一.关于层叠样式表(CSS)
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。CSS不仅可以静态地修饰网页,还可以配合各种脚本语言动态地对网页各元素进行格式化。
CSS可以让HTML元素呈现出差异化,使具有完全相同修饰的元素呈现出不同的样式。
二.通过属性查找标签
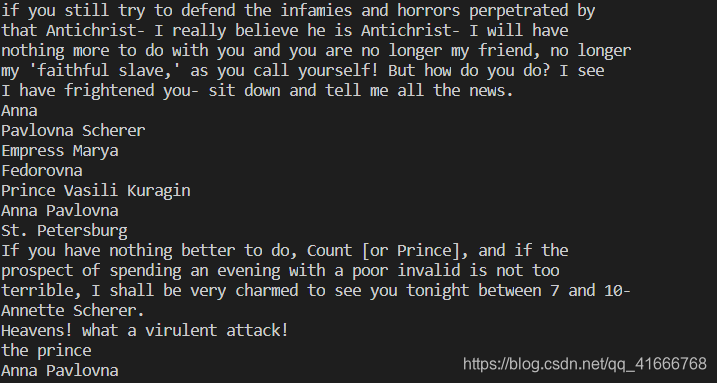
1.创建一个爬虫来抓取网页:http://www.pythonscraping.com/pages/warandpeace.html
这个页面是《战争与和平》的一个选段,其中对话内容都是红色文字,而人物名称都是绿色文字,如图:

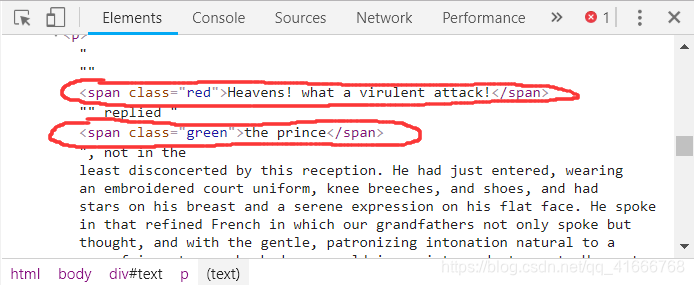
- 我们可以查看网页源代码里的span标签,引用了对应的CSS属性:
- 抓取整个页面,然后创建一个BeautifulSoup对象,方法和之前的程序类似:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsObj = BeautifulSoup(html)
- 通过BeautifulSoup对象,可以利用findAll()函数抽取包含在
<span class="green"></span>
这个标签中的文字,这样就可以得到一个人物名称的列表:
nameList = bsObj.findAll("span", {"class": "green"}) # bsObj.findAll(tagName,tagAttributes)可以获取页面中所有指定的标签
for name in nameList:
print(name.get_text()) # .get_text()函数会把HTML文档中的所有标签和超链接等全部删除,只剩下一段文字
.get_text()函数会把你正在处理的HTML文档中所有的标签都清除,然后返回一个只含有文字的字符串,通常在准备打印,存储,和操作数据时,应该最后才使用这个函数。一般情况下,应该尽可能的保留与HTML文档的标签结构
- 运行结果如下:
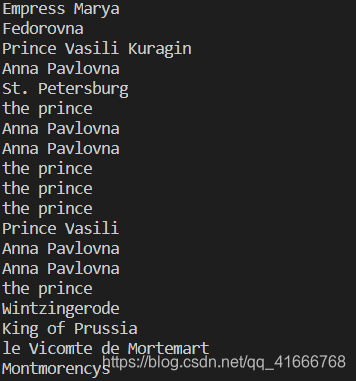
页面中的人物名称就都被我们提取出来了。
2. findAll()函数详解
findAll()函数是一个十分灵活的函数,我们会经常用到它,借助这个函数,我们可以通过标签的不同属性轻松过滤HTML页面,查找需要的标签组或者单个标签。
BeautifulSoup文档里对于findAll()函数的定义是这样的:
findAll(tag,attributes,recursive,text,limit,keywords)
在95%的时间当中,我们都只需要用到前两个参数:tag和attributes;
但是我们还是应该仔细地观察所有的参数:
- 标签tag: 我们可以传入一个标签的名称或者由多个标签名称组成的python列表作为参数。例如,下面的代码将返回一个包含在HTML文档中所有标题标签的列表:
allTitle = bsObj.findAll({"h1", "h2", "h3", "h4", "h5", "h6"})
for title in allTitle:
print(title)
结果如图:

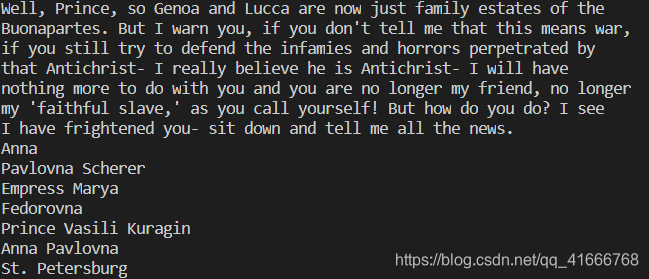
- 属性参数attributes: 用一个python字典封装一个标签的若干属性和对应的属性值。例如,下面的代码回返回HTML文档中红色与绿色两种颜色的span标签:
text = bsObj.findAll("span", {"class":{"green", "red"}})
for a in text:
print(a.get_text())#输出了页面中所有红色和绿色的文字
如图:
-
递归参数recursive:是一个布尔变量,如果recursive设置为true,则findAll会根据你的要求查找标签参数的所有子标签,以及后代标签。如果设置为false,findAll就只查找文档的一级标签。一般这个参数不需要设置。
-
文本参数text:用标签的文本内容去匹配,而不是属性。假如我们想查找前面网页中包含"the prince"内容的标签数量,则可以用下面的方法实现:
nameList = bsObj.findAll(text="the prince")
print(len(nameList))#输出结果为7
-
范围限制参数limit:如果只对网页中获取的前x项结果感兴趣,就可以设置它。
-
关键词参数keyword:可以让你选择具有指定属性的标签,例如:
allText = bsObj.findAll(id="text") # 选择具有指定属性的标签
print(allText[0].get_text())
如图: