1、fiddler的使用
(1)右上是HTTP请求信息,
右下是http响应信息,点击黄色条解码
(2)Raw请求详细信息,raw响应所有信息
(3)webForms请求所带参数
(4)json接口响应内容

2、urllib库:模拟浏览器发送请求的库,python自带
(1)urllib.request
| 属性 | 作用 |
|---|---|
| encode | 如果写,你就写gbk,如果小括号里不写参数,默认utf-8 |
| decode | 如果不写,默认utf-8,如果写,写gbk |
| read | 读取相应内容,内容是字节类型 |
| geturl | 根据响应内容,获取请求的url |
| getheaders | 获取头部信息,列表里都是元组 |
| getcode | 获取状态码 |
| readlines | 按行读取,返回列表,都是字节类型 |
(2)urllib.parse
| 属性 | 作用 |
|---|---|
| quote() | url编码函数 |
| unquote | 解码函数,将%xxx指定字符 |
| unlencode | 给一个字典,将字典拼接成query_string并且实现了编码的功能 |
3、反爬:构建请求头部信息
(1)伪装自己是UA,让服务器认为你是浏览器上网
(2)构建请求对象,urllib.request.Request
4、post表单数据处理
form_data=urllib.parse.urllencode(form_data).encode()
import urllib.request
import urllib.parse
# 获取posturl的网址
post_url = "http://fanyi.baidu.com/sug"
word = input("请输入您想要查询的英文单词:")
# word = "baby"
# 构建post表单的数据
form_data = {
"kw": word,
}
# 发送请求的过程
# headers = {
# "Mozilla/5.0 (Windows NT 10.0; WOW64)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/63.0.3239.132 Safari/537.36",
# }
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/63.0.3359.181 Safari/537.36",
}
# 构建请求对象
request = urllib.request.Request(url=post_url, headers=headers)
# 处理post表单数据
form_data = urllib.parse.urlencode(form_data).encode()
# 发送请求
response = urllib.request.urlopen(request, data=form_data)
print(response.read().decode)
import urllib.request
import urllib.parse
post_url = "http://fanyi.baidu.com/v2transapi"
form_data = {
'from': 'en',
'to': 'zh',
'query': 'baby',
'transtype': 'translang',
'simple_means_flag': '3',
'sign': '814534.560887',
'token': 'bbcbfd9569acc55a96311f2c873f7e0b',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Host': 'fanyi.baidu.com',
'Connection': 'keep-alive',
}
request = urllib.request.Request(url=post_url, headers=headers)
form_data = urllib.parse.urlencode(form_data).encode()
response = urllib.request.urlopen(request, form_data)
print(response.read().decode("gbk"))
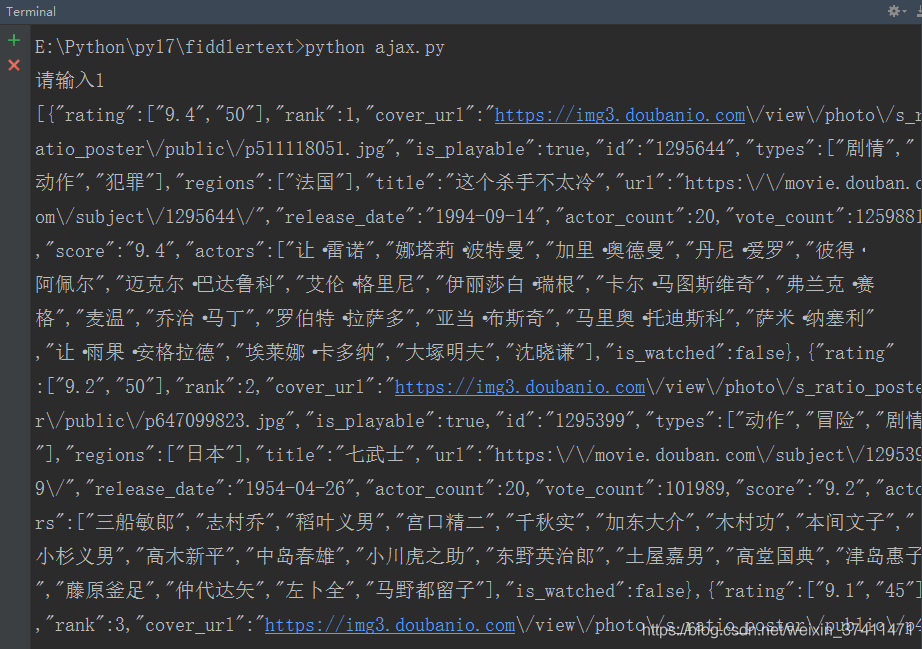
5、(1)ajax-get
import urllib.request
import urllib.parse
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&"
page = int(input("请输入"))
number = 20
data = {
"start": (page - 1) * number,
"limit": number,
}
# 将字典转化为query_string
query_string = urllib.parse.urlencode(data)
# 修改url
url += query_string
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode())
(2)ajax-post
import urllib.request
import urllib.parse
post_url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname"
city = input("请输入要查询的城市:")
page = input("请输入第几页:")
size = input("请输入要多少个:")
fromdata = {
"cname": city,
"pid": " ",
"pageIndex": page,
"pageSize": size,
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
}
request = urllib.request.Request(url=post_url, headers=headers)
fromdata = urllib.parse.urlencode(fromdata).encode()
response = urllib.request.urlopen(request, data=fromdata)
print(response.read().decode())
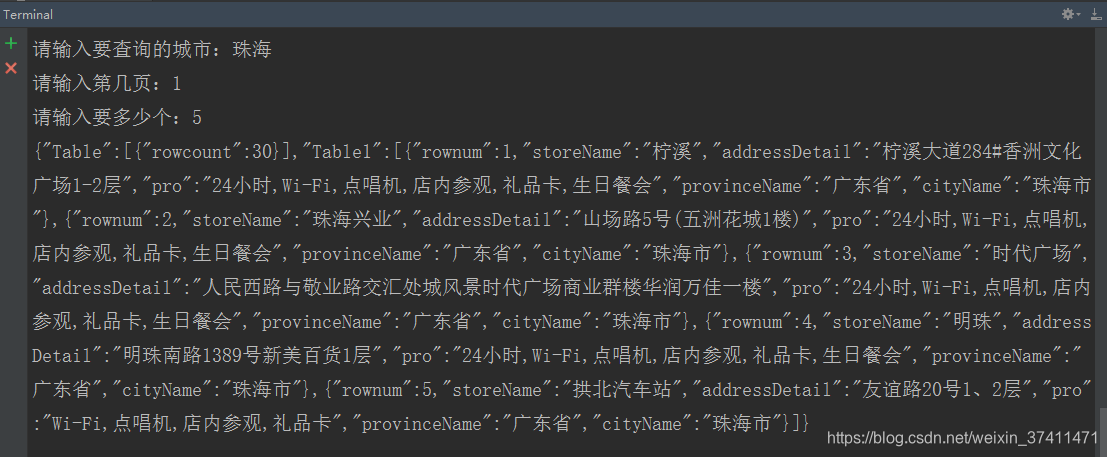
(3)复杂get
需求:
输入吧名,输入起始页码,输入结束页码,
然后在当前文件夹中创建一个以吧名为名字的文件夹,;里面是每一页的html内容
文件名是吧名_page.html
import urllib.request
import urllib.parse
import os
url = "http://tieba.baidu.com/f?ie=utf-8"
"""
1 pn==0
2 pn==50
3 pn==100
4 pn==150
5 pn==(n-1)*50
"""
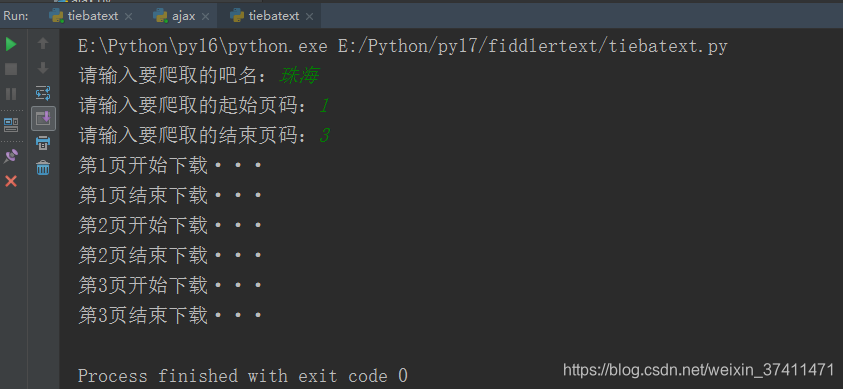
baidu_name = input("请输入要爬取的吧名:")
start_page = int(input("请输入要爬取的起始页码:"))
end_page = int(input("请输入要爬取的结束页码:"))
if not os.path.exists(baidu_name):
os.mkdir(baidu_name)
# 依次爬取每一页
for page in range(start_page, end_page + 1):
data = {
"kw": baidu_name,
"pn": (page - 1) * 50
}
data = urllib.parse.urlencode(data)
url_t = url + data
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
}
request = urllib.request.Request(url=url_t, headers=headers)
print("第%s页开始下载···" % page)
response = urllib.request.urlopen(request)
filename = baidu_name + "_" + str(page) + ".html"
filepath = baidu_name + "/" + filename
with open(filepath, "wb") as fb:
fb.write(response.read())
print("第%s页结束下载···" % page)

6、URLError
(1)没有网
(2)服务器连接失败
(3)找不到指定服务器
7、HTTPError:是URLError的子类,两个同时捕获,需要将HTTPError写到上面,把URLError写到上面
8、urlopen()给定一个url。发送请求,获取响应
Request()定制请求头,创建请求对象