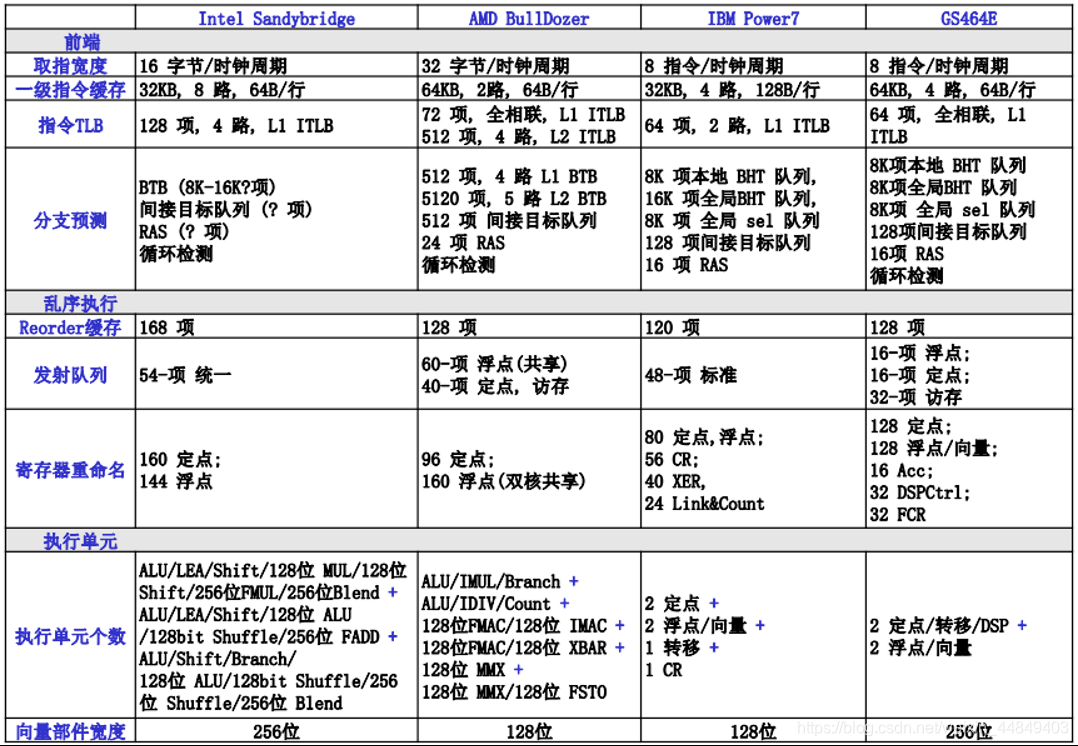
存储层次的基本概念
CPU与RAM的速度剪刀差
(1)摩尔定律:
• CPU的频率和RAM的容量每18个月翻一番
• 但RAM的速度增加缓慢
(2)通过存储层次来弥补差距:
• 寄存器、Cache、存储器、IO
处理器和内存速度剪刀差
- 早期Alpha处理器Cache失效延迟:
• 1st Alpha (7000): 340 ns/5.0 ns = 68 clks x 2 or 136
• 2nd Alpha (8400): 266 ns/3.3 ns = 80 clks x 4 or 320
• 3rd Alpha (t.b.d.): 180 ns/1.7 ns =108 clks x 6 or 648 - 当前主流处理器主频2GHz以上:
• IBM Power 6主频6GHz以上
• 内存延迟50ns左右
• 访存延迟>100拍 - 多发射加剧了访存瓶颈
摩尔定律使CPU的内容发生了变化
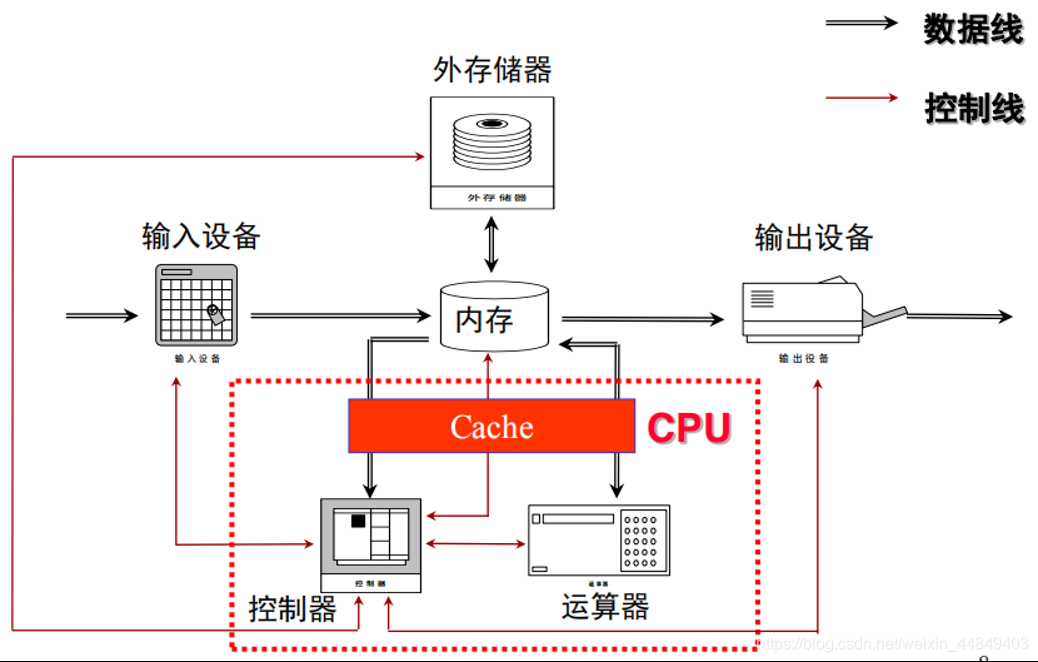
(1)冯诺依曼结构的核心思想:
• 存储程序:指令和数据都存放在存储器中
(2)计算机的五个组成部分:
• 运算器、控制器、存储器、输入、输出
• 运算器和控制器合称中央处理器(CPU)
(3)为了缓解存储瓶颈,把部分存储器做在片内:
• 现在的CPU芯片:控制器+运算器+部分存储器
• 片内Cache占了整个芯片的很大一部分面积
计算机硬件系统的组成
CPU中RAM的面积和晶体管比例
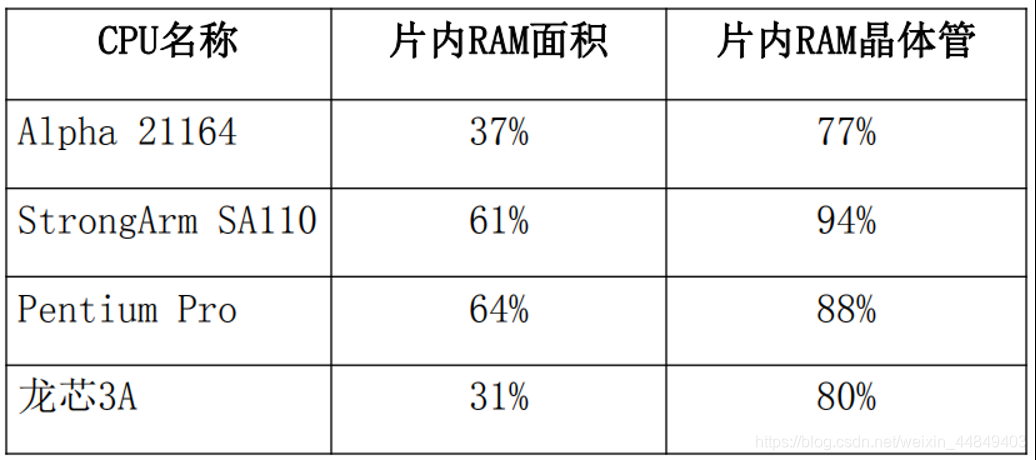
RAM所占的面积比例小于晶体管:因为RAM很规则,可以做到很密,而普通逻辑不行;
存储层次基本原理
- 程序访问的局部性:时间局部性和空间局部性
• 新型的应用(如媒体)对传统的局部性提出了挑战
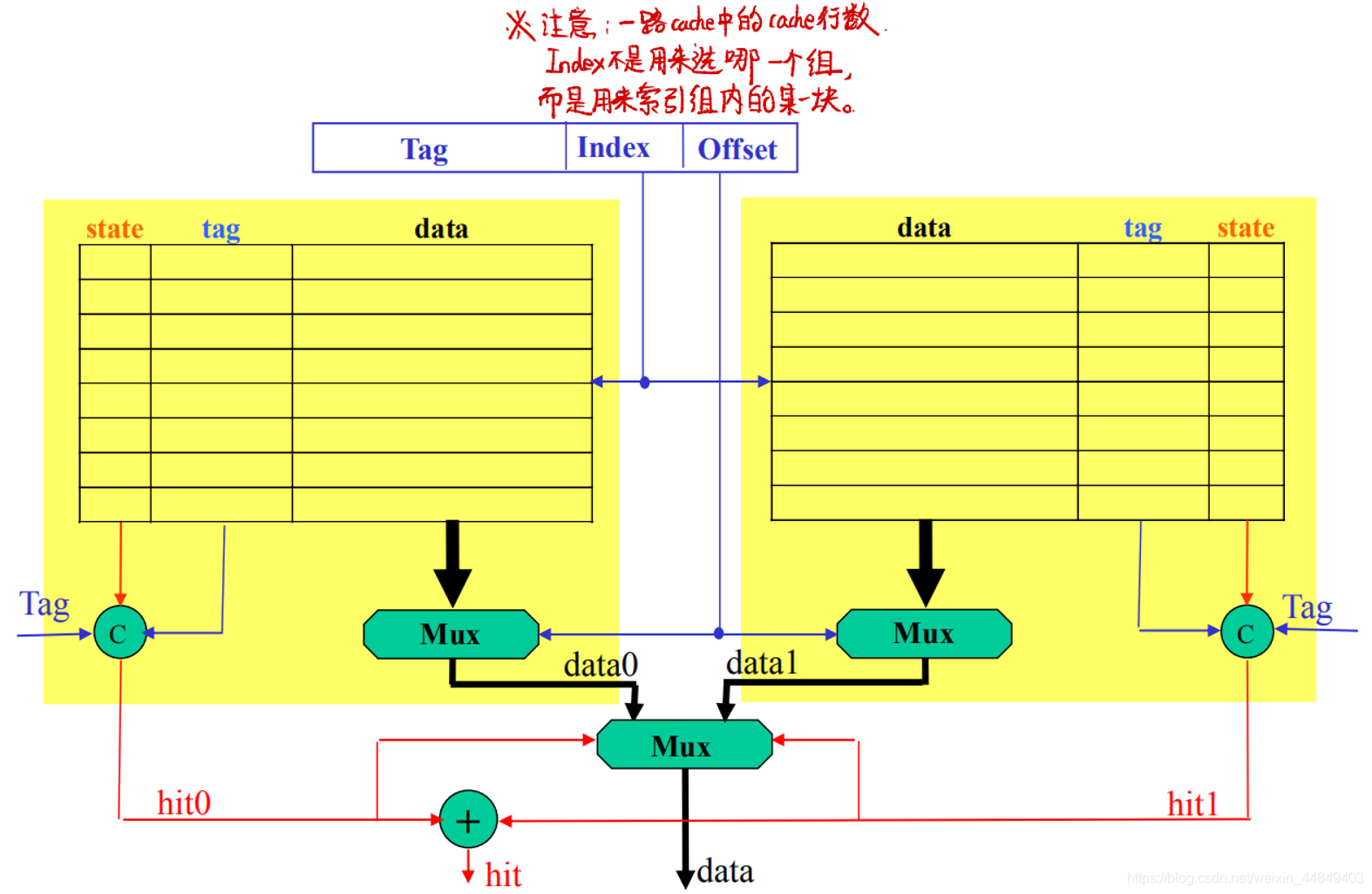
Cache结构
cache的结构
(1)cache特征:
- Cache的内容是主存储器内容的一个子集
- Cache没有程序上的意义,只是为了降低访存延迟
- 处理器访问Cache和访问存储器使用相同的地址
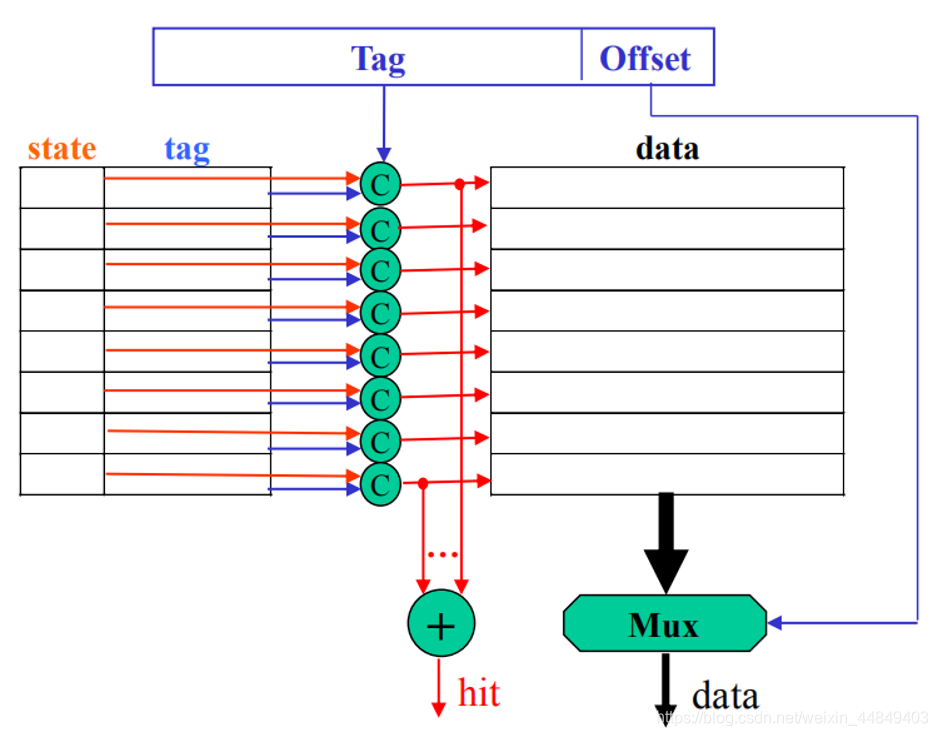
(2)cache结构特点:
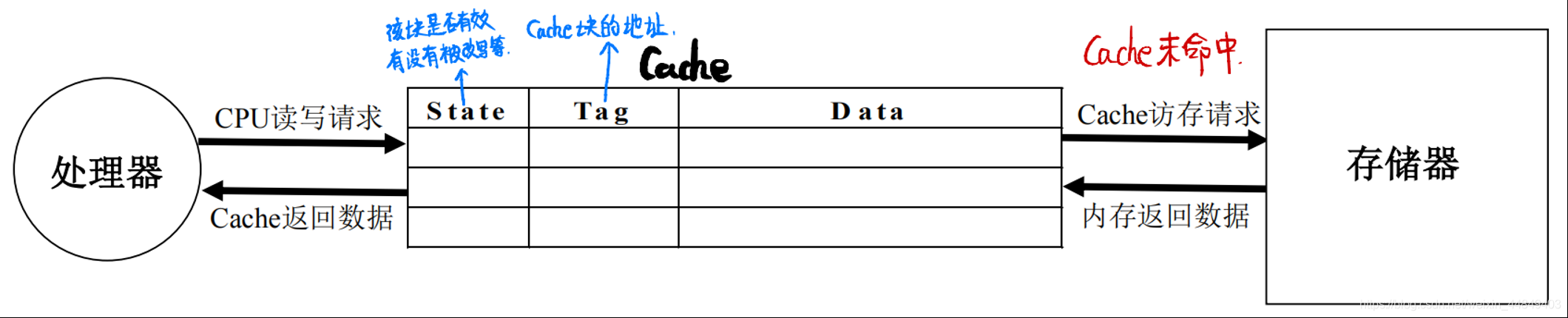
- 同时存储数据和地址以及在cache中的转态;
- 通过地址的比较判断相应数据是否在Cache中 ;
- 需要考虑所需要的数据不在Cache中的情况:替换机制,写策略等;
(3)cache分类:
1)cache块的位置:同一单元在不同结构Cache中的位置
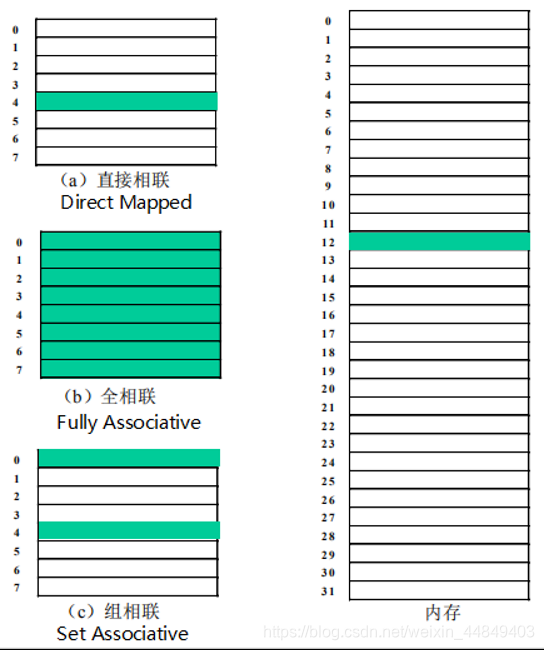
- 全相联:
命中率高;硬件复杂、延迟大;
- 直接相联:
命中率低;硬件简单、延迟最小;
- 组相联:
介于全相联和直接相联之间;
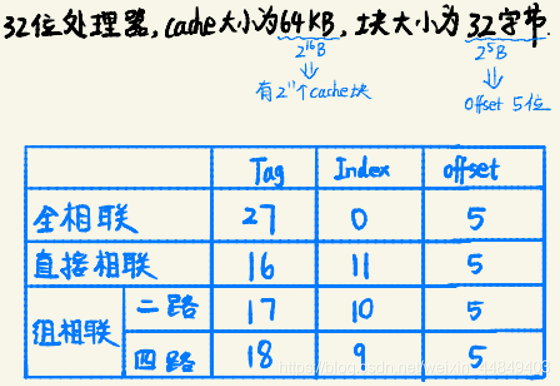
- 例题:
2)Cache替换算法:
- 常见的替换算法:随机替换、LRU最近最少使用、FIFO先进先出
- 对直接相联Cache不存在替换算法问题;
- 每1000条指令失效次数统计:
- SPEC CPU2000中的gap, gcc, gzip, mcf, perl, applu, art, equake, lucas, swim 10个程序
- Aplha结构,块大小64B
3)写命中时采取的策略:
- 写穿透(Write Through):
• 写Cache的同时写内存
• 内存里的数据永远是最新的,Cache替换时直接扔掉
• Cache块管理简单,只需有效位 - 写回(Write-back):
• 只写Cache不写内存
• 替换时要把Cache块写回内存
• Cache块状态复杂一些,需要有效位和脏位 - 写回/写穿透的使用:(CPU<—>L1(常在CPU内)<—>L2<—>内存)
• L1到L2用写穿透的多,L2较快
• L2到内存用写回的多,内存太慢了
• 龙芯2号两级都采用写回策略
4)写失效时采取的策略:
- 写分配( Write Allocate ):
• 先把失效块读到Cache,再在Cache中写
• 一般用在写命中时采用写回策略的Cache中 - 写不分配(Write Non-allocate):
• 写Cache失效时直接写进内存
• 一般用在写命中时采用写穿透的Cache中
Cache性能优化
Cache性能分析

- CPU执行时间与访存延迟的关系
- 平均访存时间AMAT = Average Memory Access Time
- CPIALUOps 不包括访存指令
Cache性能优化
- 降低失效率(MissRate)
- 降低失效延迟(MissPenalty)
- 降低命中延迟(HitTime)
- 提高Cache访问并行性
降低失效率
(1)引起Cache失效的因素(3C/4C):
- 冷失效(Cold Miss或Compulsory Miss) :
• CPU第一次访问Cache块时Cache中还没有该Cache块引起的失效;
• 冷失效是不可避免的,即使Cache容量再大也会有; - 容量失效(Capacity Miss) :
• 程序执行过程中,有限的Cache容量导致Cache放不下时替换出部分Cache块,被替换的Cache块再被访问时引起失效;
• 一定容量下全相联Cache中的失效; - 冲突失效(Conflict Miss) :
• 直接相联或组相联Cache中,不同Cache块由于index相同引起冲突;
• 在全相联Cache不存在; - 一致性失效(Coherence Miss):
• 由于维护Cache一致性引起的失效;
(2)3C失效率分析(SPEC92):
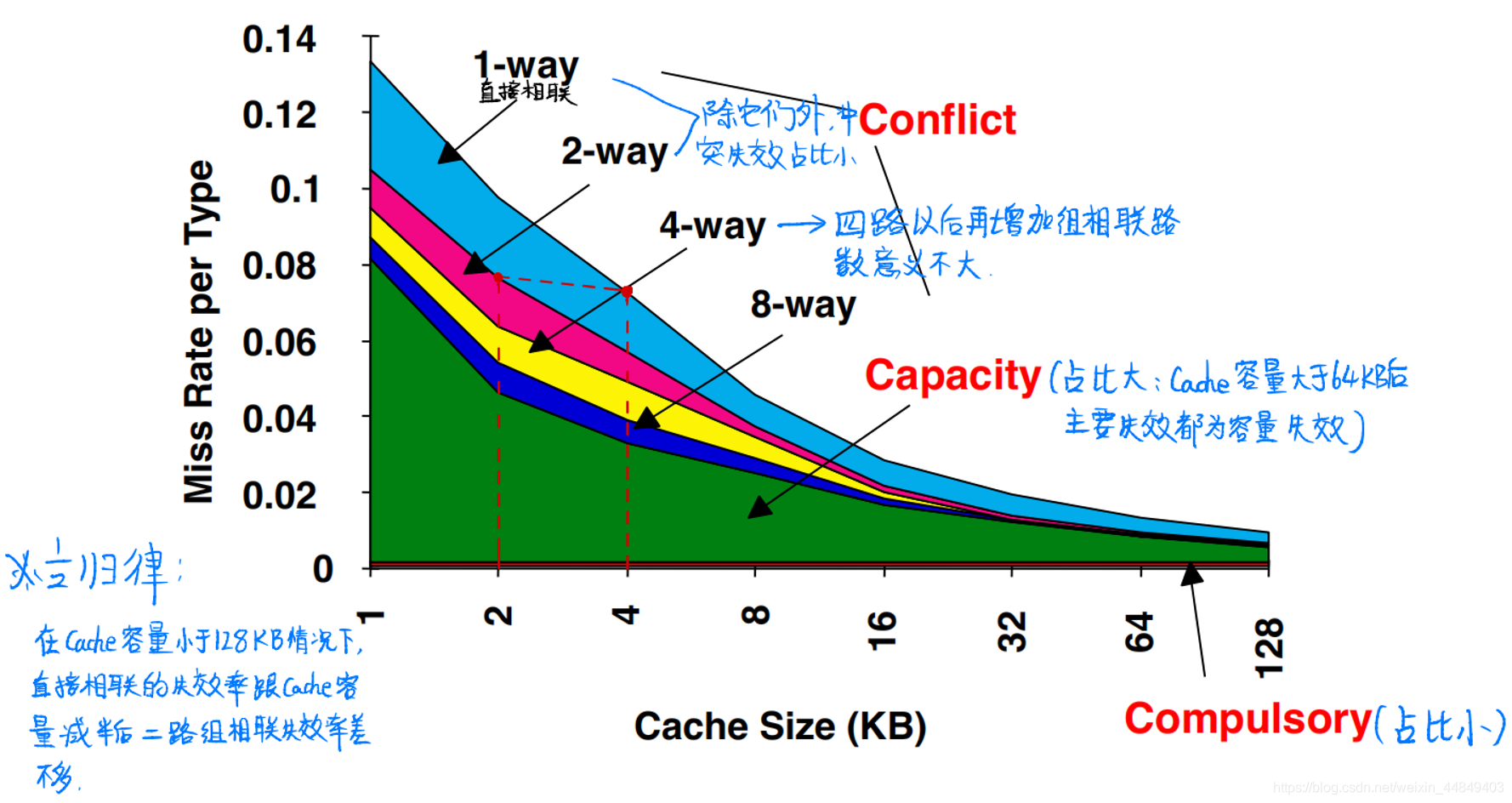
(3)解决方法:
1)增加块大小降低失效率:
- 利用空间局部性:降低冷失效,增加冲突失效以及容量失效
- SPEC92,DECstation 5000,小容量Cache块较小
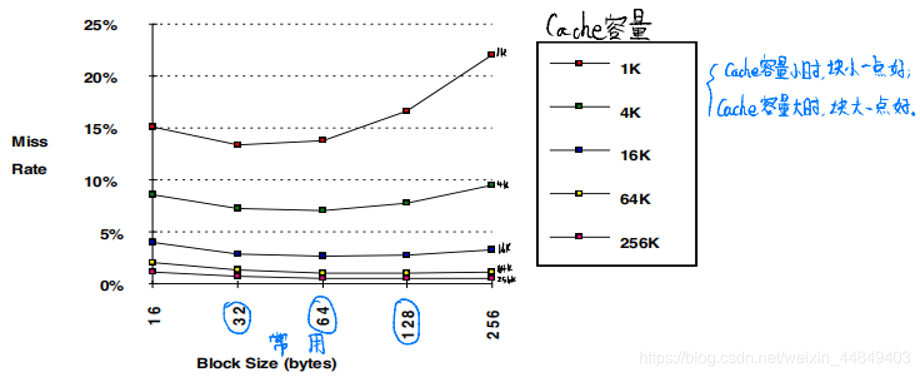
2)增加Cache容量提高命中率: - 一级Cache访问直接决定时钟周期
• 尤其是在深亚微米的情况下,连线延迟很大
• PIII一级Cache为16KB,PIV一级Cache为8KB。 - 增加片内Cache大小增加芯片面积
• 有的处理器片内Cache面积占整个芯片面积的80%以上
• 现代处理器二级或三级Cache大小已经达到几MB甚至几十MB。 - 现代通用处理器的一级Cache大小
• HP PA8700:一级Cache为1MB+1.5MB,没有二级Cache
• 其他RISC处理器( Alpha, Power, MIPS, Ultra SPARC)32/64KB+32/64KB
• PIV 12Kop Trace cache+8KB数据Cache(PIII: 16KB+16KB)
• 反映出设计人员的不同取舍
3)增加相联数目降低失效率:
- 增加相联度:
• 2:1规则:大小为N的直接相联的Cache命中率与大小为N/2的二路组相联的 Cache命中率相当
• 八路组相联的效果已经与全相联的失效率相差很小(4 路以后再增加就不明显了) - 增加相联度会增加时钟周期延迟以及硬件复杂性:
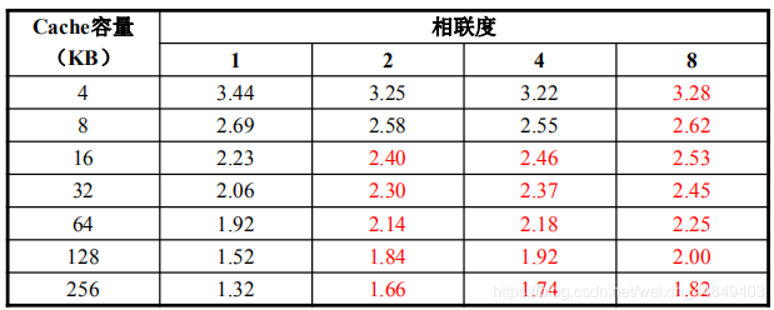
• 例如,直接相连时钟周期为1ns,2路组相联为1.36ns,4路组相联为1.44ns,8路组相联为1.52ns,失效延迟为25时钟周期
• Cache访问可能是整个处理器的关键路径
4)“路预测(Way Prediction)”和“伪相联”提高命中率:
结合直接相联访问时间短和组相联命中率高的优点
- 做法:在多路相联的结构中,每次Cache访问只检查一路,如果不命中再检查其他路:
- 两种命中:hit和pseudohit
- 直接判断第0路,或进行Way-Prediction:
- Alpha 21264 ICache路猜测命中率85%,hit时间为1拍,pseudohit时间3拍 ;
//1位进行路预测,预测命中1拍,不命中再一起访问其余三路需要3拍。再不命中,发生cache失效;
- Alpha 21264 ICache路猜测命中率85%,hit时间为1拍,pseudohit时间3拍 ;
- 不用并行访问每一路,可以大幅度降低功耗
- 在片外或L2以下cache中用得较多,如 MIPS R10000、UltraSPARC的L2
//伪相联:⼆级cache在⽚外时可通过路预测,每次访问一路减少芯⽚引脚。

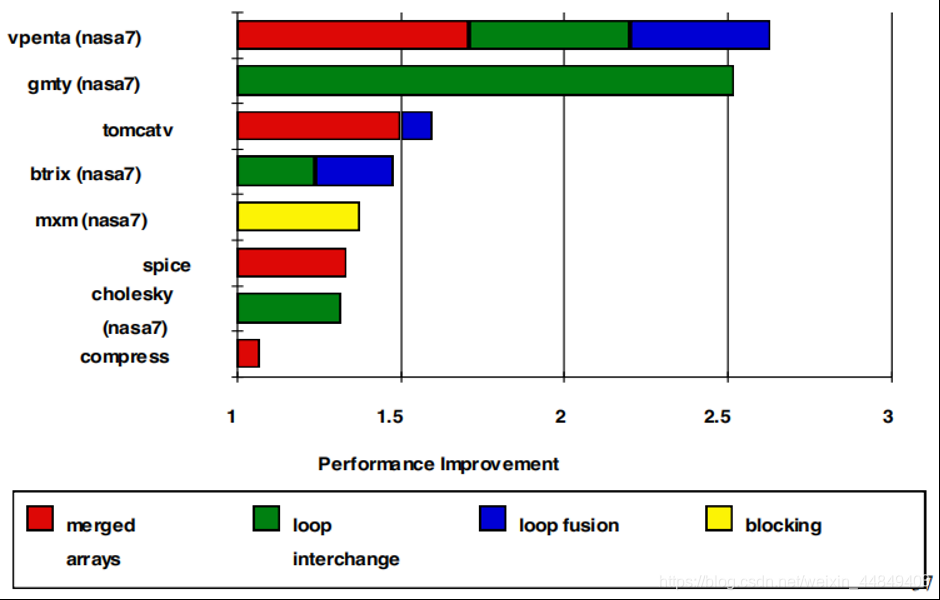
5)软件优化降低失效率:
McFarling [1989]在8KB直接相联的Cache上通过软件优化降低失效率75% ;
- 常见软件优化技术:
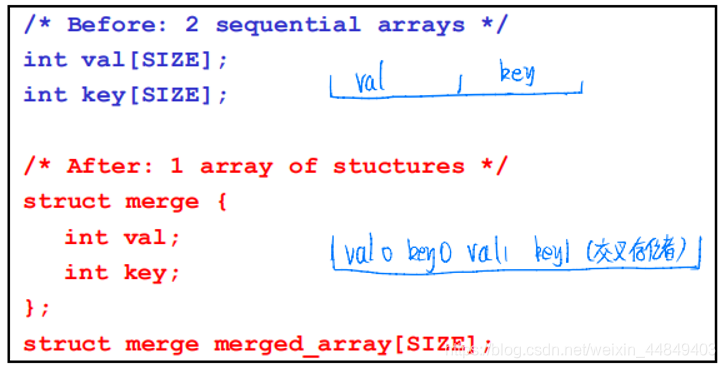
-
数组合并(Merging Arrays):
通过数组合并降低数组 val 和 key 的冲突,增加空间局部性;
-
循环交换(Loop Interchange) :
通过循环交换提高空间局部性,把非连续访问变换成连续访问;

-
循环合并(Loop Fusion) :
通过循环合并提高空间局部性,数组 a&c 的失效次数从2次降低到1次;

-
数组分块(Array Blocking):
- 分块前,y和z失效N3次,x失效N2次,总失效次数从2N^3 + N^2;
- 分块后,由于可以在cache中放下BxB的小矩阵,y和z失效1次可以用B次,因此失效次数从2N^3 + N^2 降为 2N^3/B +N^2;

-
- 软件优化的效果:
降低MissPenalty
(1)通过关键字优先降低失效延迟:
在Cache访问失效时,优先访问读访问需要的字:
- 例如,Cache块大小为64字节,分为8个8字节的双字,如果取数指令访问其中的第6个双字引起Cache失效,就按6、7、0、1、2、3、4、5的次序,而不是按0、1、2、3、4、5、6、7的次序访问内存;
- 关键字优先的实现只需要对访问地址进行简单变换;
- 在失效的数据从内存取回之后,往Cache送的同时直接送回到寄存器也可以降低失效延迟;
(2)通过读优先降低失效延迟:
-
读Cache失效对指令流水线效率的影响比写失效大:
- 在处理器中一般都有写缓存(Write Buffer),写指令只要把要写的数据写到写缓存就可以提交,再由写缓存写到Cache或内存;
- 取数在数据读回来回前取数指令不能提交,与取数指令存在数据相关的后续指令要等待取数操作读回来的数据才能执行,可见读Cache失效容易堵塞指令流水线;
-
在进行Cache失效处理时,优先处理读失效以减小堵塞:
- 读失效时要注意与Write Buffer的RAW相关,不能等写缓存为空,要动态检查写缓存;
- 读失效可能需要替换dirty块,不要把替换块写回到内存再读,可以把替换块写到写缓存,然后先读,后把写缓存的内容写回内存;
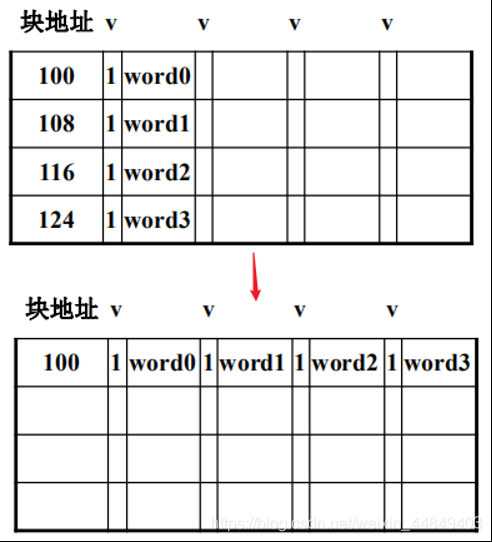
(3)通过写合并降低失效延迟:
1)写缓存(Write Buffer)的作用:
• 处理器写到WB就算完成写操作,由WB写到下一级存储器
• 注意一致性问题:处理器后续的读操作、外设的DMA操作等
2)通过把写缓存中对同一Cache块的写操作进行合并来提高写缓存使用率,减少处理器等待
• 注意IO操作不能合并
• Store Fill Buffer:连续的写操作拼满一个Cache块,写失效时不用到下一级存储器取数
(4)通过Victim Cache降低失效延迟:
- 在直接相联的Cache中避免冲突失效;
- 增加缓存(Victim Cache)保存从Cache中替换出来的数据;
- Jouppi [1990]:4项victim cache可消除直接相联4KB Cache中20%-95%的冲突访问
- 在Alpha, HP等处理器中应用
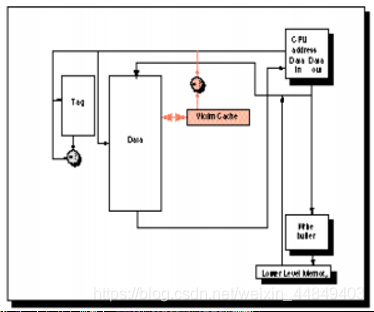
(5)通过二/多级Cache降低失效延迟:
1)通过L2降低失效延迟:
- AMAT = Hit TimeL1 + Miss RateL1 x Miss PenaltyL1
- Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 x Miss PenaltyL2
AMAT = Hit TimeL1 + Miss RateL1 x (Hit TimeL2 + Miss RateL2 x Miss PenaltyL2)
2)L2的失效率:
- 局部失效率(Local miss rate)— L2失效次数除以L2访问次数
- Miss RateL2
- 全局失效率(Global miss rate) — L2失效次数除以所有访存次数
- 局部失效率较高(10%-20%),全局失效率很低(<1%);
- 一般,一级cache的内容是二级cache内容的真子集:
①. 若一级cache冲突,二级cache冲突概率也大,则二级cache组相联度常比一级cache高;
②. 变换二级cache的索引(把二级cache索引和高位地址异或,降低二级cache冲突概率);
③. 二级cache容量大,且二级cache访问拍数不关键,因此访问二级cache的流水线级可能更长;
降低HitTime

(1)简化Cache设计:
1)访问Cache常常是整个CPU的时钟关键路径:
• Cache越小,延迟越小
• 直接相联的Cache延迟小
2)简化一级Cache设计需要统筹考虑:
• PIV数据Cache从PIII的16KB降低为8KB,而且只有定点可以访问,从而达到高主频
• 但PIV的二级Cache只有6拍的访问延迟
(2)并行访问Cache与TLB:
1)避免地址转换延迟:虚地址Cache(最有效)
- 通过虚地址直接访问Cache减少虚实地址转换时间;
- 模型:
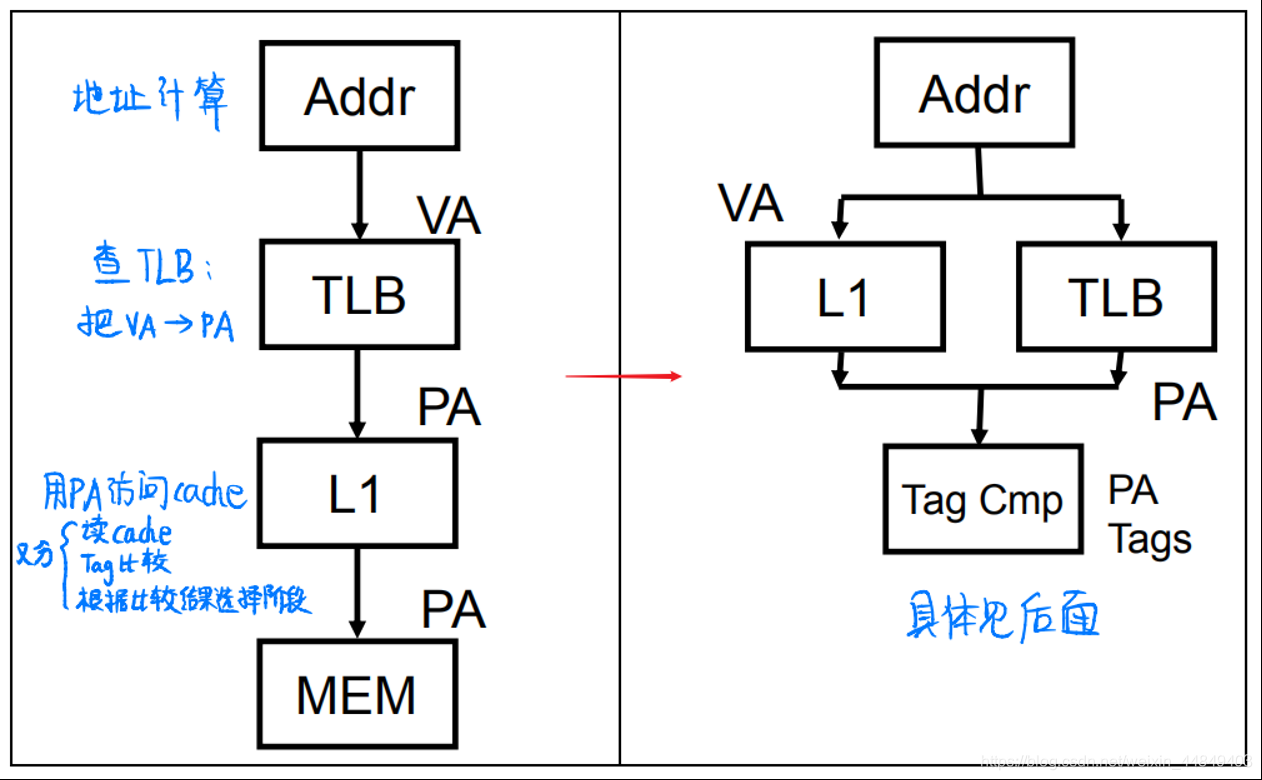
- 问题:
- 区分进程问题:不同进程的虚地址空间是一样的,需要在进程切换时候刷Cache以维护一致性,增加了冷失效
- 别名(aliases)问题:操作系统有时候(如为了进程间共享)需要不同的虚地址对应同一物理地址
2)虚地址Cache中多进程对Cache命中率的影响:
进程切换问题可以通过在TLB中增加进程号的方式来解决:
- 单进程、多进程切换时刷Cache、多进程用ID号来区分虚地址;
- Y轴表示Cache失效率;X轴表示Cache大小(2 KB - 1024 KB);
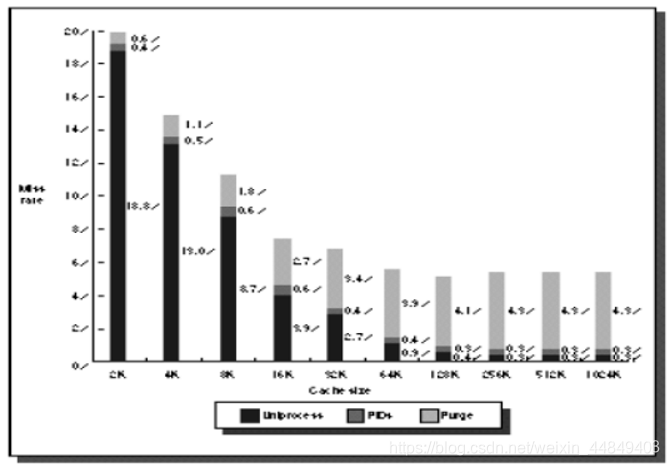
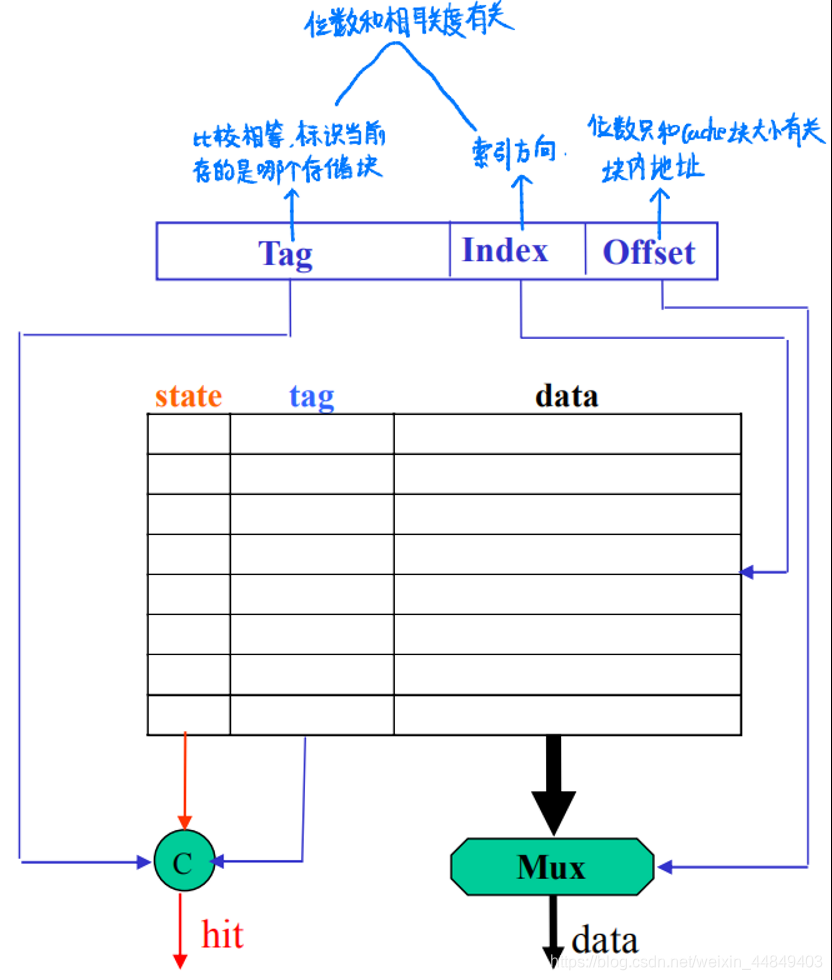
3)虚Index实Tag技术:
在用Index从cache中读Tag的同时,进行虚实地址转换,可以使用物理地址做tag;
- 问题:如何保证虚实地址Index位的一致?
- 增加页大小、增加相联度;(提高Page Offset位数 | 减少Index位数)
- 软件保证:页着色(Page coloring);(现在软件支持不好)
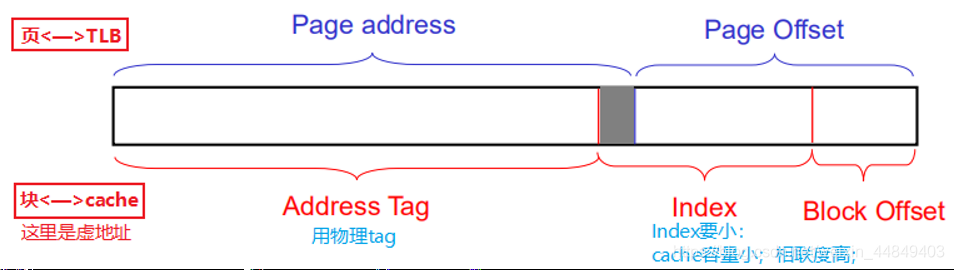
①若:Page Offset > Index+Block Offset,则虚地址cache=物理地址cache;
②若:Page Offset < Index+Block Offset,则虚地址cache中有可能存在同一块数据由于虚地址cache索引的不同,在cache中有多个备份的情况(cache别名问题) - 具体详情:

(3)增加Cache访问流水级:
- Cache访问时间是处理器主频的决定因素之一,其他因素包括加法及bypass时间等;
- 把cache访问分成多拍以提高主频:
• MIPS:1拍
• Alpha:2拍
• 增加流水节拍增加了load-use延迟
提高Cache访问并行性
(1)多访存部件:
- 现代高性能处理器大都采用两个或更多访存部件:
• 如Intel的IvyBridge有两个读部件、一个写部件
• AMD的Bulldozer有两个读/写部件 - 多个访存部件提高了访存的吞吐率:
• 降低了平均Hittime
(2)非阻塞Cache:
1)机制:
- 非阻塞(Non-blocking/Lockup-free)Cache在访问失效时允许后续的访问继续进行:
• hit under miss、hit under multiple miss、miss under miss
• 前面的失效访问不影响后续访问,需要支持多个outstanding访问,需要类似于保留栈的访存队列机制
• 在乱序执行的CPU中使用,显著增加Cache控制器复杂度 - 多个层次的非阻塞访问:
• L1、L2、内存控制器
• 龙芯2号支持24个L1非阻塞访问,8个L2非阻塞访问
2)SPEC程序的非阻塞访存效果:
8 KB直接相联数据Cache,块大小32字节,失效延迟16拍 :
• 浮点程序AMAT= 0.68 -> 0.52 -> 0.34 -> 0.26
• 定点程序AMAT= 0.24 -> 0.20 -> 0.19 -> 0.19
(3)硬件预取:
1)指令预取:
• Alpha 21064 在Cache失效时取连续两块,多取的Cache块存放在流缓存(stream buffer)中,下一次Cache失效时先检查指令是否在流缓存中
2)数据预取:
• Jouppi [1990]:对4KB的Cache,1项流缓存可以命中25%的Cache失效访问, 4项流缓存可以命中43%的Cache失效访问
• Palacharla & Kessler [1994]:指令和数据Cache各为四路组相联的64KB,对科学计算程序,8项流缓存可以命中 50%-70%的Cache失效访问
3)现代处理器都实现复杂预取技术:
• 预取对访存带宽提出了更高的要求
(4)软件预取:
1)软件预取都是数据预取:
• 预取到寄存器: (HP PA-RISC loads)
• 预取到Cache: (MIPS IV, PowerPC, SPARC v. 9)
• 预取指令不发生例外,预取到Cache的指令可以不等待数据返回
2)预取指令开销:占用指令槽:
• 多发射结构对预取指令占用指令槽不怎么敏感
3)龙芯2号对软件预取的支持:
• 目标寄存器为0号寄存器的取数指令不发生例外,不阻塞流水线
Cache优化小结

常见处理器的存储层次
MIPS R10000存储层次

HP PA-8x00存储层次

UltraSparc III存储层次

Alpha 21264存储层次
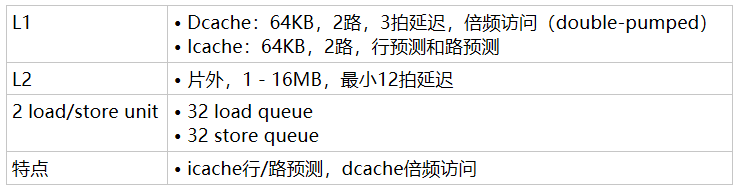
Power4存储层次

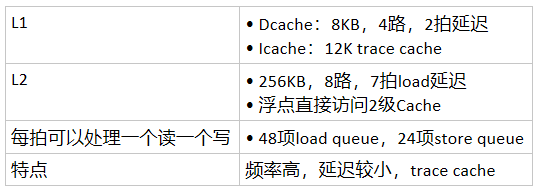
Pentium4存储层次
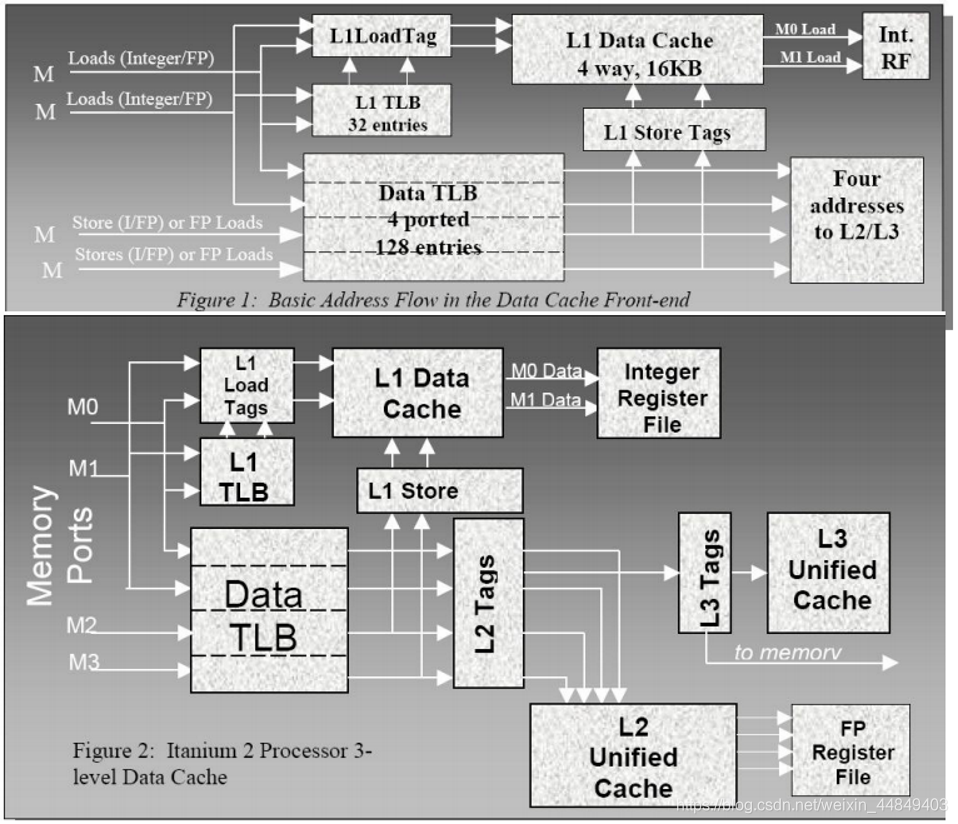
Itanium2存储层次

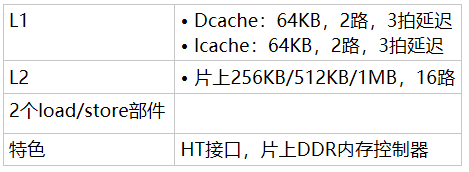
Athlon64存储层次
常见处理器的数据通路(最近)