什么是CPU高速缓存
前言
在提到顺序表和链表的区别时,通常会提到一句:顺序表的CPU缓存率高于链表。为什么会有这句话的出现呢?而CPU缓存利用率是什么呢?
引入
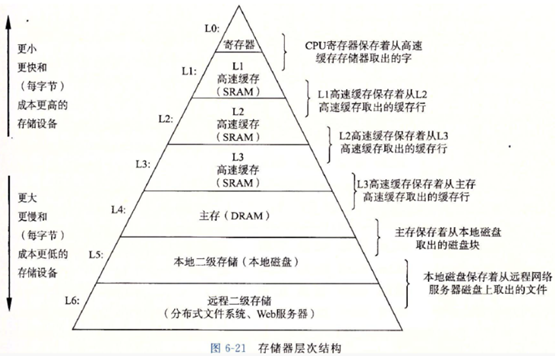
首先我们需要了解一下计算机的存储体系
如图所示:越往上读取速度会越快,同时大小也越来越小;
CPU如何遍历数据?
假设,我们现在需要去遍历顺序表和链表
在程序编译过程中,编译我们所写的遍历代码后会进行汇编,汇编就是将我们缩写的代码转化为二进制的机器码。而CPU去执行我们的读取遍历指令时,并不是从我们的内存中直接读取的,而是从3个高速缓存中读取的,为什么呢?说白了就是速度快。
读取过程是怎么样的呢?可以分为以下3步:
-
首先,遍历时总会存第一个顺序表或者元素的地址内开始去操作;
-
CPU会首先去访问存储数据1的内存地址;
-
查看这个地址在不在高速缓存当中
- 在:直接访问;
- 不在:把这个内容的地址加载到高速缓存当中后再访问;
CPU加载缓存机制
你可能会问:当读取第一个元素中时,链表的不在,顺序表也不在,那为什么会出现利用率的区别呢?来,我们再了解一下它加载到缓存中的机制;
在计算机体系中提到:当CPU将要把内容放到高速缓存当中时,由于考虑到用户在实际使用当中很可能马上会访问它的相邻位置,也就是所谓的就近原则。
CPU将内容放进高速缓存当中时,是不会单独把数据1的位置放进缓存中的,而是会将其身后一段连续的空间一起加载缓存中。具体加载大小取决于操作系统的硬件体系。
小结
现在我们来想想顺序表有什么特点?内存空间是成片连续的。
链表的结构有什么特点?可能会有连片的区域,但多数是散落在内存空间的各个区域。
那么在加载顺序表的元素到缓存当中时,CPU很大可能会把我们后续的空间也一起放进去,这样在CPU读取过程当中会非常大的提高访问速度。
加载链表时,链表的存储方式很大可能不是连片的区域而是散落在堆区的各个角落,因为CPU会加载身后连续一片区域,假设我们链表元素有5个元素,一个结点占4个字节,而CPU一次就加载20个字节,又出于不是连续空间的原因,在遍历访问链表的5个元素时很有可能放在高速缓存内100个字节,这不仅会造成缓存空间的浪费,还很有可能会造成内存空间污染(因为缓存大小有限,如果满了就会排出其余元素),如果链表每次都这样玩,中午玩还没啥问题,但早晚会出事(bu)!!
至此,就有了顺序表和链表的缓存利用率的区别;
结语
创作不易,如果你觉得这篇文章对你有用的话,别忘了点赞在看+关注噢!
后续,我们会将最新文章第一时间发送在微信公众号:“01编程小屋”当中,别忘了关注我们的公众号以免错过了噢!