BeautifulSoup插件的使用
这个插件需要先使用pip安装(在上一篇中不再赘言),然后再程序中申明引用
from bs4 import BeautifulSoup html=self.requests(url)#调用requests函数把套图地址传入会返回一个response all_a=BeautifulSoup(html.text,'lxml').find('div',class_='all').find('li').find_all('a')
这里find方法只会查找第一个匹配的元素,所以返回的是一个对象,find_all方法会查找所有匹配的元素,所以返回的是list
在使用网页文本的时候用text,在下载多媒体文件的时候用content。
正式编程
这里对程序进行了一些封装,方便函数的复用
ps:不得不感叹,python的io操作真的是很好用,简单方便,敲几下键盘就搞定,比起C#的各种参数真是太简洁!!!
import requests from bs4 import BeautifulSoup import os class mzitu(): def __init__(self): self.headers={'User-Agent':'Mozilla/5.0(Windows NT 6.2;WOW64)AppleWebKit/535.24(KHTML,like Gecko)Chrome/19.0.1055.1 Safari/535.24'} #self.route="D:\GITHUB\学习Python\爬虫基础教程mzitu\mzitu" def all_url(self,url): html=self.requests(url)#调用requests函数把套图地址传入会返回一个response all_a=BeautifulSoup(html.text,'lxml').find('div',class_='all').find('li').find_all('a') for a in all_a: title=a.get_text() print(u'开始保存:',title)#加一点提示,不然太枯燥了 path=str(title).replace("?",'_') path = str(title).replace("?", '_') ##我注意到有个标题带有 ? 这个符号Windows系统是不能创建文件夹的所以要替换掉 if self.mkdir(path):#调用mkdir函数创建文件夹 href=a['href'] self.html(href)#调用html函数把href参数传递过去 print(u'共找到资源:',len(all_a),u'组') def html(self,href): ##这个函数是处理套图地址获得图片的页面地址 html=self.requests(href)#调用requests函数 self.headers['referer']=href max_span=BeautifulSoup(html.text,'lxml').find('div',class_='pagenavi').find_all('span')[-2].get_text() for page in range(1,int(max_span)+1): page_url=href+'/'+str(page) self.img(page_url)#调用img函数 def img(self,page_url): ##这个函数处理图片页面地址获得图片的实际地址 img_html=self.requests(page_url) img_url=BeautifulSoup(img_html.text,'lxml').find('div',class_='main-image').find('img')['src'] self.save(img_url)#调用save函数 def save(self,img_url): ##这个函数保存图片 name=img_url[-9:-4] img=self.requests(img_url) f=open(name+'.jpg','ab') f.write(img.content) f.close() def mkdir(self,path): ##这个函数创建文件夹 path=path.strip() isExists=os.path.exists(os.path.join("D:\GITHUB\学习Python\爬虫基础教程mzitu\mzitu",path))#创建一个存放套图的文件夹 if not isExists: print(u'创建了',path,u'文件夹!') os.makedirs(os.path.join("D:\GITHUB\学习Python\爬虫基础教程mzitu\mzitu",path)) os.chdir(os.path.join("D:\GITHUB\学习Python\爬虫基础教程mzitu\mzitu",path))#切换到目录 return True else: print(u'名字叫做',path,u'的文件夹已经存在了!') return False def requests(self,url): ##这个函数获取网页的response 然后返回 content=requests.get(url,headers=self.headers) return content Mzitu=mzitu()#实例化 Mzitu.all_url('http://www.mzitu.com/all')##给函数all_url传入参数 当作启动爬虫(就是入口)
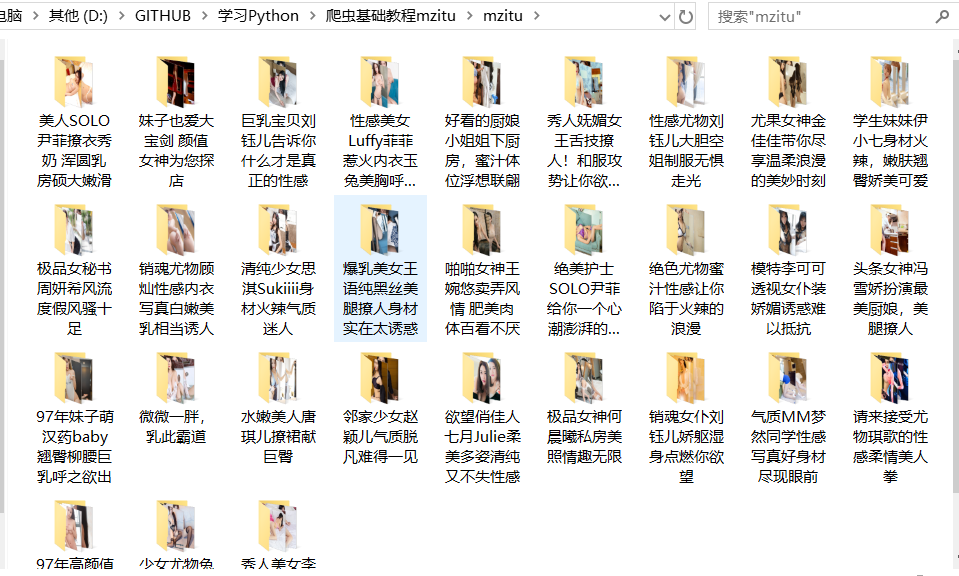
运行脚本,下载后到文件夹去看看,效果很惊艳!