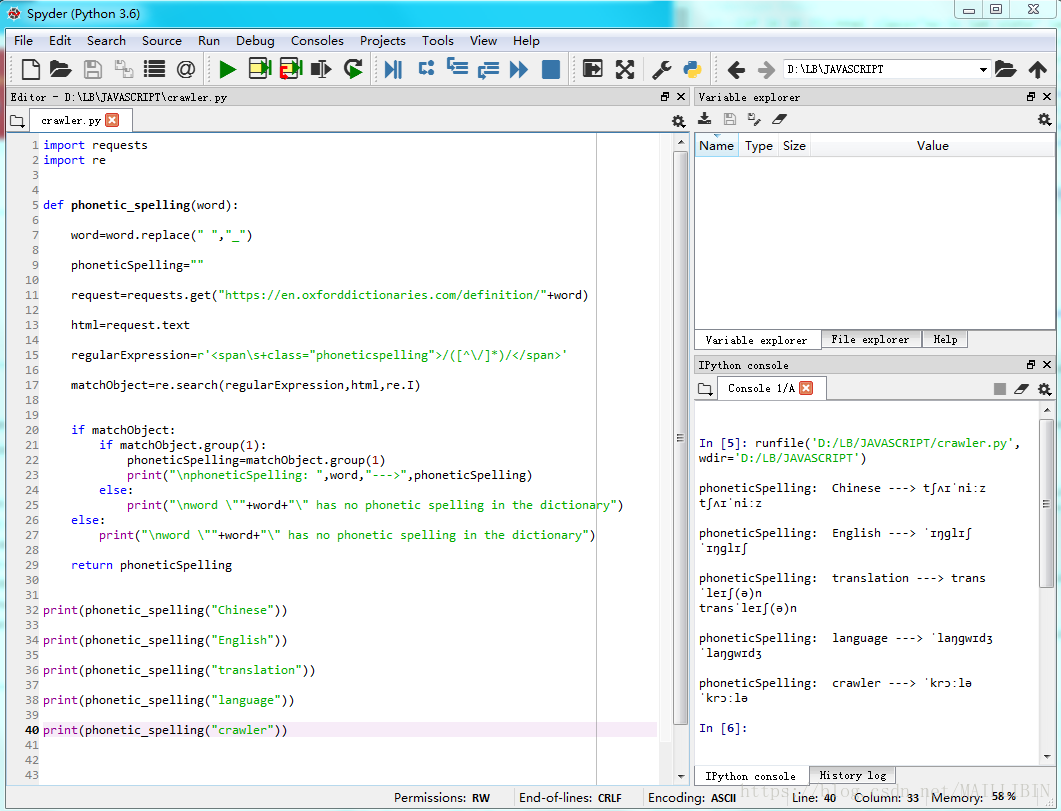
import requests
import re
def phonetic_spelling(word):
word=word.replace(" ","_")
phoneticSpelling=""
#url的格式有规律
request=requests.get("https://en.oxforddictionaries.com/definition/"+word)
html=request.text
#查看网页发现音标所处的行HTML格式有规律 使用正则表达式描述
regularExpression=r'<span\s+class="phoneticspelling">/([^\/]*)/</span>'
matchObject=re.search(regularExpression,html,re.I)
if matchObject:
if matchObject.group(1):
phoneticSpelling=matchObject.group(1)
print("\nphoneticSpelling: ",word,"--->",phoneticSpelling)
else:
print("\nword \""+word+"\" has no phonetic spelling in the dictionary")
else:
print("\nword \""+word+"\" has no phonetic spelling in the dictionary")
return phoneticSpelling
#测试
print(phonetic_spelling("Chinese"))
print(phonetic_spelling("English"))
print(phonetic_spelling("translation"))
print(phonetic_spelling("language"))
print(phonetic_spelling("crawler"))
python requests做爬虫爬取oxford词典单词音标
猜你喜欢
转载自blog.csdn.net/MAILLIBIN/article/details/83152531
今日推荐
周排行