存储器类别
现代存储器一共包括以下几种:
| 寄存器 | 直接和cpu进行交互数据的存储器 (速度最快)与cpu1级高速缓存交互 |
| cpu 1级高速缓存 | 直接嵌在cpu内部,每个cpu独有的 |
| cpu 2级高速缓存 | 在cpu外部,也是每个cpu独有 |
| cpu 3高速缓存 | 所有cpu共享的缓存 |
| 内存 | 与高速缓存交互、通过cpu控制dma与内存做交互 |
| 硬盘 | 通过cpu控制dma与内存做交互 |
上图的存储器速度,从上到下依次递减。
我们通过命令 sysctl -a 查看一二三级缓存的大小
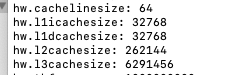
一级缓存的大小为 32k,二级256k 3级 6m
高速缓存
高速缓存的内部结构:
由于cpu的速度太快了,内存完全跟不上cpu的运算速度,所以我们引入了一个cpu高级缓存的存储器。20ghz的cpu一秒能有20亿个时钟周期,也就是运行20亿个指令。光靠内存传输,速度完全跟不上

由上图,我们可以看出访问1级缓存的速度和访问内存速度差了100倍。
那为什么不用高速缓存替换内存呢?
- 首先缓存之所以快。其中一个原因是因为它离cpu近,物理方面的限制
- 缓存的成本比内存成本贵太多了。
综合上面两个原因,我们只能限制缓存的大小。
局部性原理
为了让高速缓存能更有效的利用,引入了时间局部性原理和空间局部性原理。
时间局部性原理
即使用了lru算法,保证热点数据一直在高速缓存中,我们就不用频繁去访问内存
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰
空间局部性原理
假设我们访问了加载了当前的数据,一定会加载下一条数据。有了空间局部性就会把下一条数据加载到高速缓存中。
我们来看一段代码,分析其性能:
public static void main(String[] args) {
int[] arr = new int[64 * 1024 * 1024];//64kb
long start = System.currentTimeMillis();
// 循环 1
for (int i = 0; i < arr.length; i++) arr[i] *= 3;
long end = System.currentTimeMillis();
System.out.println("Time spent is " + (end - start) + "ms");
start = System.currentTimeMillis();
// 循环 2
for (int i = 0; i < arr.length; i += 16) arr[i] *= 3;
end = System.currentTimeMillis();
System.out.println("Time spent is " + (end - start) + "ms");
}输出结果为
Time spent is 31ms
Time spent is 26ms
我们首先来分析 循环1,执行了64 * 1024 * 1024次arr[i] *= 3
第二个循环,每次+16,意味着执行了4*1024*1024次arr[i] *= 3
两者执行arr[i] *= 3的次数相差了16倍,但是执行时间却只差了5ms,有问题!
我们来看下面这个图

为了合理分配我们的高速缓存,我们把缓存分为块,其中每个块cache line 64个字节(一个字节等于8位)。
那么我们的高速缓存这么对应到内存呢?缓存量级和内存的量级都不是一个档次的。
我们使用了如上图的方法,我们的缓存块一共有8块,取内存中的地址后3位作为缓存块的地址,与之类似的方法,5%8=0,21%8=5,那么此时的缓存都命中在5这个缓存块中。
所以如果我们查询的内存数据在缓存块中,那么就不用再去查找内存了。
但是内存中的block21和block5,都是会把数据放在cache line5中,这个这么解决呢?
我们在每个cache line中放置一个标志位,标志当前是属于哪个组的,block5还是block21的。实际上我们取内存地址的高二位来判断该cache line属于哪个内存块
所以我们整理一下从高速缓存中取数据的步骤
- 根据内存地址,取后三位 定位到cache line。
- cache line中还有信息是标识当前信息是否是有效的,如果一开始并没有从内存读数据的情况
- 判断cache line 是否为要查找的组,也就是取内存高二位和cache line中的组信息进行对比。
- 根据内存地址的offset位,从data block 数据中读取数据

上图就是内存和高速缓存的映射关系,cpu直接从cache line中拿实际数据就行了。
接下来就可以解释 为什么上面的代码-循环1中运行了31ms,循环2中运行了26ms。
假设只用到了一级缓存: 1kb能存储16个cache line(1024/64) ,一级缓存有 16*32=512个cache line
因为每个int类型占用4个字节,所以当它运行16次的时候,已经运行了64个字节,也就是一个cache line,每64个字节从内存中拿一次block到cache line ,所以速度是差不多的。