版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38736612/article/details/81415661
前言
学了requests库和正则表达式之后我们可以做个简单的项目来练练手咯!先附上项目GitHub地址,欢迎star和fork,也可以pull request哦~
地址:https://github.com/zhangyanwei233/Maoyan100.git
正文开始哈哈哈
第一步、对目标站点分析
目标站点:http://maoyan.com/board/4
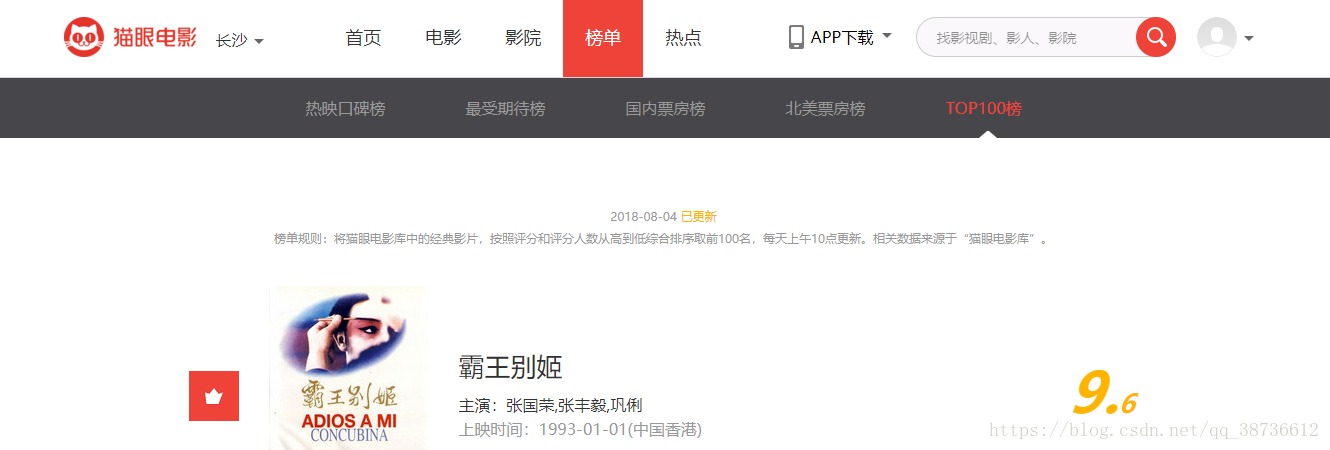

我们可以看到,网页每个界面展示10部电影,一共10页,注意!!!网页往下跳转时url的特点:
第一页:http://maoyan.com/board/4
第二页:http://maoyan.com/board/4?offset=10
第三页:http://maoyan.com/board/4?offset=20
……
我们不妨先来爬取第一页的数据,因为其他的都是类似的。
鼠标右键,审查元素查看网页源代码:
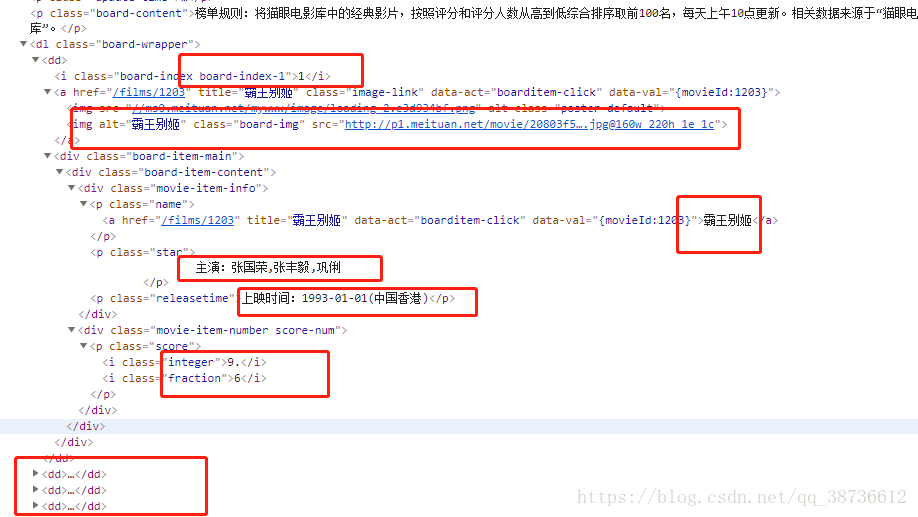
我们发现,每部电影的信息都在< d d>标签内,我们要爬取的数据信息有排名、链接、电影名、主演、上映时间、评分。
我们分析之后就要开始干活啦!
抓取网页内容
利用requests请求目标站点,得到单个网页HTML代码,返回结果。
正则表达式分析
根据HTML代码分析得到电影的名称、主演、上映时间、评分、图片链接等信息。
保存至文件
通过文件的形式将结果保存,每一部电影一个结果一行json字符串。
开启循环和多线程
对多页内容遍历,开启多线程快速抓取。
# 正则表达式
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)"'
'.*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">'
'(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)项目源代码请到GitHub获取