聚类:通过对无标记训练样本的学习来揭示数据的内在性质及规律,将数据集中的样本划分为若干个通常是不相交的子集。
评价聚类结果的方法:内部指标(主要通过类间距离以及类内距离)以及外部指标(模型训练结果与标准结果之间的差距)。
Ps.关于无序属性(文字属性等)的距离度量可以用簇中某属性的的属性值的数量作为属性。
常用聚类方法:
1.原型聚类:通过不断的更新原型,实现对聚类簇的刻画。比如:k均值聚类(簇内的均值),学习向量量化(学习向量不断移动),高斯混合聚类(对高斯分布的参数不断调整);
2.密度聚类:通过密度的概念,结合样本的可连接性,完成聚类;
3.层次聚类:在不同层次对数据进行划分,形成树状结构。(簇的不断合成)
9.2 性能度量
外部指标:将评价结果与专家给出的模型的结果相对比
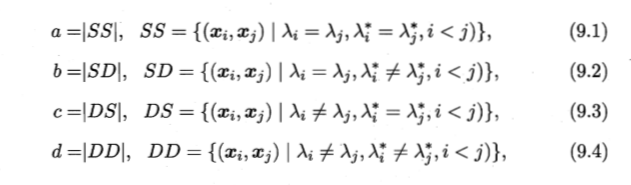
S=Same D=Different 给出两种簇划分的方式 ;
b:第i和第j个样本在第一种划分中属于同一个簇,在第二种划分中属于不同的簇。

表示两者划分完全相同的可能性在可能相同中的比例。
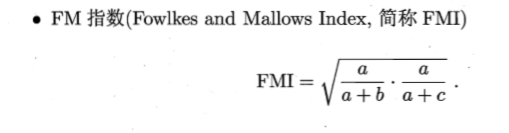
表示完全相同的可能性在第一种划分中相同的可能性的比例乘上在第二种种相同的可能性。

两次判断相同占所有可能的比例。
内部指标:直接考察聚类的结果

DBI指数表示:将类内的点的距离除以类间点的距离,则越小越好;
DI指数表示:两个类间距离除以类内距离,则越大越好;
体现分离程度,类间尽可能分开,类内尽可能靠近。
9.3 距离计算
VDM(Value Difference Metric)用于实现对无序属性的度量:
在某个样本簇中,某属性上属性值的数量除以所有样本中属性值的数量。
9.4原型聚类:通过聚类给出一组原型刻画,再对原型进行迭代更新。
k均值聚类:不断更新均值中心的改变。
1.随机选择样本作为初始原型;
2.根据距离远近,对剩余样本进行分类;
3.根据分类形成的簇,再计算均值,作为新的原型;
4.重复2,3直到达到一定条件。
学习向量量化(LVQ):将原型靠近或远离样本,进行更新。
1.随机初始化一组原型;
2.随机选择样本,与其最近原型的结果的异同,如果相同,则原型向该样本靠近,否则远离;
3.不断重复2,直到达到一定条件。
高斯混合聚类:
1.初始化混合的系数,各个混合成分的均值和协方差矩阵;
2.根据给出的公式完成后验概率的计算;
3.根据得到的后验概率,使用极大似然估计,完成参数的更新。
后验概率计算如下:

如果盲猜,则根据α即可完成推断—先验概率
如果要结合对应的信息,那么则需要计算后验概率,分子右侧只需要带入对应的均值协方差以及x,即可进行计算出对应的x在某种成分中的概率,而分母则是将所有概率结合。最终计算出某个样本xi属于某个分布成分zj的概率:zj的概率乘上zj的概率下得到xi的概率除以xi的所有概率。
9.5密度聚类:从样本密度角度考虑样本可连接性聚类
以DBSCAN为例:
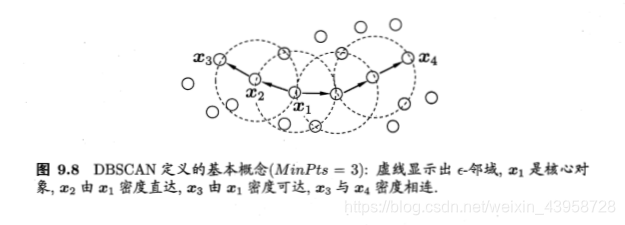
邻域:距离在一定范围内;
核心对象:邻域内的点数达到一定要求;
密度直达,在核心对象的邻域内(只能由核心对象直达);
密度可达:可以通过密度直达的点相连,最终走到核心对象(只能由核心对象可达);
密度相连:可以通过不同方向的密度可达相连。
形成簇的定义:由密度可达导出的最大密度相连样本集合
方法:
1.找到所有的核心对象
2.随机选择一个核心对象,找到该对象所有的密度可达点,形成一个簇
3.直到所有点都被访问为止。
9.6层次聚类:试图在不同层次对数据集进行划分,形成树状结构
以AGNES为例:
现将每个样本看成一个簇,然后再每一步中找出最近的两个簇进行合并,直到达到预设的聚类簇个数
距离计算方法:
单链接:两个簇的最近样本
全链接:两个簇的最远样本
均链接:两个簇的平均距离
