目录
FCN全卷积神经网络
FCN为深度学习在语义分割领域的开山之作,提出使用卷积层代替CNN中的全连接操作,生成热力图heat map而不是类别。

实现过程
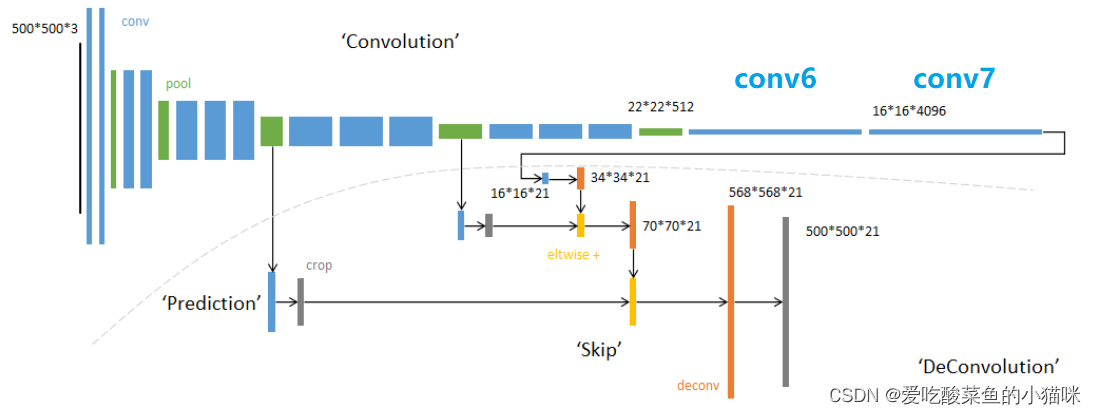
图1 FCN网络结构
包括全卷积过程以及反卷积过程。
全卷积:使用经典的CNN网络作为骨架网络,例如:Vgg ResNet AlexNet等。本文使用Vgg16作为骨架网络,提取feature map。
反卷积:将feature map上采样回去(通过转置卷积等上采样方式),恢复原图大小。
然后,将预测结果和真实label的像素一一对应分类,也称为像素级分类。从而,将分割问题转化为分类问题。
全卷积
蓝色指卷积操作,绿色为池化操作(图像宽高减半)。因此,按照图1,网络结构为:conv1(2层卷积)、pool1、conv2(2层卷积)、pool2、conv3(3层卷积)、pool3(向下输出预测的第一个分支)、conv4(3层卷积)、pool4(向下输出预测的第二个分支)、conv5(3层卷积)、pool5、conv6、conv7(向下输出的最后一个分支)。提取得到pool3 pool4 conv7,用于后面的特征融合以及反卷积操作。
反卷积

FCN分为FCN-32S,FCN-16s,FCN-8s三种网络结构。
FCN-8s获取过程:conv7特征进行2倍上采样,与pool4融合,将融合后的进行2倍上采样,与pool3融合,最后进行8倍上采样得到原图大小的特征图。FCN-32s获取过程:conv7直接32倍上采样得到原图大小的特征图。
由于FCN-8s综合较多层的特征,因此效果最好;而FCN-32s只使用了最后一层conv7上采样32倍进行预测,特征图较小,丢失了很多信息。
注意:FCN-8s (conv7 2倍上采样 + pool4) 2倍上采样 + pool3 -> 8倍上采样
卷积过程中,特征经过pool操作,h w为奇数时,池化后的特征图的h1 w1不一定是原来h w的1/2,因此转置卷积2倍上采样后的shape与原来的h w有区别,因此需先通过插值方式torch.nn.functional.interpolate方式调整特征图大小,确保可以和上一层的特征融合。
FCN的三点创新
(1)全卷积:将传统CNN最后的全连接层转化为卷积层,实现分类器变为稠密预测dense prediction(即分割)。
具体操作:把原来CNN操作中的全连接变成卷积操作(见图1中conv6、conv7),此时图像的featureMap数量改变但是图像大小依然为原图的1/32,图像不再叫featureMap而是叫heatMap。
(2)上采样:由于骨架网络提取特征的过程采取了一系列下采样(池化操作),使得特征图大小减小,为了得到和原图大小一致的预测层,采用上采样(如转置卷积操作)
(3)跳跃结构:类似于ResNet,将不同层的feature map进行融合,在分类预测时可以综合多层信息。
code
FCN-8s实现过程,其他网络结构可直接修改FCN类中的forward函数实现。
import torch
from torch import nn
from torchvision.models import vgg16
import torch.nn.functional as F
def vgg_block(num_convs, in_channels, out_channels):
"""
vgg block: Conv2d ReLU MaxPool2d
"""
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=(3, 3), padding=1))
blk.append(nn.ReLU(inplace=True))
blk.append(nn.MaxPool2d(kernel_size=(2, 2), stride=2))
return blk
class VGG16(nn.Module):
def __init__(self, pretrained=True):
super(VGG16, self).__init__()
features = []
features.extend(vgg_block(2, 3, 64))
features.extend(vgg_block(2, 64, 128))
features.extend(vgg_block(3, 128, 256))
self.index_pool3 = len(features) # pool3
features.extend(vgg_block(3, 256, 512))
self.index_pool4 = len(features) # pool4
features.extend(vgg_block(3, 512, 512)) # pool5
self.features = nn.Sequential(*features) # 模型容器,有state_dict参数(字典类型)
""" 将传统CNN中的全连接操作,变成卷积操作conv6 conv7 此时不进行pool操作,图像大小不变,此时图像不叫feature map而是heatmap"""
self.conv6 = nn.Conv2d(512, 4096, kernel_size=1) # conv6
self.relu = nn.ReLU(inplace=True)
self.conv7 = nn.Conv2d(4096, 4096, kernel_size=1) # conv7
# load pretrained params from torchvision.models.vgg16(pretrained=True)
if pretrained:
pretrained_model = vgg16(pretrained=pretrained)
pretrained_params = pretrained_model.state_dict() # state_dict()存放训练过程中需要学习的权重和偏置系数,字典类型
keys = list(pretrained_params.keys())
new_dict = {}
for index, key in enumerate(self.features.state_dict().keys()):
new_dict[key] = pretrained_params[keys[index]]
self.features.load_state_dict(new_dict) # load_state_dict必须传入字典对象,将预训练的参数权重加载到features中
def forward(self, x):
pool3 = self.features[:self.index_pool3](x) # 图像大小为原来的1/8
pool4 = self.features[self.index_pool3:self.index_pool4](pool3) # 图像大小为原来的1/16
# pool4 = self.features[:self.index_pool4](x) # pool4的第二种写法,较浪费时间(从头开始)
pool5 = self.features[self.index_pool4:](pool4) # 图像大小为原来的1/32
conv6 = self.relu(self.conv6(pool5)) # 图像大小为原来的1/32
conv7 = self.relu(self.conv7(conv6)) # 图像大小为原来的1/32
return pool3, pool4, conv7
class FCN(nn.Module):
def __init__(self, num_classes, backbone='vgg'):
"""
Args:
num_classes: 分类数目
backbone: 骨干网络 VGG
"""
super(FCN, self).__init__()
if backbone == 'vgg':
self.features = VGG16() # 参数初始化
# 1*1卷积,将通道数映射为类别数
self.scores1 = nn.Conv2d(4096, num_classes, kernel_size=1) # 对conv7操作
self.relu = nn.ReLU(inplace=True)
self.scores2 = nn.Conv2d(512, num_classes, kernel_size=1) # 对pool4操作
self.scores3 = nn.Conv2d(256, num_classes, kernel_size=1) # 对pool3操作
self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=8, stride=8) # 转置卷积
self.upsample_2x = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=2, stride=2)
def forward(self, x):
b, c, h, w = x.shape
pool3, pool4, conv7 = self.features(x)
conv7 = self.relu(self.scores1(conv7))
pool4 = self.relu(self.scores2(pool4))
pool3 = self.relu(self.scores3(pool3))
# 融合之前调整一下h w
conv7_2x = F.interpolate(self.upsample_2x(conv7), size=(pool4.size(2), pool4.size(3))) # conv7 2倍上采样,调整到pool4的大小
s=conv7_2x+pool4 # conv7 2倍上采样与pool4融合
s=F.interpolate(self.upsample_2x(s),size=(pool3.size(2),pool3.size(3))) # 融合后的特征2倍上采样,调整到pool3的大小
s = pool3 + s # 融合后的特征与pool3融合
out_8s=F.interpolate(self.upsample_8x(s) ,size=(h,w)) # 8倍上采样得到 FCN-8s,得到和原特征x一样大小的特征
return out_8s
if __name__=='__main__':
model = FCN(num_classes=12)
fake_img=torch.randn((4,3,360,480)) # B C H W
output_8s=model(fake_img)
print(output_8s.shape)
输出:
torch.Size([4, 12, 360, 480])