Gradient Descent
当成本函数位于图中凹坑的最底部时,即当其值最小时,我们就成功了。
我们这样做的方法是采用成本函数的导数,切线的斜率是该点的导数,它将为我们提供一个方向,我们沿下降最陡的方向逐步降低成本函数,每步的大小由参数α(称为学习率)确定。

算法
repeat until convergence:

where j=0,1 represents the feature index number.
注意:同步更新
每次迭代时,应该同时更新参数θ1,θ2,…,θn,否则在计算偏导数时将出现错误。

Gradient Descent Intuition
假设只有一个θ1参数时
其迭代算法如下
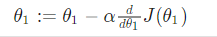
无论导函数为多少,θ1最终会收敛到其最小值,如下图当导函数为负数时,θ1的值会增加,当导函数为正数时,θ1的值会减小。

另外,我们应该调整学习率α,过小或过大都不适宜。

因为最终的局部最优解导函数为0,所以尽管学习率α不变,在收敛过程中导函数会逐步变小,梯度下降会自动逐渐采取更小的步子以接近最优解。

Gradient Descent For Linear Regression
当专门用于线性回归时,可以得到以下等式

因为该方法着眼于每个步骤的整个训练集中的每个数据,称为批量梯度下降。因为此处为线性回归提出的优化问题只有一个全局最优,因此梯度下降总会收敛到全局最小值(学习率α不太大)

