-
准备
-
实验原理
-
代码优化
-
GUI界面
-
整合代码
准备
我测试使用的Python版本为3.5。
实验原理
使用urllib.request发送请求
解析服务器返回的数据并提取关键字
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- url: 需要打开的网址
- data:Post提交的数据
- timeout:设置网站的访问超时时间
直接用urllib.request模块的urlopen()获取页面,page的数据格式为bytes类型,需要decode()解码,转换成str类型。
1.首先打开有道首页,点击审查元素

2.点击翻译,从元素中找到我们要查询的结果

3.找到form data,模拟浏览器提交数据。

4.了解urllib

5.模拟客户端向服务器发起请求,取得服务器返回的文件并进行比对。
需要使用urllib.parse.urlencode将data数据转换成标准格式


6.通过索引提取关键数据
我们虽然取得了数据,但是数据被封装成json格式。Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式。Json最广泛的应用是作为AJAX中web服务器和客户端的通讯的数据格式。现在也常用于http请求中,所以对json的各种学习,是自然而然的事情。这里我们先通过json.loads()函数是将json格式数据转换为字典。

代码优化
1.修改user-agent模拟浏览器发出请求

2.使用代理ip模拟人工访问
urllib2中通过ProxyHandler来设置使用代理服务器


GUI界面
Tkinter: Tkinter 模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 Macintosh 系统里

3.简化代码
data里面的数据是不是都是必需的呢,有了这个疑问之后,小编立马进行测试,结果发现除了提交内容和指定内容格式为json的信息外,其他都可以删除。
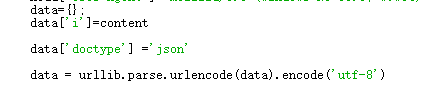
整合代码

大功告成
