beautifulsoup学习资料来自https://blog.csdn.net/wwq114/article/details/88085875
抓取结果为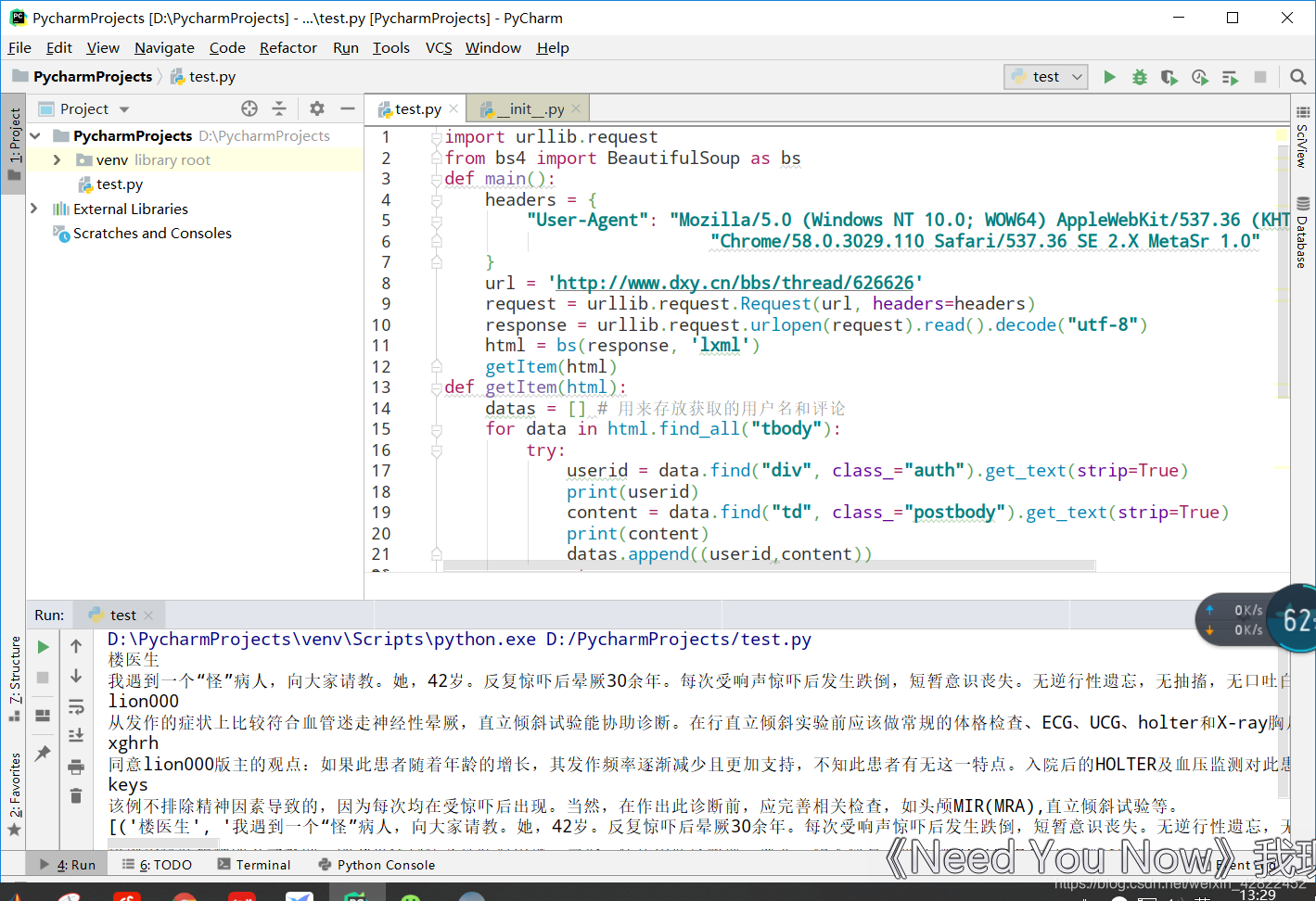
我尝试抓取了用户等级:
level = data.find(“div”,class_=“info clearfix”).get_text(strip=True)

xpath学习资料来自https://blog.csdn.net/naonao77/article/details/88129994
抓取结果为

我尝试抓取了用户等级:
level = tree.xpath(’//div[@class=“info clearfix”]/p//text()’)
抓取结果为
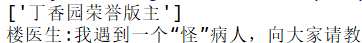
python爬虫学习test2-学习beautifulsoup、学习xpath
猜你喜欢
转载自blog.csdn.net/weixin_42822452/article/details/89144770
今日推荐
周排行