1. 尝试用线性回归模型,来解决欠拟合问题,效果不好(附代码)
我们可以使用线性回归模型来拟合数据,然而,在现实中,数据未必总是线性(或接近线性)的。当数据并非线性时,直接使用LinearRegression的效果可能会较差,产生欠拟合。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
x = np.linspace(0, 10, 50)
# 真实的数据分布。该分布是非线性的。
y = x * np.sin(x)
# np.newaxis 表示进行维度的扩展,可以认为是增加一个维度,该维度为1。
# 此种方式也可以通过reshape方法来实现。
X = x[:, np.newaxis]
lr = LinearRegression()
lr.fit(X, y)
# 输出在训练集上的分值。查看线性回归LinearRegression在非线性数据集上的拟合效果。
print(lr.score(X, y))
# 将样本数据以散点图进行绘制。
plt.scatter(x, y, c="g", label="样本数据")
# 绘制预测值(模型的回归线)
plt.plot(X, lr.predict(X), "r-", label="拟合线")
plt.legend()
plt.show()
# 结果:R ^ 2值为0.05908132146396671,模型在训练集上表现非常不好,产生欠拟合。
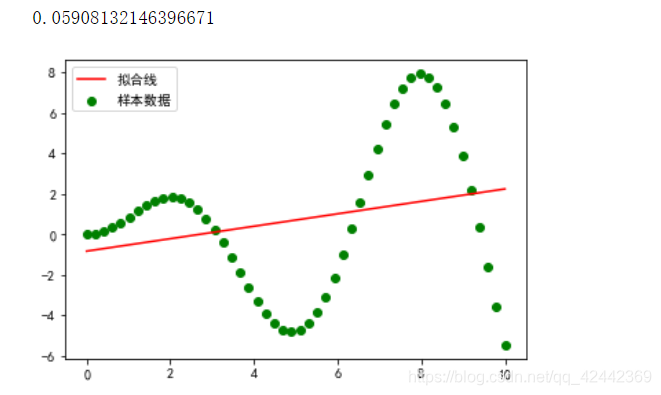
是真实线,还没有加噪声。就是想看,非线性再线性上表现怎么样。


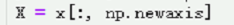
表示要进行维度的扩展
可以认为是增加一个维度,该维度为1
Why要增加一个维度?
意味着x能否送到fit?不能
一维不能
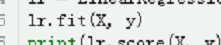
X要变成二维
现在是 50,
变成50,1
之前是reshape
现在变成

# x = np.linspace(0, 10, 50)
# print(x.shape)
# print(x[:, np.newaxis].shape)
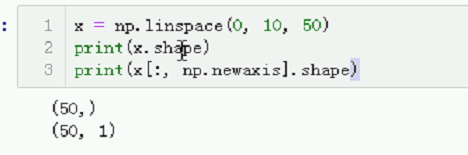
习惯大写

欠拟合 是不涉及未知数据的,欠拟合是训练集相关
跟未知数据无关
Eg. 模拟题都做不好
看下效果

将样本数据以散点图进行绘制
真实值

还差一个预测值,就是一条回归线,模型的回归线。

Show()在jupyter里面可以不加,pycharm里面得加,这也是 sinx x

综上看,这个拟合效果不好。所以线性回归 对非线性 拟合效果不好。相当于蒙。
因为线性回归是直的,在训练集上表现不好,产生欠拟合现象, 值很低。
2. 欠拟合怎么办?引入多项式扩展
此时,我们可以尝试使用多项式扩展来进行改进。
多项式扩展,可以认为是对现有数据进行的一种转换,通过将数据映射到更高维度的空间中,该模型就可以拟合更广泛的数据。
假设,我们有如下的二元线性模型:
如果该模型的拟合效果不佳,我们就可以对该模型进行多项式扩展。例如,我们进行二项式扩展(也可以进行更高阶的扩展),结果为:
当进行多项式扩展后,我们就可以认为,模型由以前的直线变成了曲线。从而可以更灵活的去拟合数据。
多项式拟合的应用,仍然变为线性模型
经过多项式扩展后,我们依然可以使用之前的线性回归模型去拟合数据。这是因为,我们可以假设:
这样,之前的模型就会变成:
从而,我们依然可以认为,这还是一种线性模型。
线性回归本身解决不了,可以多项式扩展
多元线性回归 是直的 是一个面

怎么进行多项式扩展?扩展到几阶?
回顾什么是线性回归模型?
- 图像是直的
- 特征的最高次项是1
先进行直接的多项式扩展:
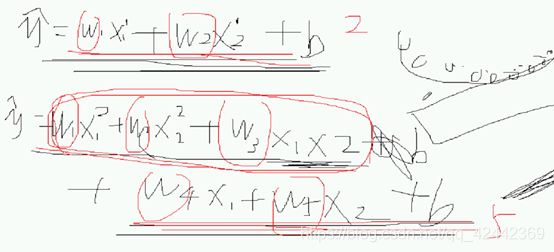
二维变为五维,在空间中张开了,想象…
一维 线
二维 平面
三维 超平面
多项式扩展,把它由一维的线变为面,再变为超平面。
扩展是怎么来的?扩展到几阶?
所有的特征任意组合:
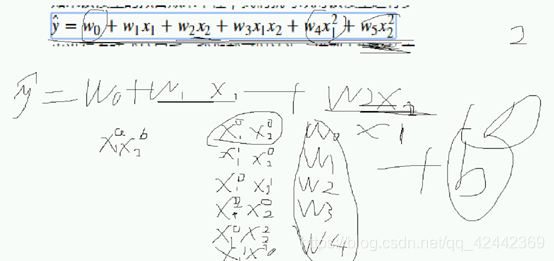
W是几不重要,b就是w
3. 多项式转换规则(附代码)
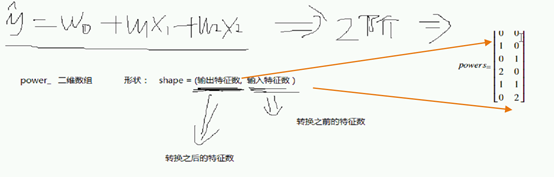
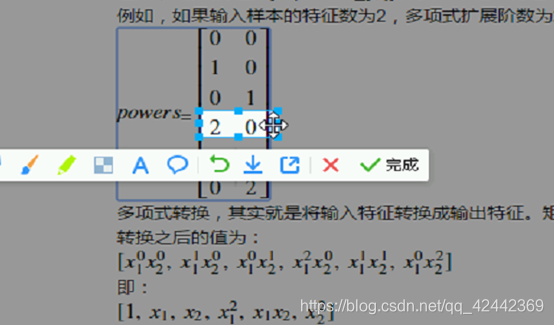
我们可以使用sklearn中提供的PolynomialFeatures类来实现多项式扩展。通过powers_属性可以获取扩展之后每个输入特征的指数矩阵。指数矩阵的形状为[输出特征数, 输入特征数]。powers_[i, j]表示第i个输出特征中,第j个输入特征的指数值。
例如,如果输入样本的特征数为2,多项式扩展阶数为2,则指数矩阵为:
多项式转换,其实就是将输入特征转换成输出特征。矩阵的每行对应每个输出特征,每列对应每个输入特征的指数,例如,对于两个输入特征
来讲,多项式转换之后的值为:
即:
4. 多项式扩展的规则
每个输入特征分别带有一个指数(指数值为非负整数),然后让指数之间进行任意可能的组合,但要保证所有的指数之和不能大于扩展的阶数。
# 类似PolynomialFeatures这样功能的类(数据预处理),所有的转换方法都叫做transform。
# 拟合与转换可以同时进行,方法名称都叫做fit_transform。
import numpy as np
# sklearn.preprocessing 该模块提供数据预处理的相关功能。
# PolynomialFeatures多项式扩展类,可以对模型进行n阶扩展。从而可以解决欠拟合问题。
from sklearn.preprocessing import PolynomialFeatures
X = np.array([[1, 2], [3, 4]])
# X = np.array([[1, 2, 3], [3, 4, 5]])
# 定义多项式扩展类,参数指定要扩展的阶数。
poly = PolynomialFeatures(2)
# 拟合模型,计算power_的值。
# poly.fit(X)
# 对数据集X进行多项式扩展,即进行多项式转换。
# r = poly.transform(X)
# 我们可以令fit与transofrm两步一起完成。
r = poly.fit_transform(X)
print("转换之后的结果:")
print(r)
print("指数矩阵:")
# 指数矩阵,形状为(输出特征数,输入特征数)。
print(poly.powers_)
print(f"输入的特征数量:{poly.n_input_features_}")
print(f"输出的特征数量:{poly.n_output_features_}")
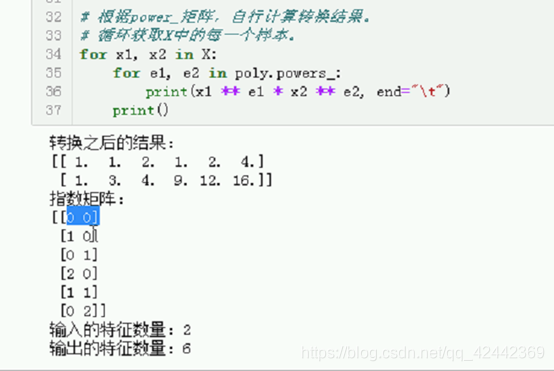
# 根据power_矩阵,自行计算转换结果。
# 循环获取X中的每一个样本。
for x1, x2 in X:
for e1, e2 in poly.powers_:
print(x1 ** e1 * x2 ** e2, end="\t")
print()
以前的非线性回归,还能适用吗?将Z1 = x1 … Z5,带入上面的公式。如下图:

y_hat又变成线性模型了,之前的线性回归模型,对多项式扩展之后的方程同样能够适用。
尽管是最高次项,只要经过转换,仍然能够进行适用。
可以假设,所以可以用linearregresstion处理多项式。
以前2个特征,现在是5个特征的超平面,拟合能力更强。
多项式特征,这样一个类 ,可以实现一个多项式扩展,在以前的特征上转换。
从低维的空间映射到高维的空间。
拟合之后,有powers属性,下划线。得到一个矩阵,输出的特征的数量。以及每一个输入特征的,扩展的时候没有必要自己去数,如何扩展咱么得知道细节是如何扩展。
Powers 扩展后 每一个特征的 指数;Power_可以看成二维数组
形状。
每一个输入特征都会带指数;每一列 特征的指数值。

输入特征: 转换之前的特征数,因为我们现在要实现多项式转换。
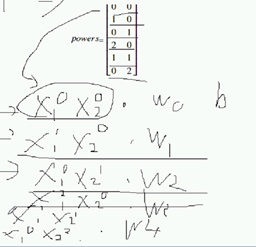
其实转换规则就是:多项式扩展
以前 2个特征 现在扩展到5个特征 不考虑截距


化简 第一个是1
二维 输入特征 变成 五维输出特征
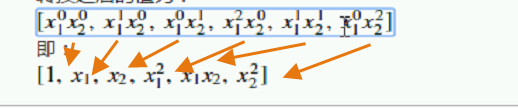
5. 代码的进一步解释
新的 模块 sklern.preprocessing 数据预处理的模块
多项式扩展 相当于 数据转换 相当于 数据预处理
Metics类: 提供 模型评估 的类
多项式扩展类
2行2列 1,2是一个样本
1 x1 2 x2
一列是一个特征
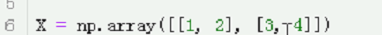
定义了一个多项式对象
不要用predict, 这个模型不是负责预测的 Poly
把转换的结果交给别的模型进行预测
只有x没有y
拟合 是干什么 试求powers
扩展的阶数不同 powers数量不一样
Fit就是根据传递额阶数 计算powers的值

有两个样本
转换成两个
根据


指数矩阵就是 形状为


换成3阶

优化:
合二为一

poly.fit(X)
r = poly.fit_transform(X)
再来,根据power矩阵,自行计算转换结果
拆包
X1 x2
对powers矩阵循环
e1次幂,还是指数后,乘积,只不过使用循环
结合性,乘方有优先性
通用上的预处理规则,Fit就是计算转换的规则
没有powers数组,是转换不了的;而这个数组,是通过数组拟合出来的
多项式如何进行转换?
扩展就是多项式转换?
6. 对之前未解决的欠拟合问题,应用多项式扩展来解决(附代码)
现在,就让我们对之前的程序来进行多项式扩展,尝试解决欠拟合问题。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
x = np.linspace(0, 10, 50)
y = x * np.sin(x)
X = x[:, np.newaxis]
figure, ax = plt.subplots(2, 3)
figure.set_size_inches(18, 10)
ax = ax.ravel()
# n为要进行多项式扩展的阶数。
for n in range(1, 7):
# 注意:多项式1阶扩展,相当于没有扩展(没有变化)。
poly = PolynomialFeatures(degree=n)
X_transform = poly.fit_transform(X)
# 注意:多项式扩展之后,我们依然可以将数据视为线性的,因此,我们还是可以通过之前的
# LinearRegression来求解问题。
lr = LinearRegression()
# 使用多项式扩展之后的数据集来训练模型。
lr.fit(X_transform, y)
ax[n - 1].set_title(f"{n}阶,拟合度:{lr.score(X_transform, y):.3f}")
ax[n - 1].scatter(x, y, c="g", label="样本数据")
ax[n - 1].plot(x, lr.predict(X_transform), "r-", label="拟合线")
ax[n - 1].legend()
生成数据集 50个点
创建y 非线性
把x变成二维的,使用np.newaxis
50,
50,1
接下来进行可视化的绘图操作
看一下多项式扩展的效果好不好
R^2值怎么样
数据如何进行的分布,线靠的近不近
阶数很关键,画6个子图 每个阶数的拟合情况
每一个阶的r^2
Subplots子绘图区域
画布大小 figure.set 因为2 3 宽
Ravel() 变成一层循环,之前是二维
N表示要扩展的阶数
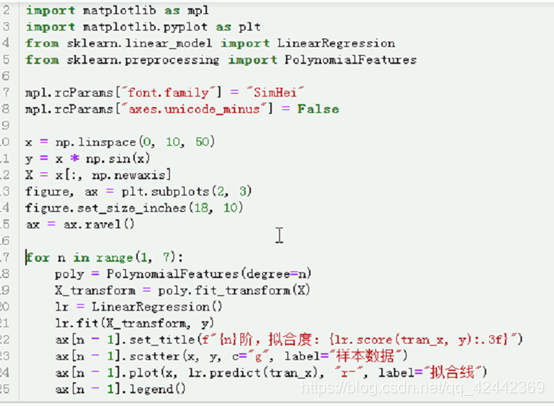

N=1 1阶 数组是0开始 所以n-1
标题
拟合度 score求解
把x_transform放进去
把样本数据画一下,看拟合情况
散点画完了,画预测线, x传进来,需要有一个对应的y值
特征多了,也就是复杂度越来越多

通过多项式扩展 解决了欠拟合的问题
Why能这么做?
输入的时候特征比较少,所以咱么就给它映射到更高维的空间(超平面)
咱们拟合的能力就会变强
维度越高,越能捕获更多的数据
二维图来看,线的弯曲程度越高
7. 引入流水线方法(附代码)
在上例中,我们使用多项式对训练数据进行了转换(扩展),然后使用线性回归类(LinearRegression)在转换后的数据上进行拟合。可以说,这是两个步骤。我们虽然可以分别去执行这两个步骤,然而,当数据预处理的工作较多时,可能会涉及更多的步骤(例如标准化,编码等),此时再去一一执行会显得过于繁琐。
流水线(Pipeline类)可以将每个评估器视为一个步骤,然后将多个步骤作为一个整体而依次执行,这样,我们就无需分别执行每个步骤。流水线中的所有评估器(除了最后一个评估器外)都必须具有转换功能(具有transform方法)。
流水线具有最后一个评估器的所有方法。当调用某个方法f时,会首先对前n - 1个(假设流水线具有n个评估器)评估器执行transform方法(如果调用的f是fit方法,则n-1个评估器会执行fit_transform方法),对数据进行转换,然后在最后一个评估器上调用f方法。
例如,当在流水线上调用fit方法时,将会依次在每个评估器上调用fit方法,然后再调用transform方法,接下来将转换之后的结果传递给下一个评估器,直到最后一个评估器调用fit方法为止(最后一个评估器不会调用transform方法)。而当在流水线上调用predict方法时,则会依次在每个评估器上调用transform方法,最后在最后一个评估器上调用predict方法。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
# sklearn库提供的流水线类,作用就是将多个评估器打包成一个整体,这样,当我们对流水线进行某些操作时,
# 流水线内的所有评估器都会执行相关的操作。这样,就可以作为一个整体而执行,无需我们分别对每个评估器
# 单独进行执行。
from sklearn.pipeline import Pipeline
mpl.rcParams["font.family"] = "SimHei"
mpl.rcParams["axes.unicode_minus"] = False
x = np.linspace(0, 10, 50)
y = x * np.sin(x)
X = x[:, np.newaxis]
# 定义流水线中的每一个评估器。
# 格式为一个含有元组的列表。每个元组定义流水线中的一个步骤。
# 元组中含有两个元素。前面的元素为流水线步骤的名称,后面的
# 元素为该流水线步骤处理的对象。
estimators = [("poly", PolynomialFeatures()), ("lr", LinearRegression())]
# 创建流水线对象,将评估器数组传递给流水线类。
pipeline = Pipeline(estimators)
# 流水线的steps属性,可以返回流水线所有的步骤。包括步骤名与该步骤的处理对象。
# pipeline.steps
# 流水线的named_steps属性,与steps属性相似,只是类型不同(字典类型)。
# pipeline.named_steps
# 设置流水线对象的参数信息。
# 如果需要为流水线的某个步骤处理对象设置相关的参数,则参数名为:步骤名__处理对象参数。
pipeline.set_params(poly__degree=8)
# 获取流水线支持设置的所有参数。
# print(pipeline.get_params())
# 在流水线对象上调用fit方法,相当于对除了最后一个评估器之外的所有评估器调用fit_transform方法,
# 然后最后一个评估器调用fit方法。
pipeline.fit(X, y)
# 流水线对象具有最后一个评估器的所有方法。
# 当通过流水线对象,调用最后一个评估器的方法时,会首先调用之前所有评估器的transform方法。
score = pipeline.score(X, y)
plt.title(f"8阶,拟合度:{score:.3f}")
plt.scatter(X, y, c="g", label="样本数据")
# 当调用流水线对象的predict方法时,除最后一个评估器外,其余评估器会调用transform方法,然后,最后
# 一个评估器调用predict方法。
plt.plot(X, pipeline.predict(X), "r-", label="拟合线")
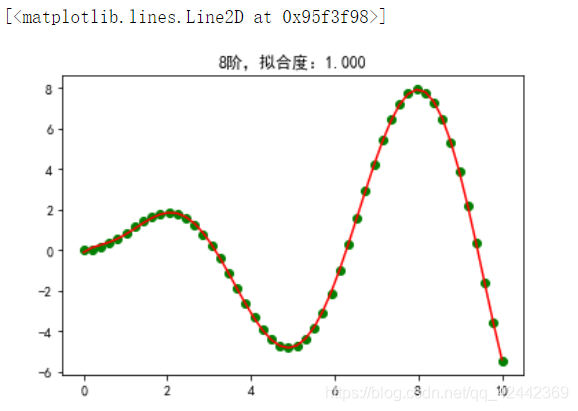
第一步:
使用多项式进行扩展。
第二步:
使用线性回归类,对多项式扩展之后的结果,进行训练,
预测结果。
但是再实际的机器学习过程中,可能更复杂
数据预处理,很多步骤
流水线 封罐头 很多步 都能作为一个整体进行操作
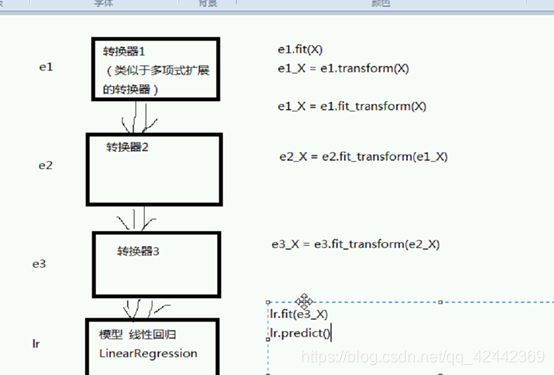
这个操作太繁琐
直接打包进 流水线,然后流水线调用fit就行了,流水线除了最后一个调用fit其他都会调用fit transform
最后是predict,不是fit
哪怕不是进行流水线,我们永远都是在训练集上进行fit,
我们现在调用predict的,实在测试集上,不要再训练集上fit
测试
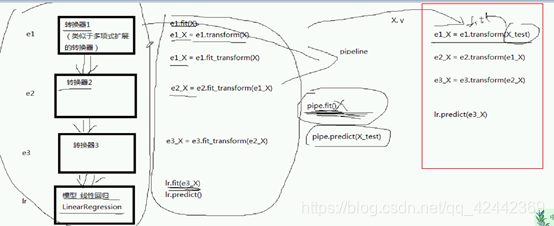
看一下流水线的程序
之前是分成2步的,现在我们分成一步实现
新库

执行什么操作呢?
定义流水线 里面的 每一个评估器
是一个含有元组的列表
后面是评估期的对象
名字 步骤要处理的对象
创建流水线对象 把相关评估器数组 传递给流水线内
步骤

名字 对象 顺便把默认的参数也显示出来
单独的想看流水线的处理对象,用这种 字典的方法

每个步骤有了,获得相关步骤就很简单


两部一起完成了


之前是 转换之后的



流水线的类 pipeline 很有用,放到一起,统一执行。
优势:
1.放到一起
2. 可以设置参数