爬取扇贝单词
======================

==================================================================================
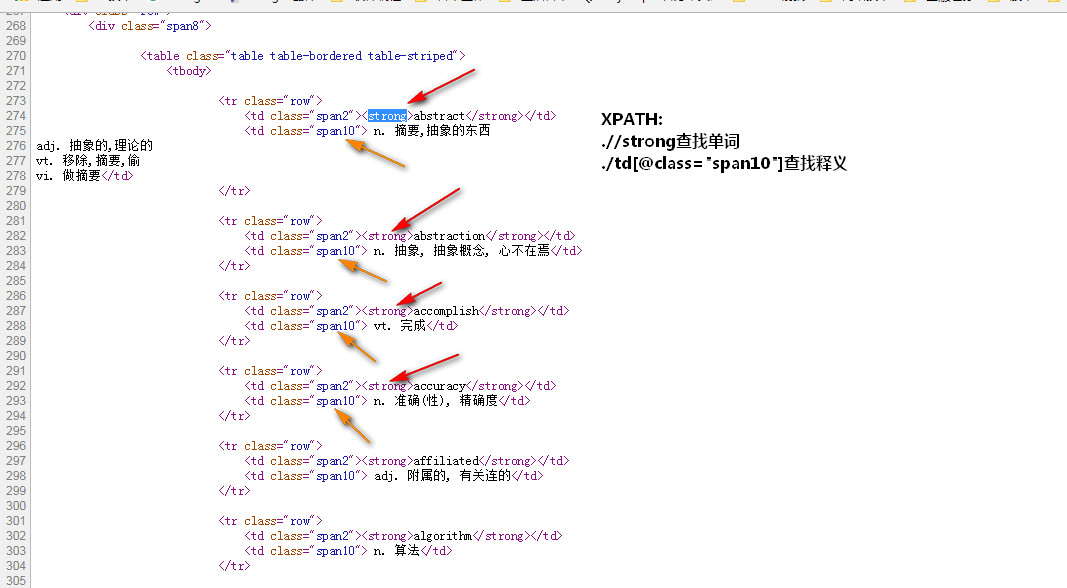
<tr>
<td> </td>
<td> </td>
</tr>
==========================================================================
结果示例:
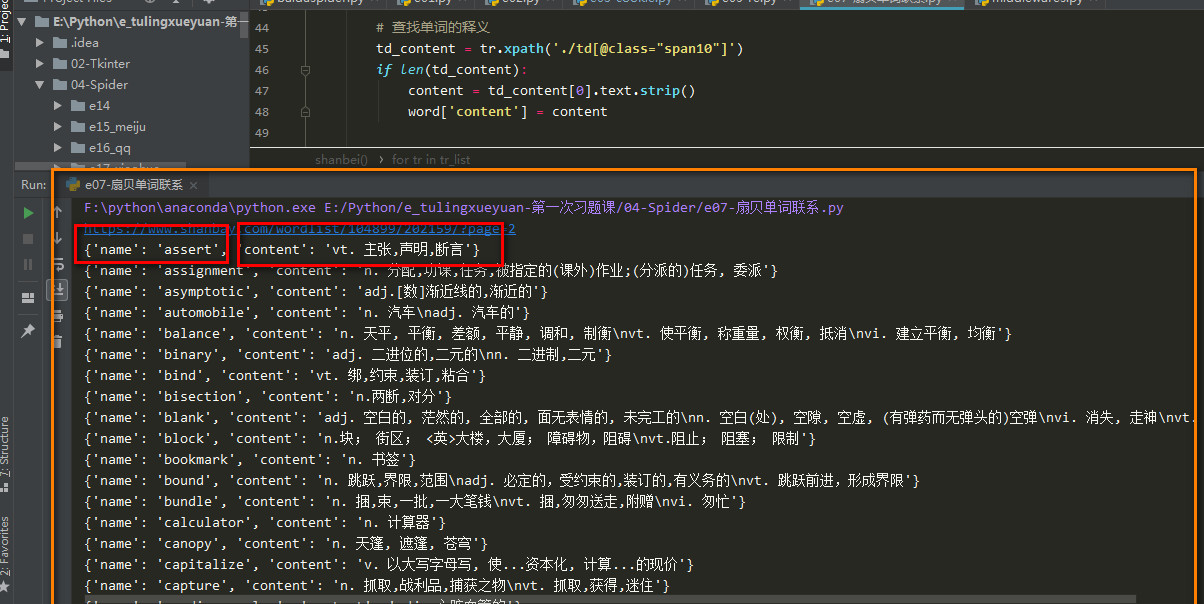
====================================================
1 ''' 2 扇贝单词: 3 1. 把python单词列表download下来 4 2. 主要联系目的是xpath 5 3. 理论上讲不需要登录 6 4. https://www.shanbay.com/wordlist/104899/202159/ 7 ''' 8 from urllib import request 9 from lxml import etree 10 11 import json 12 13 #词汇表 14 words = [] 15 16 17 def shanbei(page): 18 url = "https://www.shanbay.com/wordlist/104899/202159/?page=%s"%page 19 print(url) 20 21 rsp = request.urlopen(url) 22 23 html = rsp.read() 24 25 #解析html 26 html = etree.HTML(html) 27 28 tr_list = html.xpath("//tr") 29 30 31 # 遍历每个tr元素,每一个tr对应一个单词和介绍 32 for tr in tr_list: 33 ''' 34 查相应的单词和介绍 35 ''' 36 word = {} 37 38 strong = tr.xpath('.//strong') 39 if len(strong): 40 # strip把找到的内容去掉空格 41 name = strong[0].text.strip() 42 word['name'] = name 43 44 # 查找单词的释义 45 td_content = tr.xpath('./td[@class="span10"]') 46 if len(td_content): 47 content = td_content[0].text.strip() 48 word['content'] = content 49 50 print(word) 51 52 if word != {}: 53 words.append(word) 54 55 56 if __name__ == '__main__': 57 58 shanbei(2)