比较前期的一片文章,其直接在原图像上进行区域的划分,然后对划分后的图像进行特征的提取,最后将一张图像所有区域提取出的特征向量拼接到一起进行后处理工作。
本文主要讲解该论文子区域划分的方法。
论文采用L种不同的尺寸进行正方形区域的划分。在图像的长宽方向均获取L个正方形,即在每种尺寸l下会划分出l^2个子区域(l=1,2...L)。子区域的边长由图像的最长边决定:

其中w和h分别为原始图像的宽和高,我们假设图像的宽大于高,即w>h,在长度为w的边上需要划分出L个子段
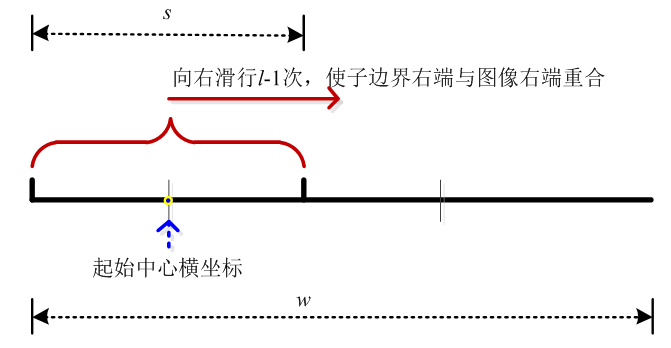
如上图所示,在长边w上,子区域中心起始横坐标为:
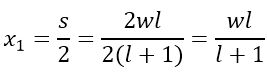
为了在长w的边上划分出l个子区域,则需要上述初始的子区域向左滑行l-1次,每次滑行的距离为:

令i=1,2…l,对于初始子区域i=1,则初始子区域在向右滑行的过程中,第i个子区域的中心横坐标为:

对于短边,先假设其为最长边,即假设s=2h/(l+1),同样采取上边的方法可以得到:

则可以获取子区域的中心坐标:

不难想到,对于一个矩形图像而言,子区域边长的取值只有一种情况,而我们在选取中心坐标时则是假设各自为最长边来划分的。这就会引起一个问题,也就是在划分的子区域中,短边两端的子区域必然会超出图像区域。在论文中,作者对超出图像区域的子区域进行了调整,使得每个子区域只覆盖图像区域。
最终获取的子区域个数为:

如果L=4,则共计可得1+4+9+16=30个子区域,每个子区域均可获得一个512维的特征向量,拼接到一起后则可获得最终15360维的向量。