周末闲来无事,本来想看一看书的,结果也没看进去(RNG输的我真是糟心。。。)
于是就用python写了一个爬虫,来爬取小说来看,防止下次还要去网上找书看。
我们先找一个看名著的小说网
我们打开http://www.mingzhuxiaoshuo.com/ 名著小说网来,首先看到的是这样的
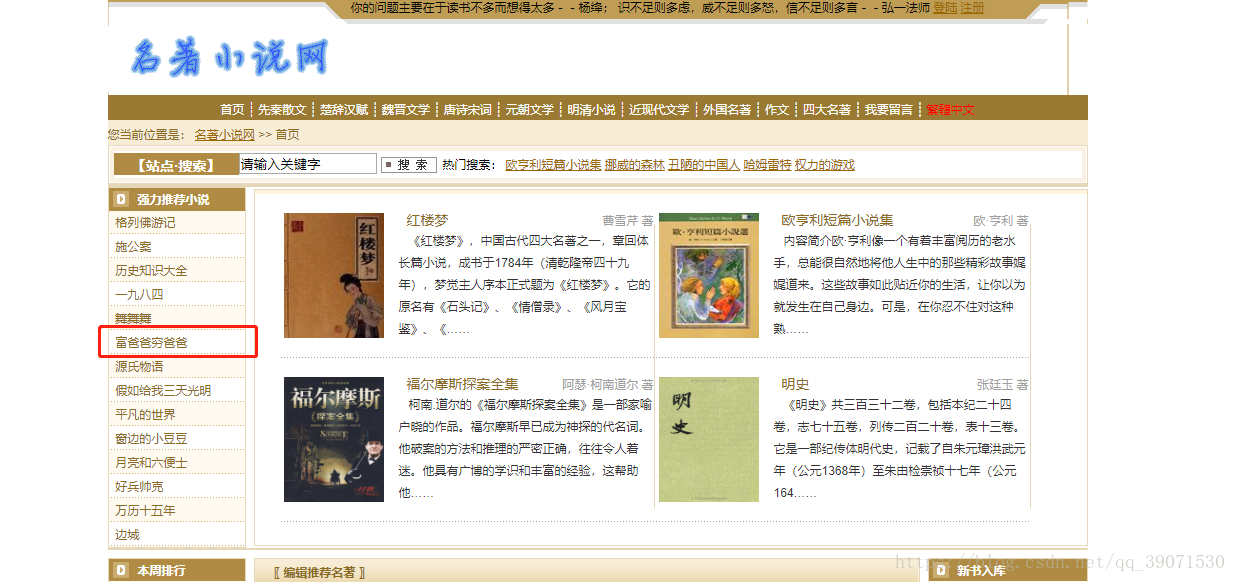
我们如上图选一个大家耳熟能详的书,《富爸爸穷爸爸》,我们点开来,点击在线阅读
出现了这本书的目录,http://www.mingzhuxiaoshuo.com/waiguo/154/,这个url是我们首先爬取的网页,我们先将每一章节的url爬取出来。
我们打谷歌的开发工具 F12,去找本网站的目录规律
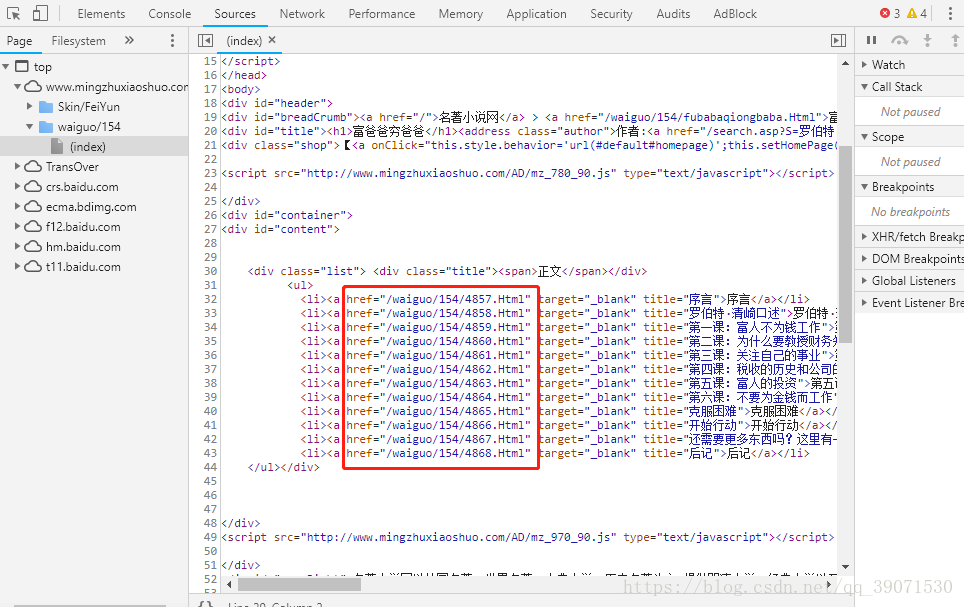
我们发现每一个目录都有一个href,我们点开了一章,查看他的url,发现是这样的,如下图http://www.mingzhuxiaoshuo.com/waiguo/154/4857.Html。
我们结合上面的一系列目录,寻找规律。可以确认的每一章的url = www.mingzhuxiaoshuo.com + 目录的href
我们于是可以开始写代码了
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
"""
说明:下载《穷爸爸富爸爸》
Modify:
2018-10-20,星期六
Author:
ligz
"""
if __name__ == '__main__':
server_url = 'http://www.mingzhuxiaoshuo.com'
target_url = 'http://www.mingzhuxiaoshuo.com/waiguo/154/'
req = requests.get(url = target_url)
html = req.text.encode("latin1").decode("gbk")
bf = BeautifulSoup(html,'lxml')
texts = bf.find_all('div', 'list')
bf_a = BeautifulSoup(str(texts),'lxml')
a = bf_a.find_all('a')
for i in a:
print(i.string, server_url+i.get('href'))我们运行代码可以看到,打印出来的是每一章节的目录名字和对应的url。
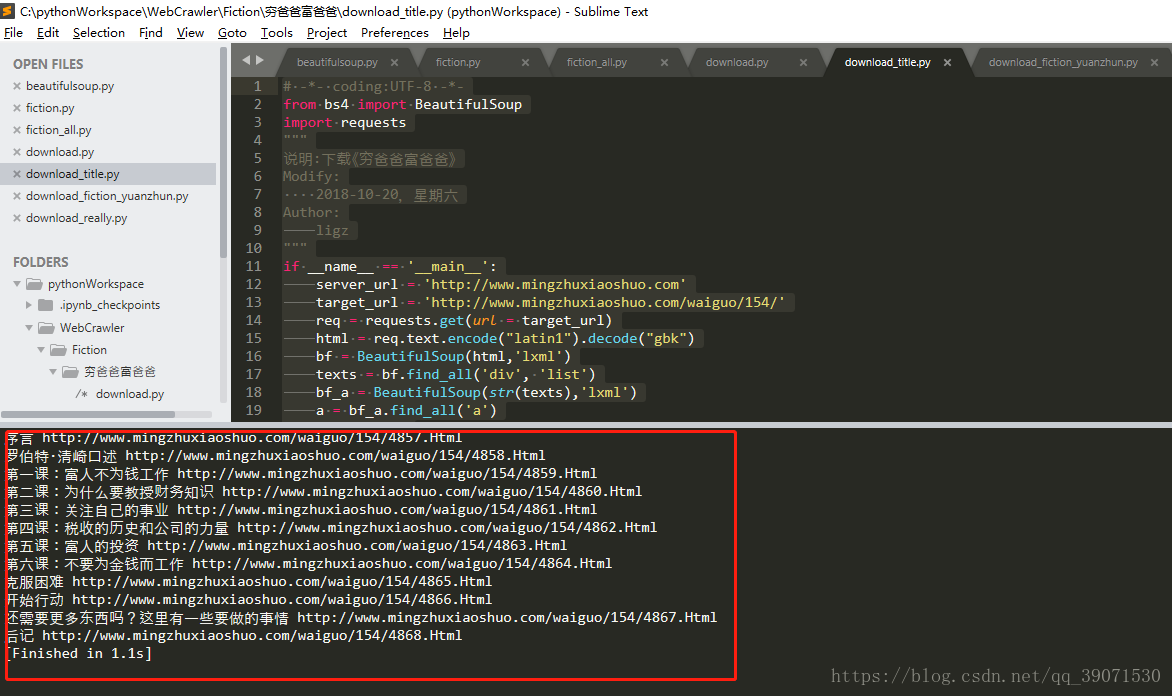
这里用的是
requests去获取网页的内容,和BeautifulSoup去对网页的html提取数据
我们用requests.get(http://www.mingzhuxiaoshuo.com/waiguo/154/)请求小说目录网页的html
用BeautifulSoup去寻找了名字是 list 的div。
texts = bf.find_all('div', 'list')
去找 这个div下面的a标签
a = bf_a.find_all('a')

我们已经成功了一半了,另一半当然是重头戏——爬取每一章节的内容
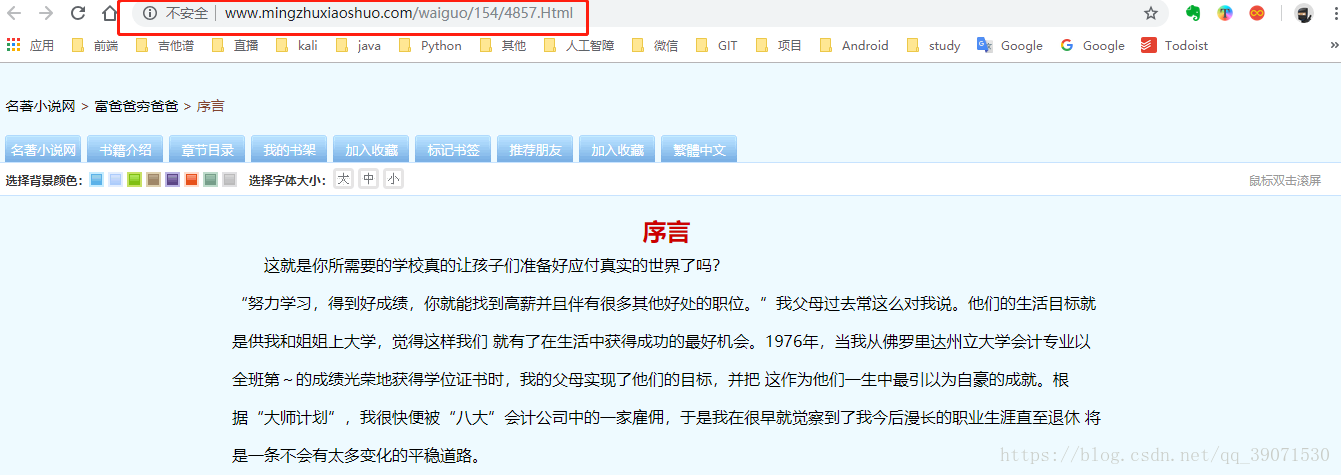
我们点开序言http://www.mingzhuxiaoshuo.com/waiguo/154/4857.Html,打开F12开发者工具,看到的html结构如下
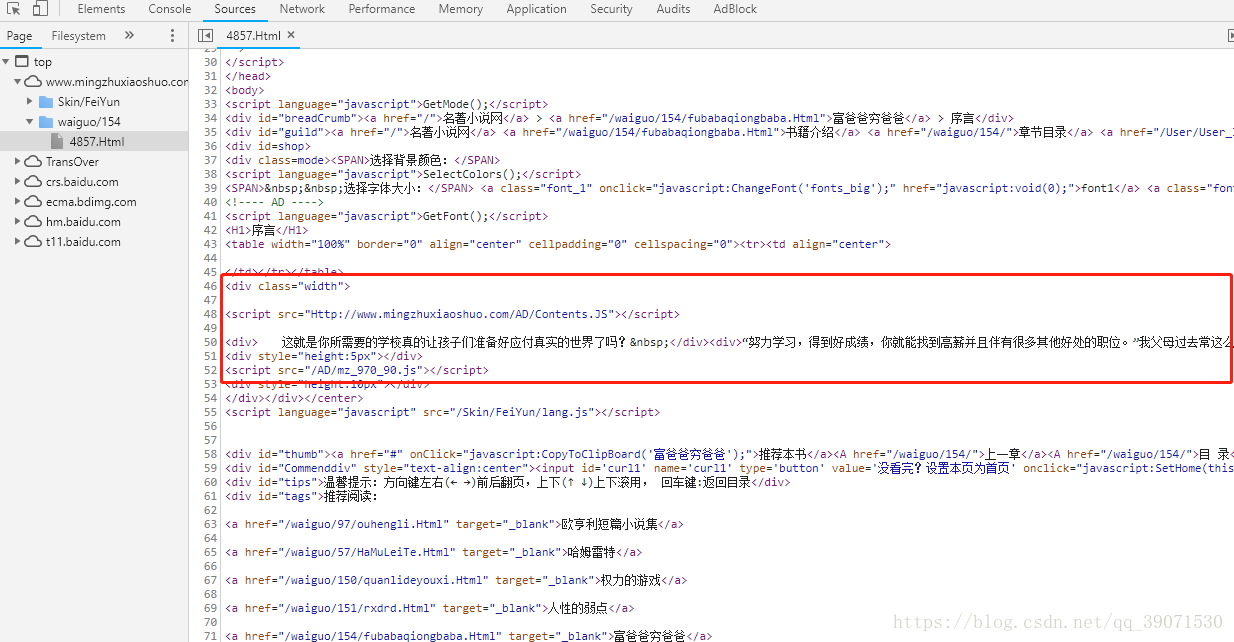
我们发现我们需要的内容在class="width"的div下,于是我们学习上面的写法,给大家演示一下。
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
"""
说明:下载《穷爸爸富爸爸》
Modify:
2018-10-20,星期六
Author:
ligz
"""
if __name__ == '__main__':
target = 'http://www.mingzhuxiaoshuo.com/waiguo/154/4857.Html'
req = requests.get(url = target)
html = req.text.encode("latin1").decode("gbk")
bf = BeautifulSoup(html,'lxml')
texts = bf.find_all('div', 'width')
bf_div = BeautifulSoup(str(texts),'lxml')
div = bf_div.find_all('div')
txt = ''
for i in div:
if i.string is not None:
txt = txt + i.string +'\n\n'
print(txt)我们用BeautifulSoup寻找到上面class="width"的div,
texts = bf.find_all('div', 'width')
再讲他作为一个html结构,再去寻找下面每一个div
div = bf_div.find_all('div')
运行程序,我们于是得到了整个序言的内容
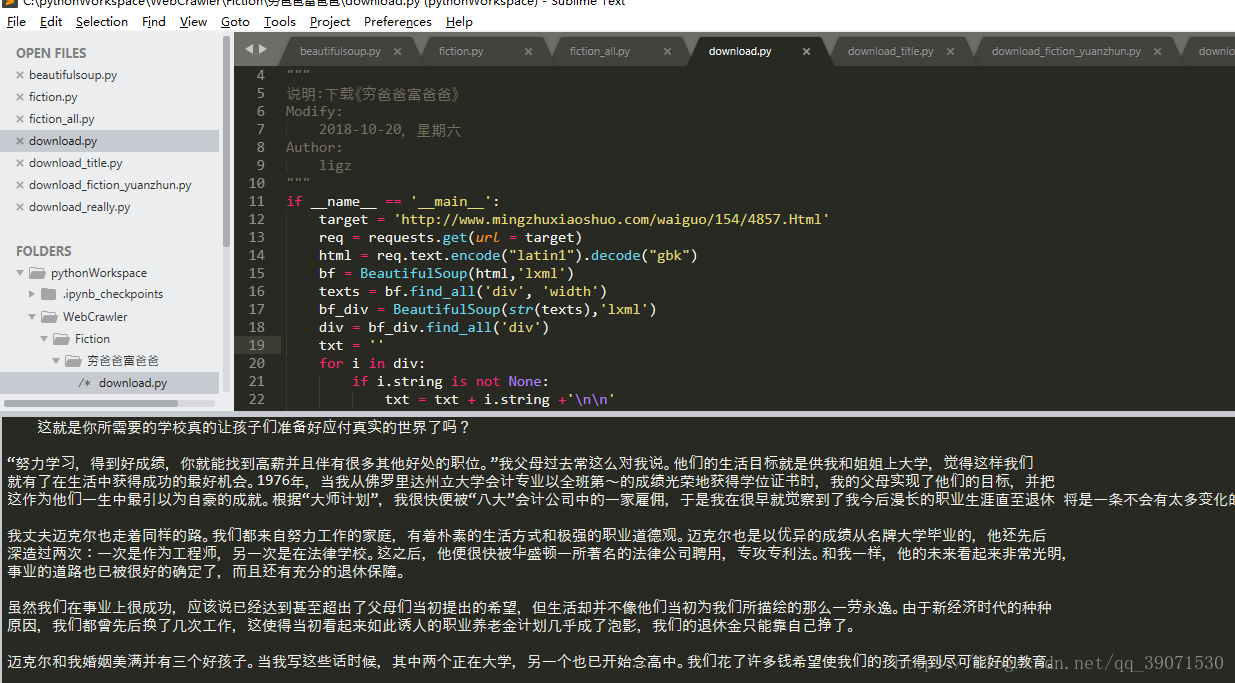
我们得到了目录url和每一个url下面的内容,我们就可以完成整个爬取的工作。
下面是完整的代码,运行即可爬取成功
from bs4 import BeautifulSoup
import requests, sys
"""
类说明:下载《穷爸爸富爸爸》
Modify:
2018-10-20,星期六
Author:
ligz
"""
class download(object):
def __init__(self):
self.server_url = 'http://www.mingzhuxiaoshuo.com'
self.target_url = 'http://www.mingzhuxiaoshuo.com/waiguo/154/'
self.names = []
self.urls = []
self.nums = 0
"""
获取下载的链接
获取目录
"""
def download_url(self):
req = requests.get(url = self.target_url)
html = req.text.encode("latin1").decode("gbk")
bf = BeautifulSoup(html,'lxml')
texts = bf.find_all('div', 'list')
bf_a = BeautifulSoup(str(texts),'lxml')
a = bf_a.find_all('a')
self.nums = len(a)
for i in a:
self.names.append(i.string)
self.urls.append(self.server_url+i.get('href'))
"""
获取每一章节的内容
"""
def download_content(self,target_url):
req = requests.get(url = target_url)
html = req.text.encode("latin1").decode("gbk")
bf = BeautifulSoup(html,'lxml')
texts = bf.find_all('div', class_='width')
bf_div = BeautifulSoup(str(texts),'lxml')
div = bf_div.find_all('div')
txt = ''
for i in div:
if i.string is not None:
txt = txt + i.string +'\n\n'
return txt
def writer(self, name, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == '__main__':
dl = download()
dl.download_url()
print("开始下载")
for i in range(dl.nums):
dl.writer(dl.names[i], '穷爸爸富爸爸.txt', dl.download_content(dl.urls[i]))
sys.stdout.write("已下载:%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush
print('已下载完成')
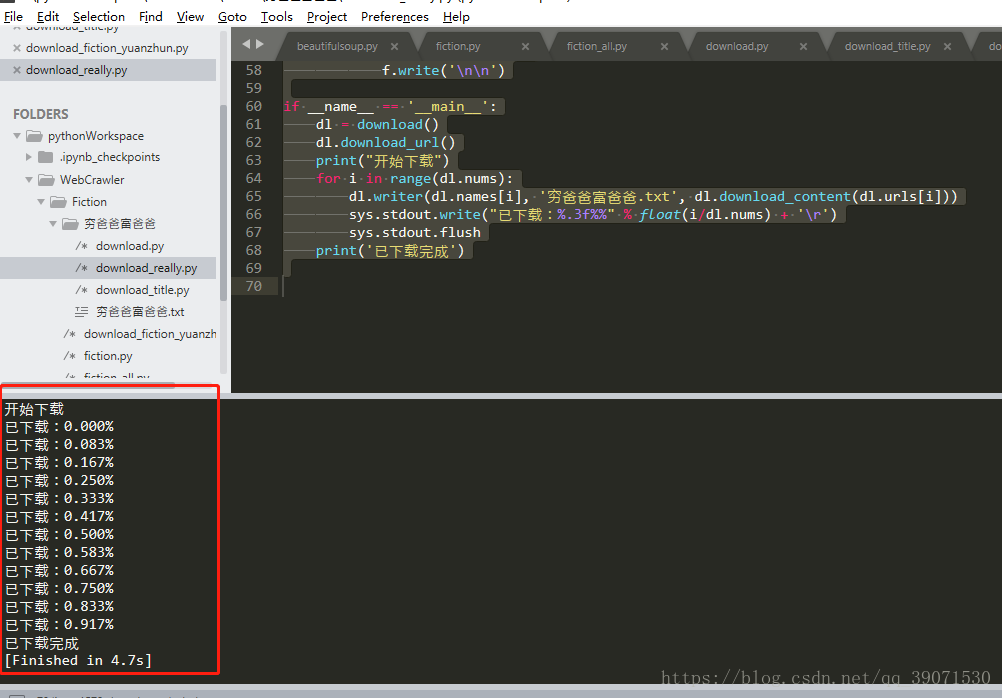
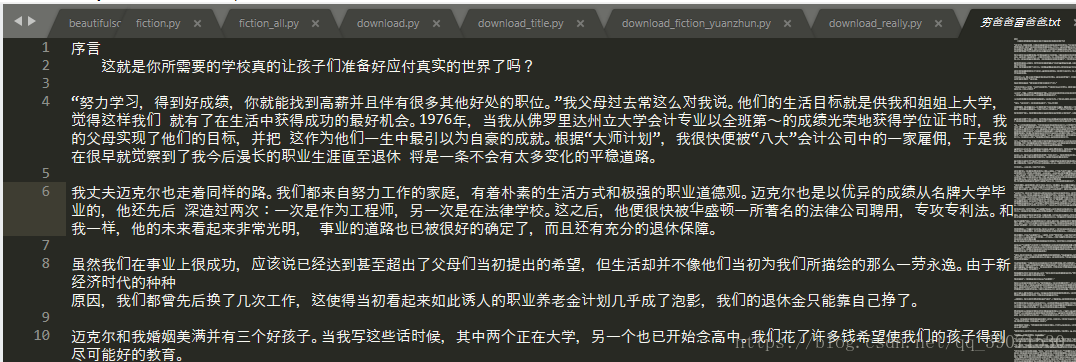
我们看到已经成功的爬取了整本书的内容
可以放到手机上下次有时间再看了
本文可以转载,但需注明出处https://blog.csdn.net/qq_39071530/article/details/83276675