1.Mycat是什么
1)关系型数据库
2)非关系型数据库
key-value: redis 、memcache ; 面向文档: mongoDB ;面向列: HBase
3)数据切分
mycat、 TDDL、 Sharding-JDBC、cobar
2.Mycat安装部署配置
2.1 安装部署
2.1.1安装
mycat解压安装、mycat环境变量设置
2.1.2启动参数
1)bin目录的启动脚本内存配置 /bin/startup_nowrap
-server -Xms2G -Xmx2G -XX:MaxPermSize=64M -XX:+AggressiveOpts -XX:MaxDirectMemorySize=2G
2)conf目录的wrapper.conf配置
jvm参数调优,以16G内存服务器为例
# Java Additional Parameters
#wrapper.java.additional.1=
wrapper.java.additional.1=-DMYCAT_HOME=.
wrapper.java.additional.2=-server
wrapper.java.additional.3=-XX:MaxPermSize=64M
wrapper.java.additional.4=-XX:+AggressiveOpts
#堆内存适度大小,直接映射内存尽可能大,两种一起占据服务器的1/2-2/3的内存
wrapper.java.additional.5=-XX:MaxDirectMemorySize=6G
wrapper.java.additional.6=-Dcom.sun.management.jmxremote
wrapper.java.additional.7=-Dcom.sun.management.jmxremote.port=1984
wrapper.java.additional.8=-Dcom.sun.management.jmxremote.authenticate=false
wrapper.java.additional.9=-Dcom.sun.management.jmxremote.ssl=false
#无论扩展还是缩减新生代空间或老年代空间都需要进行Full GC,而Full GC会降低程序的吞吐量并导致更长的延迟。
wrapper.java.additional.10=-Xmx4G
wrapper.java.additional.11=-Xms4G2)配置完之后即可启动
2.2 配置
3个主要配置文件
schema.xml 中定义逻辑库,表、分片节点等内容
rule.xml 中定义分片规则
server.xml 中定义用户以及系统相关变量,如端口等
2.2.1 server.xml
server.xml 几乎保存了所有 mycat 需要的系统配置信息。其在代码内直接的映射类为 System Config 类。正常只需修改用户名密码
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">test_schema</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="test_schema" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">test_schema</property>
<property name="readOnly">true</property>
</user>
2.2.2 schema.xml
schema 标签用于定义 My Cat 实例中的逻辑库,My Cat 可以有多个逻辑库,每个逻辑库都有自己的相关配
置。可以使用 schema 标签来划分这些不同的逻辑库。
<?xml version="1.0" ?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 设置表的存储方式.schema name="test_schema" 与 server.xml中的 test_schema 设置一致 -->
<schema name="test_schema" checkSQLschema="false" sqlMaxLimit="100">
<!--rule对应rule.xml中的配置-->
<table name="test_one" primaryKey="id" dataNode="dn$1-3" rule="sharding-by-date"/>
</schema>
<!-- 设置dataNode 对应的数据库,及 mycat 连接的地址dataHost -->
<dataNode name="dn1" dataHost="dh_test" database="db_1"/>
<dataNode name="dn2" dataHost="dh_test" database="db_2"/>
<dataNode name="dn3" dataHost="dh_test" database="db_3"/>
<!-- mycat 逻辑主机dataHost对应的物理主机.其中也设置对应的mysql登陆信息 -->
<dataHost name="dh_test" maxCon="1000" minCon="10" balance="0" writeType="0"
dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<!--<heartbeat>select user()</heartbeat>-->
<heartbeat>show slave status</heartbeat>
<writeHost host="hostM1" url="192.168.252.121:3306" user="root" password="mima">
<readHost host="hostS2" url="192.168.252.122:3306" user="root" password="mima"/>
</writeHost>
</dataHost>
</mycat:schema>如上所示的配置就配置了1个逻辑库,逻辑库的概念和 MYSQL 数据库中 Database 的概念相同,我们在查询这个逻辑库中表的时候需要切换到该逻辑库下才可以查询到所需要的表。
schema 标签
用于定义 My Cat 实例中的逻辑库,My Cat 可以有多个逻辑库,每个逻辑库都有自己的相关配
置。可以使用 schema 标签来划分这些不同的逻辑库。
data Node 属性
该属性用于绑定逻辑库到某个具体的 database 上,1.3 版本如果配置了 data Node,则不可以配置分片表,
1.4 可以配置默认分片,只需要配置需要分片的表即可
data Host 标签
作为 Schema.xml 中最后的一个标签,该标签在 mycat 逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。现在我们就解析下这个标签。
name 属性
唯一标识 data Host 标签,供上层的标签使用。
max Con 属性
指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的 write Host、read Host 标签都会使用这个属性的值来实例化出连接池的最大连接数。
min Con 属性
指定每个读写实例连接池的最小连接,初始化连接池的大小。
balance 属性
负载均衡类型,目前的取值有 3 种:
1.balance=”0”, 不开启读写分离机制,所有读操作都发送到当前可用的 write Host 上。
2.balance=”1”,全部的 read Host 与 stand by write Host 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载
均衡。
3.balance=”2”,所有读操作都随机的在 write Host、readhost 上分发。
4.balance=”3”,所有读请求随机的分发到 wiriter Host 对应的 readhost 执行,writer Host 不负担读压
力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
write Type 属性
负载均衡类型,目前的取值有 3 种:
- write Type=”0”, 所有写操作发送到配置的第一个 write Host,第一个挂了切到还生存的第二个write Host,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
- write Type=”1”,所有写操作都随机的发送到配置的 write Host,1.5 以后废弃不推荐。
**switch Type 属性
-1 表示不自动切换
1 默认值,自动切换
2 基于 My SQL 主从同步的状态决定是否切换
db Type 属性
指定后端连接的数据库类型,目前支持二进制的 mysql 协议,还有其他使用 JDBC 连接的数据库。例如:mongodb、oracle、spark 等。
db Driver 属性
指定连接后端数据库使用的 Driver,目前可选的值有 native 和 JDBC。使用 native 的话,因为这个值执行的是二进制的 mysql 协议,所以可以使用 mysql 和 maridb。其他类型的数据库则需要使用 JDBC 驱动来支持。
从 1.6 版本开始支持 postgresql 的 native 原始协议。
如果使用 JDBC 的话需要将符合 JDBC 4 标准的驱动 JAR 包放到 MYCATlib 目录下,并检查驱动 JAR 包中包括如下目录结构的文件:META-INFservicesjava.sql.Driver。在这个文件内写上具体的 Driver 类名,例如:com.mysql.jdbc.Driver。
switch Type 属性
-1 表示不自动切换
1 默认值,自动切换
2 基于 My SQL 主从同步的状态决定是否切换 心跳语句为 show slave status
3 基于 My SQL galary cluster 的切换机制(适合集群)(1.4.1) 心跳语句为 show status like ‘wsrep%’.
temp Read Host Available 属性
如果配置了这个属性 write Host 下面的 read Host 仍旧可用,默认 0 可配置(0、1)
2.2.3 rule.xml
rule.xml 里面就定义了我们对表进行拆分所涉及到的规则定义。我们可以灵活的对表使用不同的分片算法,或者对表使用相同的算法但具体的参数不同。这个文件里面主要有 table Rule 和 function 这两个标签。在具体使用过程中可以按照需求添加 table Rule 和 function。
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date-day</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date-day" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2017-11-15</property>
<property name="sEndDate">2017-11-17</property>
<property name="sPartionDay">1</property>
</function>2.2.4 autopartition-long.txt
如果只有一个dataNode,那么则注释掉其他的,默认是3个dataNode
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
#500M-1000M=1
#1000M-1500M=22.3 启动
bin/startup_nowrap为启动脚本
2.4 日志查看
xx/mycat/logs/mycat.log2.5 连接Mycat
navicat连接mycat,与连接mysql一样,默认端口8806
3.水平分表实战(单库、跨库)
3.1 单库分表
3.1.1 取模拆分(适合业务表,比如用户表)
1)rule.xml配置
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes 有多少个db-->
<property name="count">1</property>
</function>2)schema.xml配置
<!--1逻辑库-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!--rule分片规则,在rule.xml-->
<!--2逻辑表-->
<table name="company" subTables="company$1-3" dataNode="dn1" rule="mod-long"/>
</schema>
<!--3数据节点-->
<dataNode name="dn1" dataHost="localhost1" database="DB" />
<!--4host配置-->
<!--balance 负载均衡策略 1多个slaver节点的负载均衡 2,3随机分发-->
<!--writeType 负载均衡类型-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostS1" url="127.0.0.1:3306" user="root" password="root" />
</dataHost>
3)测试
#插入数据
insert into company(id,name) value(1,'a');
insert into company(id,name) value(2,'a');
insert into company(id,name) value(3,'a');
insert into company(id,name) value(4,'a');
insert into company(id,name) value(5,'a');
insert into company(id,name) value(6,'a');
#分析查询
explain select * from company;3.1.2 日期拆分(适合历史流水表,比如订单表)
1)rule.xml配置
<tableRule name="sharding-by-month">
<rule>
<!-- create_time的类型为date-->
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2018-01-01</property>
</function>2)schama.xml配置
<!--1逻辑库-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!--2逻辑表-->
<!--company$1-14 代表从2018-01-01开始往后的14个月-->
<table name="company" subTables="company$1-14" dataNode="dn1" rule="sharding-by-month"/>
</schema>
<!--3数据节点-->
<dataNode name="dn1" dataHost="localhost1" database="DB" />
<!--4host配置-->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostS1" url="127.0.0.1:3306" user="root" password="root" />
</dataHost>3)测试
#插入
insert into company(name,create_time) value('a','2018-01-10');
insert into company(name,create_time) value('a','2018-02-10');
insert into company(name,create_time) value('a','2019-01-10');
#解析
explain select * from company where name='a' and create_time='2018-01-10';
3.2 跨库分表
schema.xml配置
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="company" s dataNode="dn1,dn2,dn3" rule="mod-long"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="DB1" />
<dataNode name="dn2" dataHost="localhost1" database="DB2" />
<dataNode name="dn3" dataHost="localhost1" database="DB3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostS1" url="127.0.0.1:3306" user="root" password="root" />
</dataHost>4.Mycat读写分离实战
4.1 单主
<!--没有配置table的时候指定全局dataNode="dn1"-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/>
<dataNode name="dn1" dataHost="localhost1" database="DB" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>show slaver status</heartbeat>
<!--配置读写数据库-->
<writeHost host="hostM1" url="192.168.252.121:3306" user="root" password="root">
<readHost host="hostS2" url="192.168.252.122:3306" user="root" password="root"/>
</writeHost>
</dataHost>4.2 多主
<!--没有配置table的时候指定全局dataNode="dn1"-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/>
<dataNode name="dn1" dataHost="localhost1" database="DB" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>show slaver status</heartbeat>
<writeHost host="hostM1" url="192.168.252.121:3306" user="root" password="root" />
<writeHost host="hostM1" url="192.168.252.122:3306" user="root" password="root" />
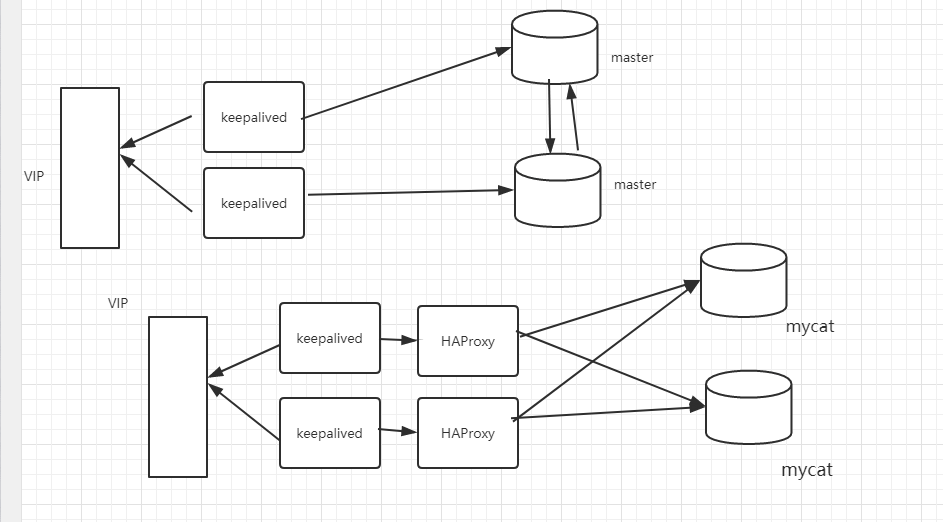
</dataHost>4.3 数据库部署架构
HA :对数据库进行负载均衡(只能对只读数据库,对写数据源负载均衡会出现数据不一致问题)
keepalived:
图一双主热备,不使用mycat的高可用方案
图二是使用mycat的高可用方案
5.Mycat 全局序列号
1)通过zookeeper
2)通过数据库
3)通过本地文件:conf/sequence_conf.properties
#default global sequence 历史id,最小,最大,当前id
GLOBAL.HISIDS=
GLOBAL.MINID=10001
GLOBAL.MAXID=20000
GLOBAL.CURID=10000
# self define sequence
COMPANY.HISIDS=
COMPANY.MINID=1001
COMPANY.MAXID=2000
COMPANY.CURID=1000
6.分片规则
可以自定义规则,参看官方文档或书籍【入门篇.第十章】
7.参考
github源码地址
Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
Mycat 读写分离 数据库分库分表 中间件 安装部署,简单使用