MySQL的单表达到多少量级时性能会下降?宽表在千万量级,窄表要好一点在1200W左右。但是MySQL单表达到1500W时性能开始急剧下降!
事实上MySQL单表可以存储10亿级数据,只是这时候性能比较差,业界公认MySQL单表容量在1KW以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
既然一张表无法搞定,那么就想办法将数据放到多个地方,目前比较普遍的方案有3个:分区;分库分表;NoSQL/NewSQL。NoSQL比较具有代表性的是MongoDB,es。NewSQL比较具有代表性的是TiDB。
那么为什么不采用分区?
分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样(所有的底层表都必须使用相同的存储引擎),分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分。
事实上,这个方案也不错,它对用户屏蔽了sharding的细节,即使查询条件没有sharding column,它也能正常工作(只是这时候性能一般)。不过它的缺点很明显:很多的资源都受到单机的限制,例如连接数,网络吞吐等!从而导致它的并发能力非常一般,远远达不到互联网高并发的要求!另外其还不支持外键、全文索引。
介绍分库分表前,这里先抛出一道面试题:
Q1:一亿的用户表,怎么做优化?
Q2:两个实体,用户和订单,数据量都过亿
要求:
1.从用户角度快速查询订单
2.从订单角度快速查用户
怎么设计表?
【1】常见数据库中间件
分布式数据库中间件有TDDL、Sharding-JDBC 、Amoeba、Cobar以及MyCAT。目前MyCAT社区十分活跃。Mycat就是介于数据库与应用之间,进行数据处理与交互的中间服务。对数据进行分片处理之后,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成了整个完整的数据库存储。
用户可以把它看做是一个数据库代理,可以用MySQL客户端工具和命令行访问,其核心功能是分库分表,即将一个大表分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。理解MyCat与MySQL关系,可以联想一下Nginx和Tomcat关系。
分库分表中间件全部可以归结为两大类型:
- CLIENT模式;
- PROXY模式;
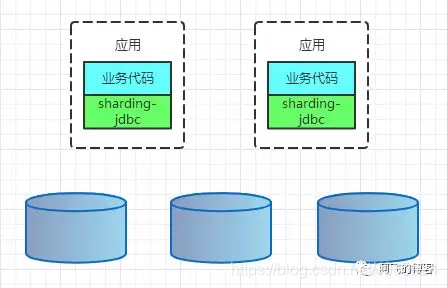
CLIENT模式代表有阿里的TDDL,京东金融的sharding-jdbc。架构如下:
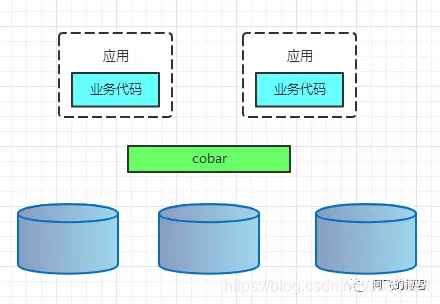
PROXY模式代表有阿里的cobar,民间组织的MyCAT。架构如下:
但是,无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
① 常见的数据库中间件对比

| 功能 | Sharding-JDBC | TDDL | Amoeba | Cobar | MyCat |
|---|---|---|---|---|---|
| 基于客户端还是服务端 | 客户端 | 客户端 | 服务端 | 服务端 | 服务端 |
| 分库分表 | 有 | 有 | 有 | 有 | 有 |
| MySQL交互协议 | JDBC Driver | JDBC Driver | 前端用NIO,后端用JDBC Driver | 前端用NIO,后端用BIO | 前后端均用NIO |
| 支持的数据库 | 任意 | 任意 | 任意 | MySQL | 任意 |
② 架构图
1、Sharding-JDBC
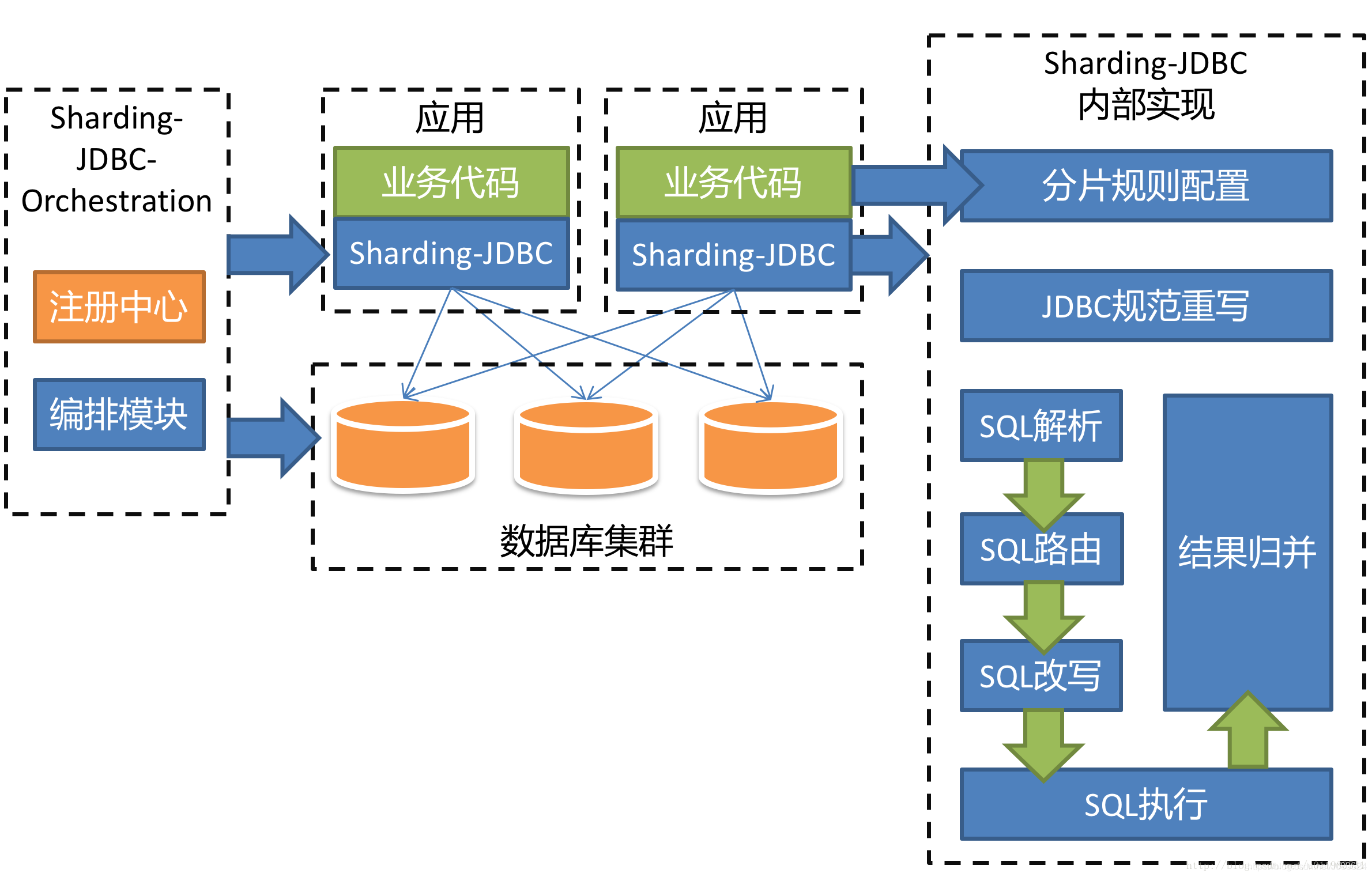
2、TDDL
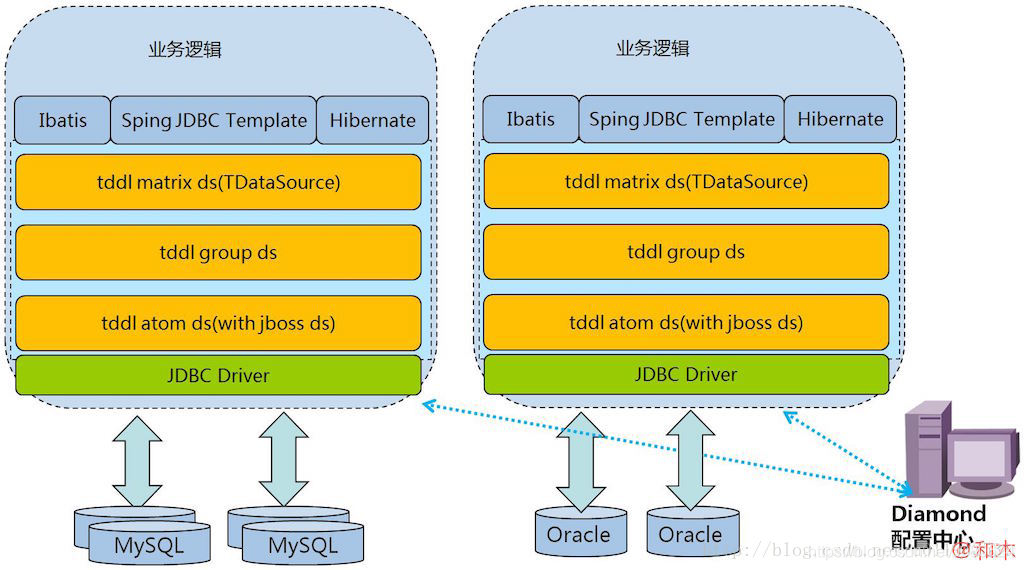
3、Amoeba
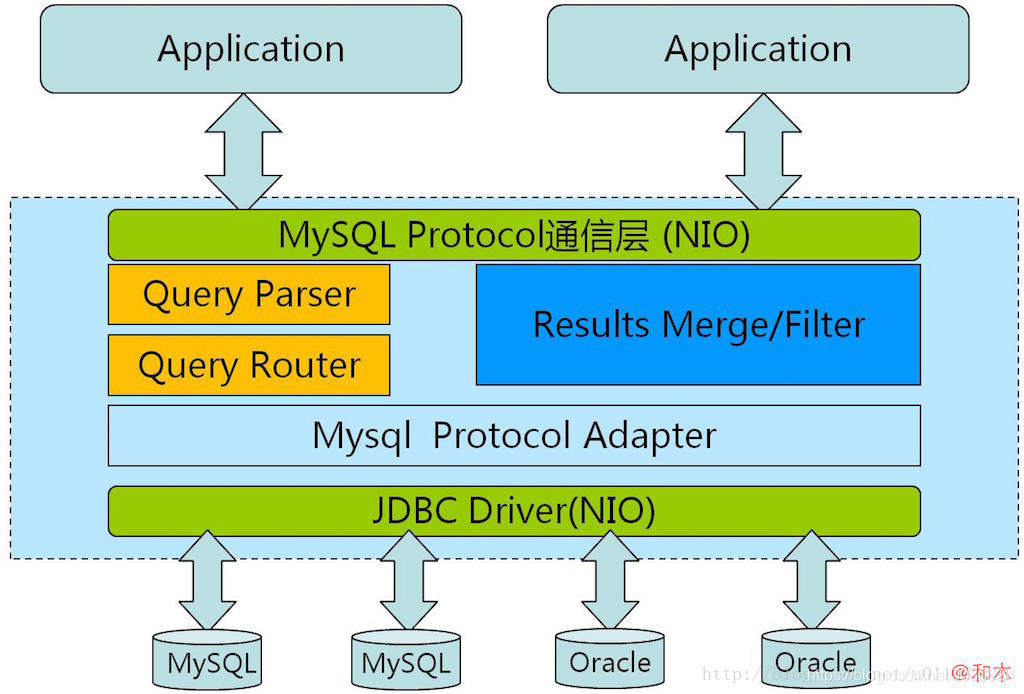
4、Cobar
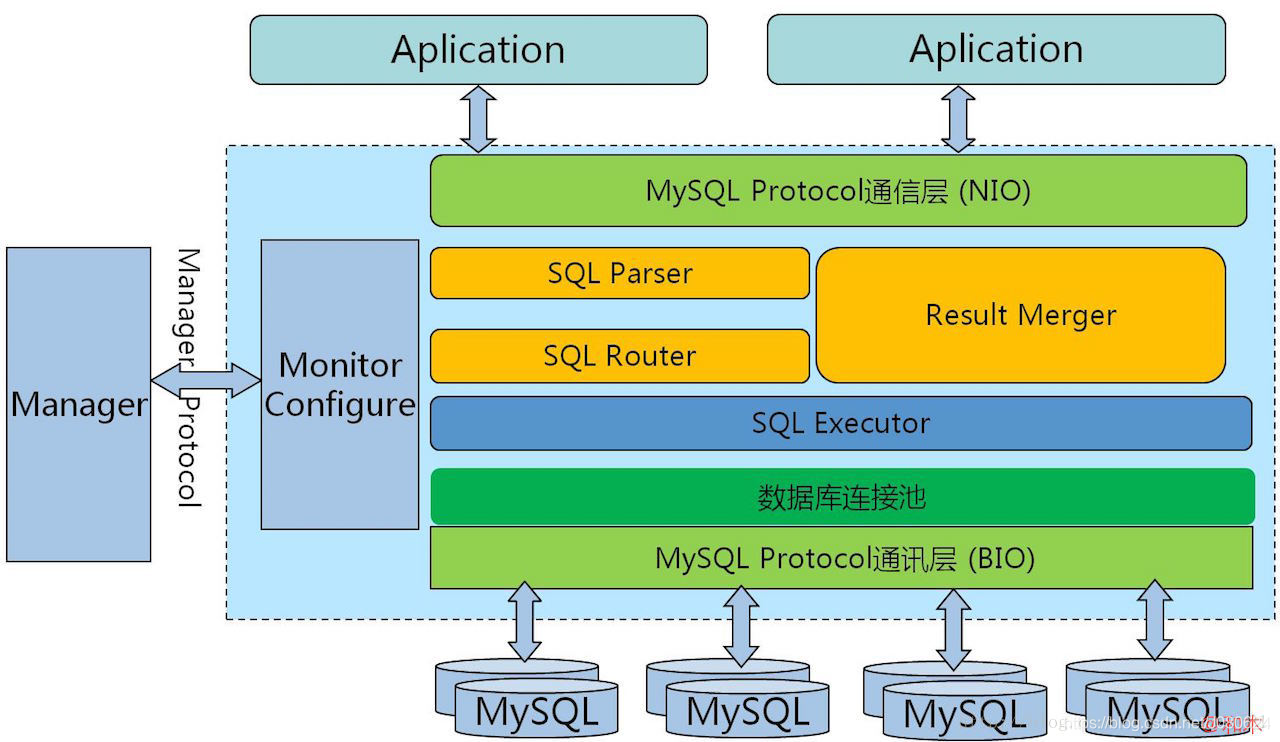
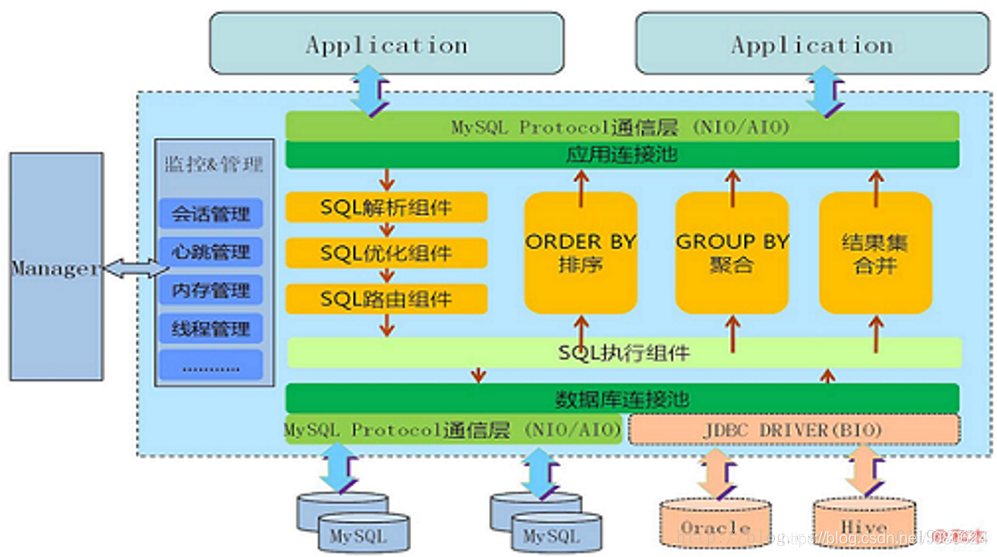
5、MyCat
③ 对比分析
TDDL 不同于其它几款产品,并非独立的中间件,只能算作中间层,是以 Jar 包方式提供给应用调用。属于JDBC Shard 的思想,网上也有很多其它类似产品。
Amoeba 是作为一个真正的独立中间件提供服务,即应用去连接 Amoeba 操作 MySQL 集群,就像操作 单个 MySQL 一样。从架构中可以看来,Amoeba 算中间件中的早期产品,后端还在使用 JDBC Driver。
Cobar 是在 Amoeba 基础上进化的版本,一个显著变化是把后端 JDBC Driver 改为原生的 MySQL 通信协议层。后端去掉 JDBC Driver 后,意味着不再支持 JDBC 规范,不能支持 Oracle、PostgreSQL 等数据。但使 用原生通信协议代替 JDBC Driver,后端的功能增加了很多想象力,比如主备切换、读写分离、异步操作等。
MyCat 又是在 Cobar 基础上发展的版本,两个显著点是:
(1)后端由 BIO 改为 NIO,并发量有大幅提高
(2)增加了对Order By、Group By、limit 等聚合功能的支持(虽然 Cobar 也可以支持 Order By、Group By、Limit 语法,但是结果没有进行聚合,只是简单返回给前端,聚合功能还是需要业务系统自己完成)。
【2】MyCat进行分库分表实践
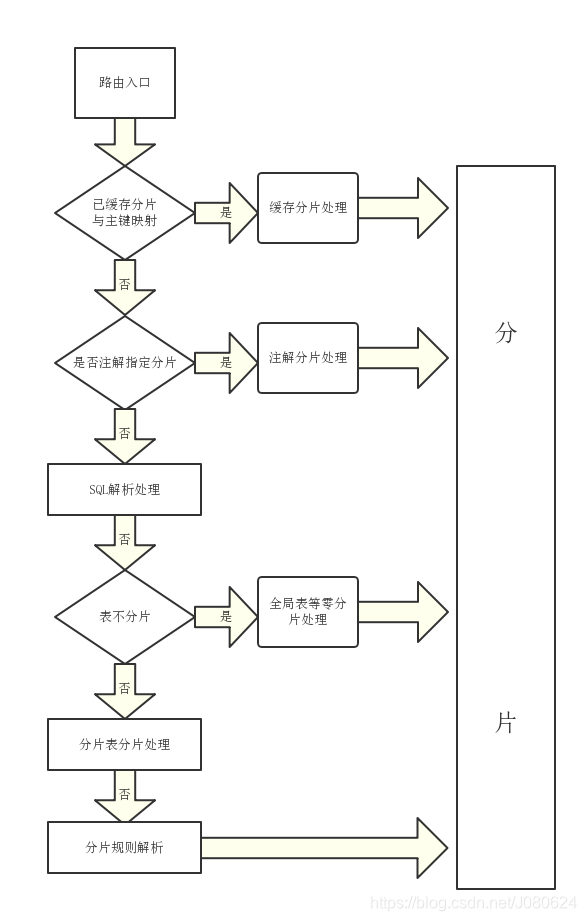
① MyCat的数据处理流程
② MyCat的下载和安装
下载地址:http://dl.mycat.io/

这里我们使用1.6:
不好意思,1.6有个bug,在单库分表中会提示partition size大于datanode size :
Caused by: io.mycat.config.util.ConfigException: Illegal table conf : table [
CUSTOMER_ORDER ] rule function [ mod-long ] partition size : 3 > table datanode size : 1,
please make sure table datanode size = function partition size
不要使用1.6版本,建议使用1.6.5版本!在这里坑我了半个小时!!
- 目录说明
| 目录 | 说明 |
|---|---|
| bin | mycat命令,启动、重启、停止等 |
| catlet | catlet为mycat的一个扩展功能 |
| conf | Mycat配置信息 |
| lib | Mycat引用的jar包,MyCat是Java开发的 |
| logs | 日志文件,包括MyCat启动的日志和运行的日志 |
- Windows下操作MyCat
//进入bin目录进行安装
mycat.bat install
//启动服务
mycat.bat start
//查看状态
mycat.bat status
//停止服务
mycat.bat stop
//登录mycat逻辑数据库
mysql -uroot -p123456 -P8066 -DTESTDB
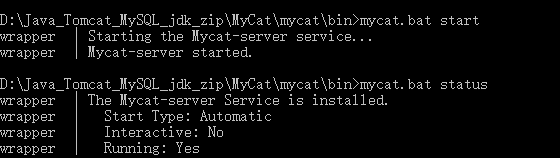
查看逻辑库和逻辑表:
此时这三个逻辑表并不存在,如下所示使用navicat连接mycat,双击customer将会提示如下:

③ 三个配置文件
MyCat的主要配置其实就在于3(或者说4)个文件的配置
- server.xml:mycat最基本的配置,配置连接的数据库和用户
- schema.xml:mycat中逻辑表的具体配置
- rule.xml : mycat中逻辑表需要分片的分片规则的配置文件
以及一个具体的分片规则txt文件。我这边命名为chen.txt。
Server.xml主要配置mycat服务的参数,比如端口号,myact用户名和密码使用的逻辑数据库以及用户管理。
<property name="serverPort">8066</property>
<property name="managerPort">9066</property>
<property name="idleTimeout">300000</property>
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
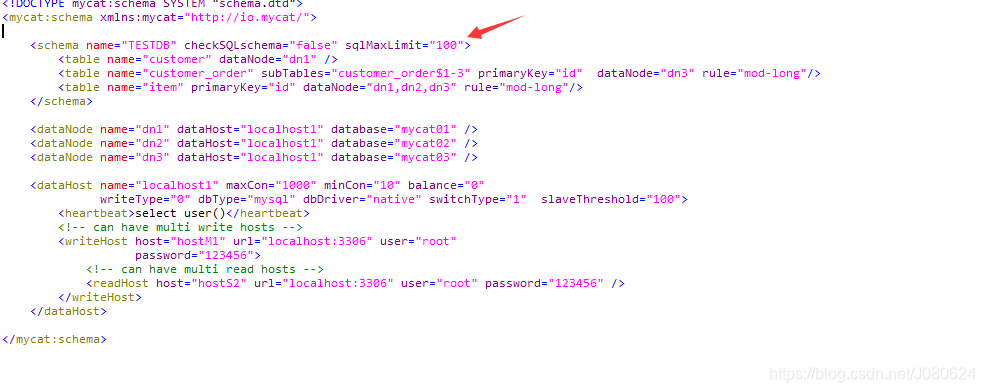
schema.xml文件主要配置数据库的信息,例如逻辑数据库名称,物理上真实的数据源以及表和数据源之间的对应关系和路由策略等。
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--
TESTDB对应Server.xml中的逻辑数据库的名称,item为物理数据库表的名称,id为表主键,
dataNode对应下面的dataNode的name,rule为分片规则,这边配置的是求模分片,如果要
多个分片结合,中间用逗号分隔
-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- customer表在dn1中不使用分库分表 -->
<table name="customer" dataNode="dn1" />
<!--item 在dn1 dn2 dn3上 分库-->
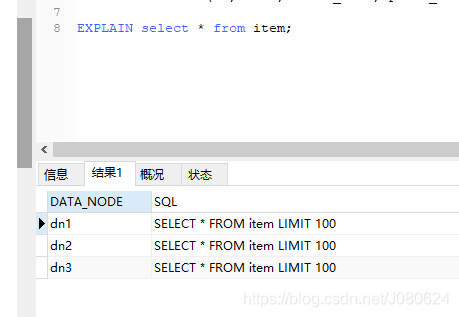
<table name="item" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long"/>
<!-- customer_order在dn3上id做分片 -->
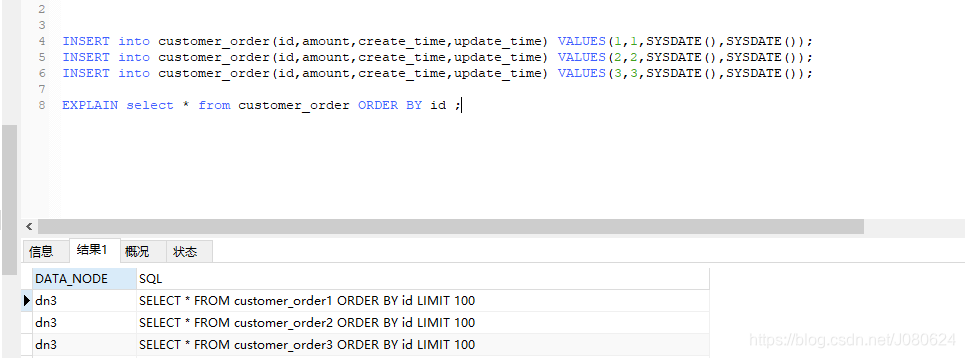
<table name="customer_order" primaryKey="ID" subTables="customer_order$1-3" dataNode="dn3" rule="mod-long"/>
</schema>
<!-- 设置节点对应的数据库以及物理连接主机-->
<dataNode name="dn1" dataHost="localhost1" database="mycat01" />
<dataNode name="dn2" dataHost="localhost1" database="mycat02" />
<dataNode name="dn3" dataHost="localhost1" database="mycat03" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="localhost:3306" user="root" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
rule.xml主要配置路由策略,主要有分片的片键,拆分的策略(取模还是按区间划分等)。
如下所示定义一个rule,name为"mod-long",算法实现为mod-long。
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
每一个tableRule都对应一个function节点,class为具体实现类:
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
【3】创建库和表进行测试
customer表不做分库分表,item表做分库操作,customer_order表在dn3-mycat03中做水平分表操作。
① 分别创建三个库mycat01,mycat02和mycat03。
② 在TESTDB中创建表
- 创建customer表(只在dn1-mycat01中存在,未做分库分表)
CREATE TABLE customer (
id int not null auto_increment PRIMARY key,
name varchar(20) default '' ,
phone varchar(12) default '',
create_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL
)ENGINE=INNODB DEFAULT charset=utf8
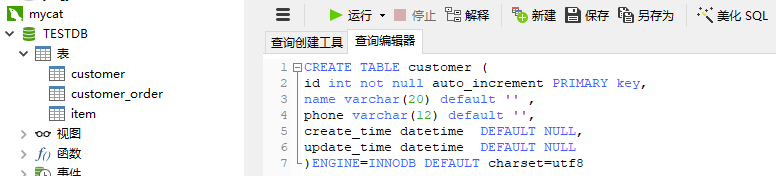
此时将会在物理库mycat01中创建表customer:
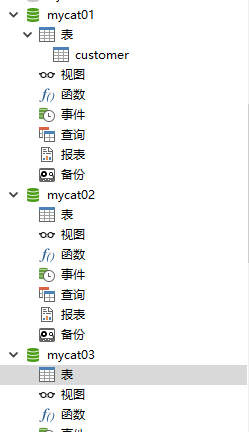
- 在TESTDB创建中执行脚本创建item表,mycat01 mycat02 mycat03都会创建
CREATE TABLE item (
id int not null auto_increment PRIMARY key,
value int default 0 ,
create_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL
)ENGINE=INNODB DEFAULT charset=utf8
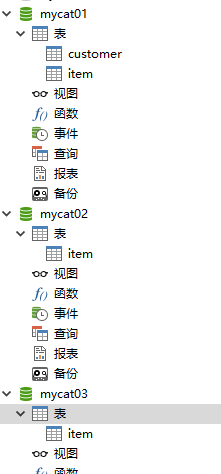
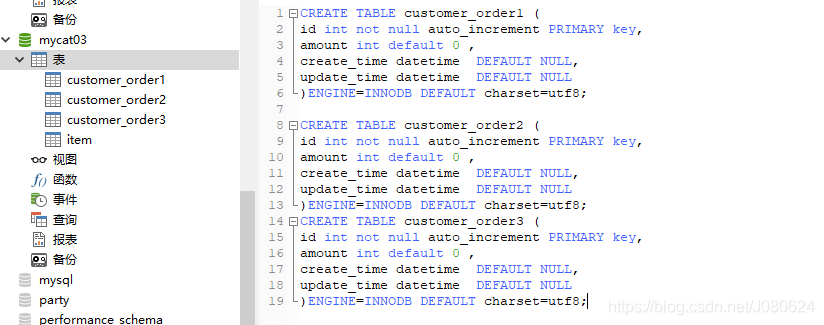
- 在mycat03中执行脚本创建三个表:
CREATE TABLE customer_order1 (
id int not null auto_increment PRIMARY key,
amount int default 0 ,
create_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL
)ENGINE=INNODB DEFAULT charset=utf8;
CREATE TABLE customer_order2 (
id int not null auto_increment PRIMARY key,
amount int default 0 ,
create_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL
)ENGINE=INNODB DEFAULT charset=utf8;
CREATE TABLE customer_order3 (
id int not null auto_increment PRIMARY key,
amount int default 0 ,
create_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL
)ENGINE=INNODB DEFAULT charset=utf8;
③ 测试customer插入和查询
插入:
INSERT into customer(name,phone,create_time,update_time)
VALUES ('jane','15369689516',SYSDATE(),SYSDATE());
查询:
select * from customer;
使用explain分析如下所示,会自动从对应节点中获取数据。
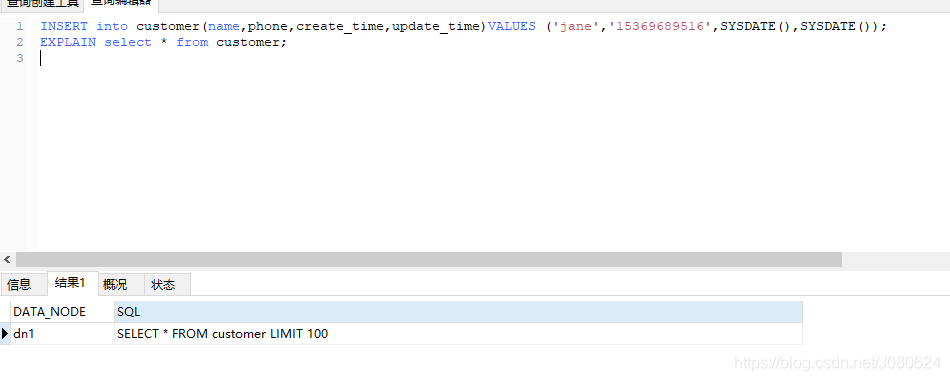
可能会疑惑,默认进行了limit 100 ,这个从哪里来?回顾Schema.xml配置:
④ 测试item插入和查询
插入语句:
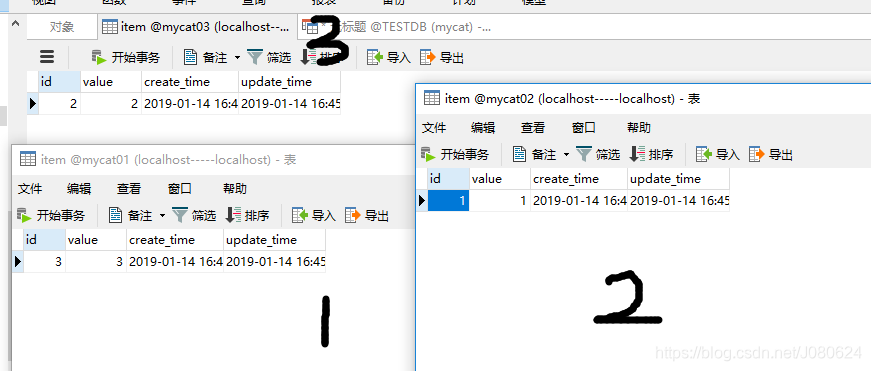
INSERT into item(id,value,create_time,update_time) VALUES(1,1,SYSDATE(),SYSDATE());
INSERT into item(id,value,create_time,update_time) VALUES(2,2,SYSDATE(),SYSDATE());
INSERT into item(id,value,create_time,update_time) VALUES(3,3,SYSDATE(),SYSDATE());
根据id 进行mod然后插入到三个库中:
查询分析如下所示:
⑤ 测试custom_order插入和查询
如下图所示:
⑥ 插入数据id不能省略
如果你的规则是根据id进行mod,那么在SQL插入的时候id一列必须赋值,不能使用MySQL的自动增长。
【4】SpringBoot整合MyBatis中使用Mycat
在【3】中我们所有插入和查询测试都是从TESTDB链接中进行查询的,所以SpringBoot整合MyBatis中使用Mycat十分简单,只需要替换一下URL!
spring:
datasource:
# 单库单表
url: jdbc:mysql://localhost:3306/test
# 分库分表
url:jdbc:mysql://localhost:8066/TESTDB
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: true
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
多数据源
另外一个问题是,不可能把所有的表都配置进Schema.xml中让mycat管理。那么就可以配置两个数据源!使用另外一个数据源来管理剩余的表。
【5】回到面试题
① 中间表user_order
维护一个中间表user_order来保持用户和订单的关系,如果中间表膨胀,对中间关系表进行分表。但是此时逻辑就变得更复杂了。如果要求从userId,orderId,shopId。。等维度做分表,那么中间表的数据就会急剧上升Cn2
② 对user_order关系表根据userId做分表

此时根据userId可以很好命中数据,但是如果根据orderId呢?
③ 对user_oder表分表根据userId和orderId进行分表
也就是将一份数据根据不同规则保存两份,以空间换时间!
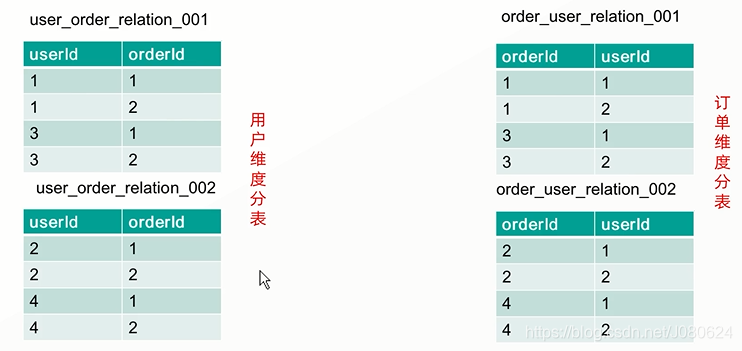
那么在具体操作上是不是分别插入两遍呢?当然不是!
为了保证数据准确性,数据只需要写入一份。另一份分表的数据通过binlog进行回放(binlog记录所有的对表的insert,update和delete操作,回放就是将这些对数据库的更新操作,再执行一遍)。
④ 为什么不是Sharing-JDBC呢?
Sharing-JDBC是需要修改代码的,而mycat只需要修改一下URL!
【6】一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂Slave,通过此方式可以有效的提高DB集群的QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以,1.当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。2.当写压力很大的时候,就必须得进行分库操作。