转载地址:https://zhuanlan.zhihu.com/p/21362413
什么意思呢?就是用梯度下降的方法学会了梯度下降的学习方法。

用一个神经网络来调控另一个神经网络!
怎么做?如上图,一个是神经网络优化器,一个是被优化的神经网络,也就是我们平时都用的神经网络。这里我们把数据输入到被优化的神经网络中,然后输出误差,把误差信号传给神经网络优化器,这个优化器就自己计算输出参数应该更新的大小,然后更新这个被优化的神经网络。
然后他们的工作简单的说就是训练了一个神经网络来学习如何优化神经网络,然后他们做到了!并且,效果惊人!
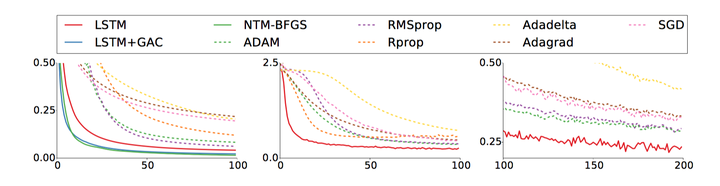
看上面的几张对比图,实线是具备学习能力也就是优化方法的神经网络的学习曲线,而虚线是其他各种优化方法(SGD,RMSprop,ADAM。。。)你即使不知道这些方法也没有关系,从上面的表可以看到神经网络的学习速度比其他方法都好,而且好得多!
以前,虽然我们不知道AlphaGo是怎么想的,但是我们知道它是怎么学的,
以后,我们不但不知道AlphaGo是怎么想的,我们还不知道它是怎么学的!!!
基于这个成果,整个学习训练过程需要计算机精确计算的也就是一个:
- 参数梯度误差的计算(使用反向传播BP算法计算)
其他的再不用计算,完全神经网络自己算,算好了把参数更新一下就完了。然后训练一段时间,被优化的神经网络就能够识别东西,构建艺术画,等等等。。
从这个成果进一步的发展,可以想象在未来几年将会出现的神经网络自动机(Neural Network Automata),这个名词我自己想的罗。就是一个完全的神经网络结构,然后完全没有具体的编程,也许需要的编程只要如下几行:
import Brain
import Go
go_env = Go() # 初始化围棋环境
go_brain = Brain() # 初始化一个围棋大脑,纯神经网络
go_brain.set_goal(win_go) # 设置大脑的目标
while true:
go_env.play_with(go_brain) # 让大脑在围棋中学习
if go_brain.win_rate > 0.9 :
print " Hey! I mastered Go! Tiny Humans! Haha.."
break
OK了,没了!然后这个“大脑”就根据给它的目标(学习围棋)开始自己学习啦!而且学的飞快!
只能用四个字来形容:
细思极恐!
这就是完全的智能了!一点人工都没有!
---------------------------------------------------------------------------------------------------------
已经说了很多,但为了让知友们多了解一些技术细节,我们接下来还是来稍微分析一下这篇文章的方法,所以,专业科普时间到啦!有一定基础的知友们欢迎继续往下阅读!
1 当前的优化方法及构建神经网络优化器
我们构建了一个神经网络模型,然后利用有标签的数据进行监督学习,输入样本,输出结果然后跟标签比较,得到误差,然后使用某种形式的梯度下降方法更新参数:
公式的后面就是这个模型参数的梯度,在这里就是具体的误差,使用反向传播计算得到。上面这个公式就是最基本的梯度下降的思想啦。但是这里没有考虑二阶梯度的影响,所以接下来针对这个优化的问题人们就设计了各种各样的优化方法。
那么如何神经网络化这个优化方法呢?
把公式的后半部分用神经网络替代,也就是
这里的g就是那个神经网络,是它内部的参数。输入是参数的梯度值或者说误差值,输出要更新的数值大小。
2 如何训练神经网络优化器
神经网络的选择没什么好说的,用RNN就对了。关键是怎么训练这个神经网络呢?如何评价它的好坏?
这里作者给出了一个损失函数的定义:
什么意思呢?就是最优化的参数下函数的期望值。这本来就是优化的目标嘛!
但是问题是这个定义需要的是最优化的参数呀?但我们并没有。所以,要训练,还得改改目标
还是直接贴图了,这里的是一个任意的大于0的权值。那么我们可以看到,当t=T并且=1时,上面的式子就和最初的目标等价。这里的T就是设定一个时间限制。所以这是一个次优目标。在实际试验总,设置为1,也就是每一个时间片都平等对待。
 还是直接贴图了,这里的
还是直接贴图了,这里的那么上面这个损失函数就可以使用梯度下降来更新参数。怎么做呢?
- 采样随机的函数f
- 使用反向传播计算损失函数梯度。
- 使用梯度下降更新参数
那么整个计算流程就是
这个流程每一个时间片的情况就是:
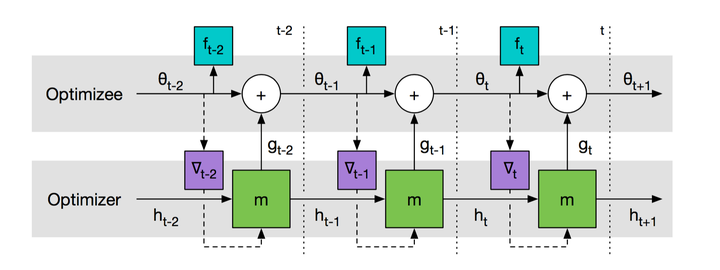 这个流程每一个时间片的情况就是:
这个流程每一个时间片的情况就是:优化器输入状态h,从被优化中得到梯度,进入神经网络m输出要更新的参数值g,然后结合被优化的参数 更新并输出函数结果f
3 具体的神经网络结构
从上面的基本流程可以看出,神经网络的输入是每一个被优化网络参数的梯度,那这个太多了,如果是很大的网络的话。这将导致优化器的网络变得特别庞大,这显然是不行的。
因此,需要能够使用一个小网络,但却可以输入巨量的参数信息。
怎么办?
就是让不同参数共用一个网络呗!
因为实际上网络训练的是参数梯度的变化情况,和参数的具体位置没什么关系。因此只需要使用一个共同的简单LSTM网络即可。这就是作者所称的Coordinatewise LSTM optimizer.上图所有的LSTM都共用参数,只是输入的隐层状态h不一样。这样我们就可以理解怎么来更新那么多的参数了。
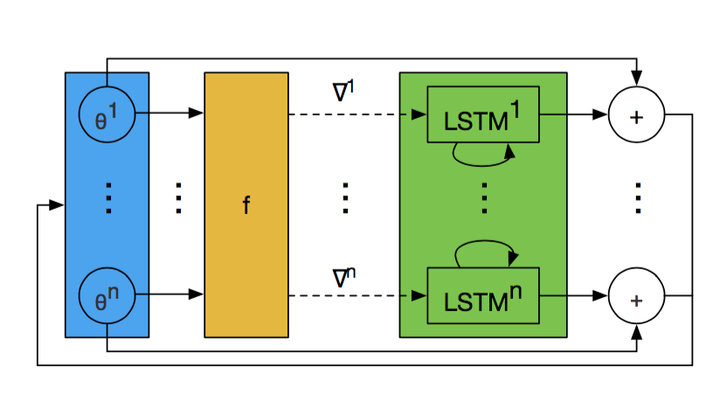 上图所有的LSTM都共用参数,只是输入的隐层状态h不一样。这样我们就可以理解怎么来更新那么多的参数了。
上图所有的LSTM都共用参数,只是输入的隐层状态h不一样。这样我们就可以理解怎么来更新那么多的参数了。4 让LSTM之间交互
目的当然是为了实现信息共享。
作者在这里提了两种做法:
- Global averaging cells。简单的说就是每一个LSTM中的cell输出平均化。也就是共用每个LSTM中的记忆。
- NTM-BFGS。这个就是再上面的基础上再加一个外部记忆模块,也就是神经图灵机模式。这样的设计如果得当可以让优化器学会牛顿法等方法。
5 如何实验
上面的分析我们少了一个重要细节,就是那个采样随机的函数,那到底是什么函数呢?
作者用了很简单的函数------二次方程,只不过是10维的二次方程。目的是计算其最小值。
然后随机采样里面的w和y参数就可以得到不同的函数啦。使用随机的函数训练,然后用新的采样的函数测试。确定了这个方法,就可以训练啦。
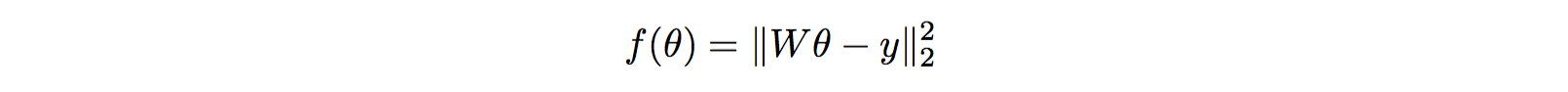 然后随机采样里面的w和y参数就可以得到不同的函数啦。使用随机的函数训练,然后用新的采样的函数测试。确定了这个方法,就可以训练啦。
然后随机采样里面的w和y参数就可以得到不同的函数啦。使用随机的函数训练,然后用新的采样的函数测试。确定了这个方法,就可以训练啦。然后经过训练的优化器就可以用来训练其他的网络比如MNIST,比如CIFAR-10,比如Neural Art。效果惊人,如前面所说。
6 小结
好了,就分析这么多,具体的实验相关的细节大家可以看原文罗。从上面的分析大家基本可以了解作者的实现思路。确实是很棒的做法。
最后说一句:
这就是人工智能最前沿!
引用:
Andrychowicz, Marcin, et al. "Learning to learn by gradient descent by gradient descent." arXiv preprint arXiv:1606.04474 (2016).