目录
Code:
public class Main {
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][8];
// 横向遍历
long marked = System.currentTimeMillis();
for (int i = 0; i < 1024 * 1024; i += 1) {
for (int j = 0; j < 8; j++) {
sum += arr[i][j];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
marked = System.currentTimeMillis();
// 纵向遍历
for (int i = 0; i < 8; i += 1) {
for (int j = 0; j < 1024 * 1024; j++) {
sum += arr[j][i];
}
}
System.out.println("Loop times:" + (System.currentTimeMillis() - marked) + "ms");
}
} 会发现横向遍历时间远远小于纵向遍历
物理结构:
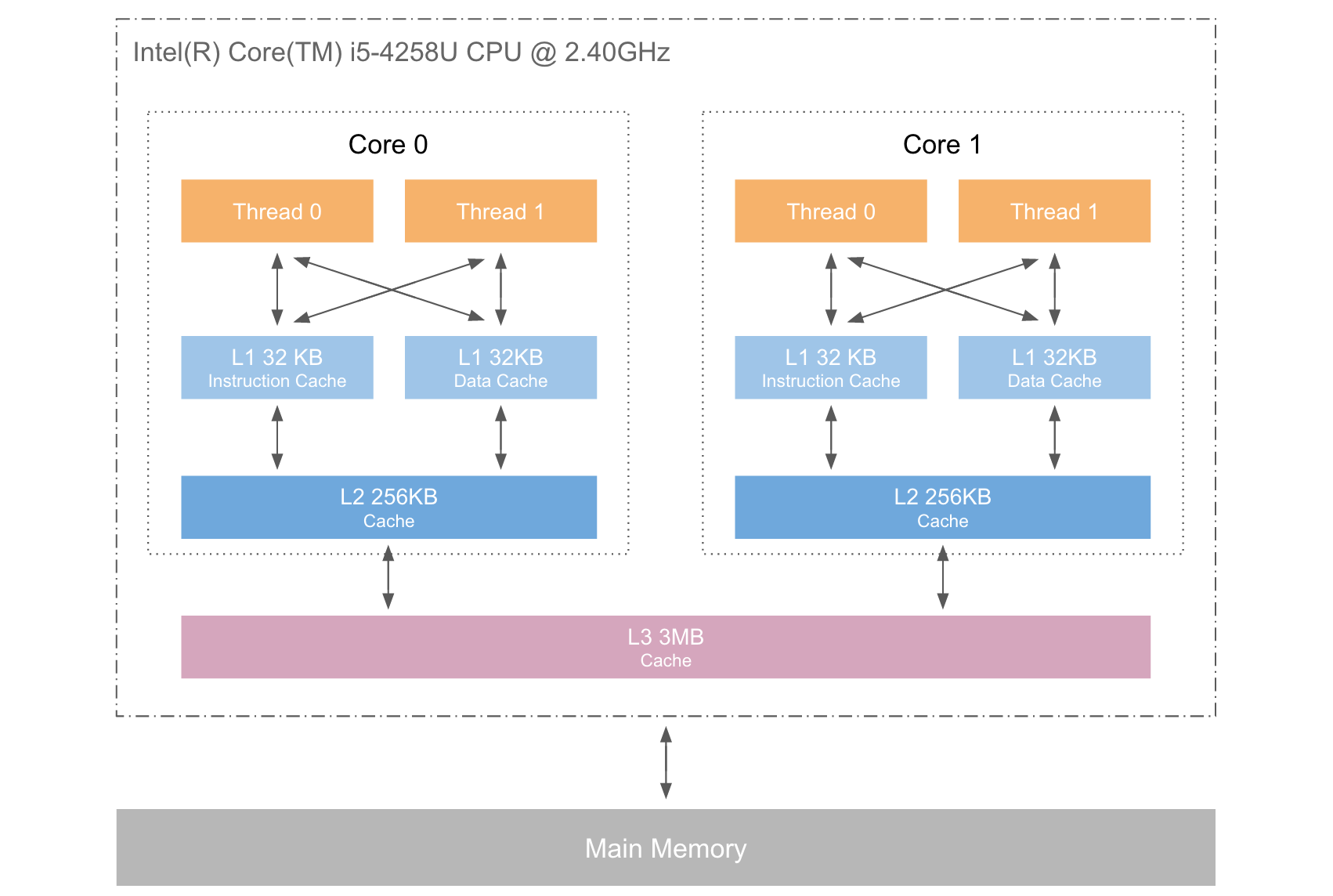
二代i5处理器:
- CacheLine size:64 Byte //缓存行
- L1 Data Cache:32KB //L1数据缓存
- L1 Instruction Cache:32KB //L1指令缓存
- L2 Cache:256KB
- L3 Cache:4MB
Martin和Mike的QCon演讲演讲中给出了一些缓存未命中的消耗数据,也就是从CPU访问不同层数数据的时间概念:
| 从CPU到 | 大约需要的CPU时钟周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80ns | |
| QPI总线传输(套接字之间,未绘制) | 约20ns的 | |
| L3缓存 | 约40-45周期 | 约15ns的 |
| L2缓存 | 约10个周期 | 约3ns的 |
| L1缓存 | 约3-4个周期 | 约1ns的 |
| 寄存器 | 1个周期 |
CPU <--- > 寄存器<--- > 缓存<--- >内存
可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
L3是每个处理器里面核心共享的,处理器之间不共享
主存是多个处理器共享的
缓存行Cache Line
缓存行(Cache Line) 便是CPU Cache 中的最小单位,CPU Cache 由若干缓存行组成,一个缓存行的大小通常是64 字节(这取决于CPU),并且它有效地引用主内存中的一块地址。一个Java 的long 类型是8 字节,因此在一个缓存行中可以存8 个long 类型的变量。
试想一下你正在遍历一个长度为16 的long 数组data[16],每一个long类型为8字节,原始数据自然存在于主内存中,访问过程描述如下
- 访问data[0],CPU core 尝试访问CPU Cache,未命中。
- 尝试访问主内存,操作系统一次访问的单位是一个Cache Line 的大小— 64 字节,这意味着:既从主内存中获取到了data[0] 的值,同时将data[0] ~ data[7 ] 加入到了CPU Cache 之中,for free~
- 访问data[1]~data[7],CPU core 尝试访问CPU Cache,命中直接返回。
- 访问data[8],CPU core 尝试访问CPU Cache,未命中。
- 尝试访问主内存。重复步骤 2
CPU 缓存在顺序访问连续内存数据时挥发出了最大的优势
伪共享:
概念:
通常提到缓存行,大多数文章都会提到伪共享问题(正如提到CAS 便会提到ABA 问题一般)。
伪共享指的是多个线程同时读写同一个缓存行的不同变量时导致的CPU 缓存失效。尽管这些变量之间没有任何关系,但由于在主内存中邻近,存在于同一个缓存行之中,它们的相互覆盖会导致频繁的缓存未命中,引发性能下降。伪共享问题难以被定位,如果系统设计者不理解CPU 缓存架构,甚至永远无法发现— 原来我的进程还可以更快。
果多个线程的变量共享了同一个CacheLine,任意一方的修改操作都会使得整个CacheLine 失效(因为CacheLine 是CPU 缓存的最小单位),也就意味着,频繁的多线程操作, CPU 缓存将会彻底失效,降级为CPU core 和主内存的直接交互
解决办法:
处理伪共享的两种方式:
- 字节填充:增大元素的间隔,使得不同线程访问的元素位于不同的缓存线上,典型的空间换时间。
- 在每个线程中创建对应元素的本地拷贝,结束后再写回全局数组,相当于线程各自操作自己的数据
字节填充:
Java8中:
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.TYPE})
public @interface Contended {
String value() default "";
} Java8 中提供了字节填充的官方实现,这使得CPU Cache 更加可控了,无需担心jdk 的无效字段优化,无需担心Cache Line 在不同CPU 下的大小究竟是不是64 字节。使用@Contended 注解可以完美的避免伪共享问题。
但是这个功能暂时还是实验性功能,暂时还没到默认普及给用户代码用的程度。要在用户代码(非引导类加载器或扩展类加载器所加载的类)中使用@Contended注解的话,需要使用- XX:-RestrictContended参数。
比如在JDK 8的ConcurrentHashMap源码中,使用[@sun.misc.Contended]对静态内部类CounterCell进行了修饰。
/* ---------------- Counter support -------------- */
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended
static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}Thread中:
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;内存屏障:
内存屏障提供了3个功能:确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;
强制将对缓存的修改操作立即写入主存;
如果是写操作,它会导致其他CPU中对应的缓存行无效。
屏障的策略:
在每个volatile写操作前面插入storestore屏障;
在每个volatile写操作后面插入storeload屏障;
在每个volatile读操作后面插入loadload屏障;
在每个volatile读操作后面插入loadstore屏障;
其中loadload和loadstore对应的是方法acquire,storestore对应的是方法release,storeload对应的是方法fence。
理解:
工作内存可以看成是CPU高速缓存、寄存器的抽象
主内存可以看成就是物理硬件中主内存的抽象