文章目录
转载请标明出处,本篇文章允许转载,禁止抄袭
前言
聚类是无监督学习中最主要的应用。
无监督学习:训练样本的标记信息是未知的
- 目标: 通过对无标记训练样本的学习,揭示数据的内在性质及规律,为进一步的数据分析提供基础。

举例来说,如图所示,将上述无标记(但是有多个属性x)的小球进行划分为k个类。
一、聚类任务
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。

如图所示,聚类将其分为了5个簇,每个簇可能对应一些潜在的概念(不是原属性集中的属性)
如小球15(半径0.5cm,光滑),将所有小球划分开的可能是小球的材料,重量等等,但是小球的材料或其他能将小球划分成簇的概念,对聚类算法事先是未知的。聚类过程中,仅能自动形成簇结构,但是每个簇所对应的概念需要使用者进行命名。
形式化的说,假定样本集D = {x1,x2,……,xm}包含m个无标记样本,每个样本xi=(xi1;xi2;……;xin)是一个n维特征向量,则聚类算法将样本D划分为k个不相交的簇{Cl|l=1,2,…,k},其中任意两个簇的交集为空,
聚类既能作为一个单独过程,用于寻找数据内在的分布结构。也能作为分类等其他任务的前驱过程。
二、性能度量
聚类性能度量也称之为聚类“有效性指标”。与监督学习中的性能度量作用相似。
对于聚类结果,我们需要通过某种性能度量来评估其好坏;另一方面,若明确了最终要使用的度量,就可以直接将这个度量作为聚类过程的优化目标,从而更好的得到符合要求的聚类结果。
聚类是将样本D划分为若干互不相交的子集,集样本簇。
我们希望同一个簇的样本尽可能的彼此相似,不同簇的样本尽可能的不同。即聚类结果的“簇内相似度”尽可能高,“簇间相似度”尽可能高。
聚类性能度量大致分为两类:
- 外部指标:将聚类结果与某个“参考模型(即外部模型)”进行比较
- 内部指标:直接考察聚类结果二不利用任何参考模型
1.外部指标
对数据集(m个数据)D = {x1,x2,……,xm},假定通过聚类给出的簇划分(k个簇)为C={C1,C2,……,Ck},和参考模型给出的簇划分(k个簇)为C*={C1 *,C2*,……Ck*}。

相应的,令λ与λ*分别表示C和C*对应的簇标记向量。我们将样本两两配对考虑,定义
a=|SS|,SS={(xi,xj) | λi = λj, λi* = λj*,i<j},(9.1)
b=|SD|,SD={(xi,xj) | λi = λj, λi* ≠ λj*,i<j},(9.2)
c=|DS|,DS={(xi,xj) | λi ≠ λj, λi* = λj*,i<j},(9.3)
d=|DD|,DD={(xi,xj) | λi ≠ λj, λi* ≠ λj*,i<j},(9.4)
其中:
集合SS包含了C中隶属于相同簇且在C*中也隶属于相同簇的样本对。
集合SD包含了C中隶属于相同簇且在C*中隶属于不同簇的样本对。
集合DS包含了C中隶属于不同簇且在C*中隶属于相同簇的样本对。
集合DD包含了C中隶属于不同簇且在C*中也隶属于不同簇的样本对。
有a+b+c+d=m(m-1)/2
基于式(9.1)~(9.4)可导出下面这些常用的聚类性能度量外部指标:
- Jaccard系数(简称JC)
JC = a /(a+b+c) - FM指数(简称FMI)
FMI = √((a/(a+b)*(a/(a+c)) - Rand指数(简称RI)
RI = 2(a+b)/(m(m-1))
上述性能度量的结果值均在[0,1]区间,值越大越好。
2.内部指标
考虑聚类结果的簇划分C={C1,C2,……,Ck},定义:

上述定义可参考下图解析:
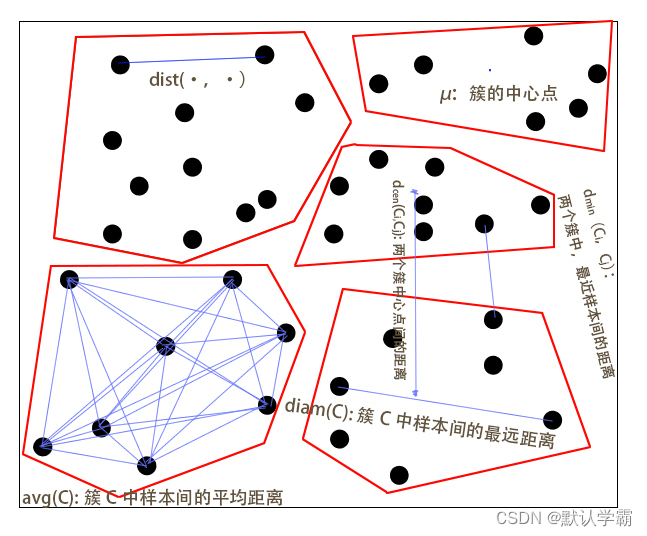
基于式(9.8)~(9.11)可导出下面这些常用的聚类性能度量内部指标:

DBI的值越小越好,DI的值越大越好。
三、距离计算
对于函数dist(·,·),若他是一个“距离度量”,则需满足一些基本性质:
非负性:dist(xi,xj)≥0 可理解为:距离不能为负
同一性:dist(xi,xj)= 0 当且仅当xi=xj 可理解为:当一个距离为0时,只有当且仅当这两个点重合时
对称性:dist(xi,xj)=dist(xj,xi) 可理解为:i点到j点的距离=j点到i点的距离
直递性:dist(xi,xj)≤ dist(xi,xk)+ dist(xk,xj) 可理解为:两边之和大于第三边,当k在点i和点j的连线上时,等式成立。
给定样本xi = (xi1;xi2;……;xin)与xj = (xj1;xj2;……;xjn),最常用的是“闵可夫斯基距离”
distmk(xi,xj )= ( ∑ i = 1 n ∣ x i u − x j u ∣ p ) 1 / p (\sum_{i=1}^{n} |x_{iu}-x_{ju}|^p)^{1/p} (∑i=1n∣xiu−xju∣p)1/p
对p≥1,上式显然满足距离度量的基本性质。
p = 2 时,闵可夫斯基距离即为欧式距离
disted(xi,xj )= ||xi - xj||2= ( ∑ i = 1 n ∣ x i u − x j u ∣ ) \sqrt{}(\sum_{i=1}^{n} |x_{iu}-x_{ju}|) (∑i=1n∣xiu−xju∣)
p = 1 时,闵可夫斯基距离即为曼哈顿距离
distman(xi,xj )= ||xi - xj||1= ∑ i = 1 n ∣ x i u − x j u ∣ \sum_{i=1}^{n} |x_{iu}-x_{ju}| ∑i=1n∣xiu−xju∣
闵可夫斯基距离可用于有序属性。
注:
属性常备划分为:连续属性和离散属性
在讨论距离计算时,属性上是否定义了“序”关系更为重要。在此,将离散属性进一步划分为有序属性和无序属性。
有序属性:
能直接在属性值上计算距离的属性,如{1,2,3}
无序属性:
不能直接在属性值上计算距离,如{小狗,小猫,老鼠}
对无序属性可采用VDM。(在此不进行详细讲解,详情请见西瓜书p200)

将闵可夫斯基距离和VDM结合即可处理混合属性。
加权闵可夫斯基距离:
注意:
相似度度量
通常我们基于某种形式的距离来定义“相似度度量”,距离越大,相似度越小。用于相似度度量的距离未必一定要满足距离度量的所有基本性质,尤其是直递性。
四、原型聚类
原型聚类也称为“基于原型的聚类”,此类算法 假设 聚类结构能 通过一组原型 刻画,在现实聚类任务中极为常用。通常情况下,算法先对原型进行初始化,然后对原型进行迭代更新求解。采用不同的原型表示、不同的求解方式,将产生不同的算法。
(一)k均值算法(k-means 算法)
给定样本集D = {x1,x2,……,xm},k-means算法针对聚类所得簇划分C = {C1,C2,…,Ck}(将D划分为k个簇,得到簇1,簇2,…,簇k),最小化平方误差E,得到:
E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 \sum_{i=1}^{k}\sum_{x∈C_i} ||x - μ_i||_2^2 ∑i=1k∑x∈Ci∣∣x−μi∣∣22
其中,μi = 1 ∣ C i ∣ ∑ x ∈ C i x \frac 1 {|C_i|}\sum_{x∈C_i}x ∣Ci∣1∑x∈Cix
μi是簇Ci的均值向量。上述公式在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,E越小则簇内样本相似度越高。
最小化E并不容易,找到他的最优解需考察样本集D中所有可能的簇划分,这是一个NP难问题(可以暂时理解为数据太大,难度太高)。
因此,k-means算法采用了贪心策略,通过迭代优化来近似求解。
算法流程如下:

(二)学习向量量化
与k均值算法类似,学习向量量化(LVQ)也是视图找到一组原型向量来刻画聚类结构。
但是与一般聚类算法不同的是,LVQ假设数据样本带有类别标记,学习过程利用样本的这些监督信息来辅助聚类。
本算法有点抽象,算法思想用相对白话的方式讲述,加上列举的例子,相对来说会比较好理解一点。
-
先输入样本集D,输入想要的原型向量的个数q,输入假设的每个原型向量的初始的类别标记{t1,t2,…,tq},这个原型向量的类别标记是属于原来样本集D中的类别标记。( 如:原来样本集的标记Y={飞机,轮船,火车,高铁},设置的初始类别标记也必须是其中的(ti∈Y),不能出现自行车什么的,但是可以重复,比如5个原型向量={飞机,飞机,火车,高铁,飞机}。)输入学习率η∈(0,1)。
-
初始化一组原型向量{p1,p2,p3,p4,p5}(对p5,假设如上面的例子,第5个是飞机,就从类别标记为飞机的样本中随机挑选一个作为第5个簇的原型向量)
-
do{
从样本集D随机选取样本(xj,yj);
计算样本xj与每个原型向量pi的距离:dji = ||xj - pi||2
找出与xj距离最近的原型向量,假设为pi*(对这个最近的原型向量进行更新)
如果 选取的样本的标记yj = 这个原型向量的标记 , 新的原型向量p’ = pi* + η · (xj - pi*)
如果 两者标记不相等 ,新的原型向量 p’ = pi* - η · (xj - pi*)
更新:将这个新的原型向量 p’的值赋给 pi* -
}while(满足停止条件) 算法的停止条件:如已达到最大迭代轮数,或原型向量更新很小甚至不再更新
-
输出 原型向量{p1,p2,p3,p4,p5}
算法关键在于如何更新原型向量。可以理解为,对于一个样本,如果原型向量和这个样本属于一个类别,那么,这个原型向量向这个样本靠近,否则远离。
在学得一组原型向量后,即可实现对样本空间χ的簇划分。
对任意样本x,他将被划入与其距离最近的原型向量所代表的的簇中;换言之,每个原型向量pi定义了已知相关的一个区域Ri,该区域中每个样本与pi的距离不大于他与其他原型向量的距离。由此形成了对样本空间χ的簇划分{R1,R2,……,Rq},该划分通常称为Voronoi剖分。
(三)高斯混合聚类
1、概念
本章抽象程度较高,建议大家结合书本查看,或者跳过,有需要时再来翻阅。
与k均值、LVQ用原型向量来刻画聚类结构不同,高斯混合聚类采用概率模型来表达聚类原型。
首先,我们先来回顾(预习)一下高斯分布的定义。对n维样本空间χ中的随机向量x,若x服从高斯分布,其概率密度为

为了明确显示高斯分布与相应参数的依赖关系,将概率密度函数即为p(x| μ,∑)
我们可以定义高斯混合分布

2、算法思想
算法思想在这里仍采用尽可能白话的方式讲述:
输入:样本集D,高斯混合成分个数k(可以视为自己设定的分成簇的个数)
过程:(这里把过程用花括号括起来方便理解)
1:初始化高斯混合分布的模型参数{(αi,μi,∑i)| 1≤i≤k}
2:do{(循环迭代以下过程直至满足条件)
3: for j = 1,2,……,m { (对每个训练样本进行循环)
4: do{
5: γji=pM(zj = i| xj) (1≤i≤k) (根据公式(略)计算第j个样本由各混合成分生成的后验概率,1个样本计算k次,生成的γ可以看成是一个矩阵形式)
6: }
7: }
8: for i = 1,2,……,k { (对每个簇进行循环)
9: do{
10: 计算新的均值向量μi、新的协方差矩阵∑i、新的混合系数αi(公式略)
11: }
12: }
13: 将模型参数{(αi,μi,∑i)| 1≤i≤k}改为{(α’i,μ’i,∑’i)| 1≤i≤k}
14:}
15:Ci = ∅ ( 1≤i≤k)将簇清空
16:for j=1,2,……,m {
17: do{
18: 根据公式(略)确定第j个样本的簇标记λj
19: 将xj划入相应的簇:Cλj = Cλj∪{xj} (由样本的簇标记找到相应的簇,将这个样本加入这个簇中)
20: }
21:}
输出:簇划分C={C1,C2,……,Ck}
总的来说,可以理解为算法假设样本生成过程由高斯混合分布给出,通过不断更新每个样本由各个混合成分生成的后验概率,再去根据新的后验概率更新新的均值向量等参数,循环迭代后,将每个样本划分到相应的簇。
五、密度聚类
密度聚类也称为“基于密度的聚类”,此类算法假设聚类结构能通过样本分布的紧密程度确定。
通常情况下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇,去获得最终的聚类结果。
DBSCAN是一种著名的密度聚类算法,他基于一组邻域参数来刻画样本的紧密程度。
算法思想:
先任选一个核心对象为种子,在由此出发确定相应的聚类簇。
算法先根据给定的邻域参数找出所有核心对象;
然后再任选核心对象作为出发点,找出其可达的样本生成聚类簇
直到所有样本都被访问。

算法迭代过程(举例):

六、层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。
数据集的划分可采用自底向上的聚合策略,也可以采用自顶向下的分拆策略。
AGENS是一种采用自底向上聚合策略的层次聚类算法。他先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类进行合并,该过程不断重复,直至到达预设的聚类簇个数。
这里的关键是如何计算聚类簇之间的距离。
实际上,每个簇是一个样本集合,因此,只需采用关于集合的某种距离即可,有以下几种:

显然,最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,平均距离由两个簇的所有样本共同决定。当聚类距离由上述3中距离计算时,被相应的称为单链接、全链接、均链接算法。

算法思想:
算法先对仅含一个样本的初始聚类簇和相应的距离矩阵进行初始化,
不断合并距离最近的聚类簇,并对合并得到的聚类簇的距离矩阵进行更新
循环更新,直到满足条件
AGENS算法一直执行会使得所有样本出现在同一个簇中,即k=1,可得到如下的树状图。

在树状图特定层次上进行分割,则可以得到相应的簇划分结果。
转载请标明出处,本篇文章允许转载,禁止抄袭