第二章:单变量线性回归
编程语言
2019-01-12 13:50:48
阅读次数: 0
单变量线性回归(Univariate linear regression)
介绍
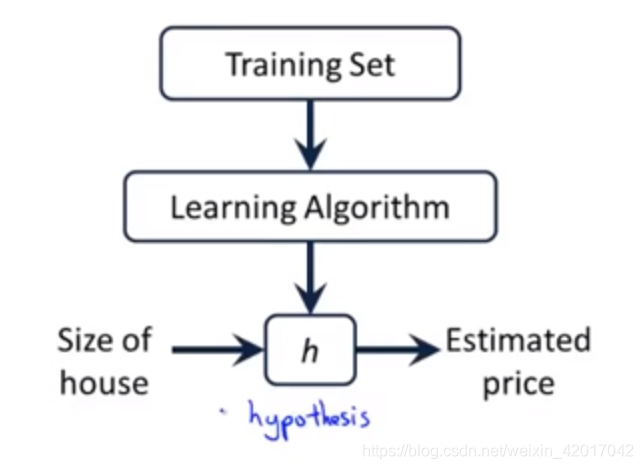
一个数据集也被称为一个训练集
- 数据集的表示
m :数据集样本容量
(x,y) :一个样本,x为输入,y为输出
x(i) :第i个样本的输入 ,
y(i):第i个样本的输出
- 学习算法的任务就是根据训练集来输出一个函数,这个函数能够根据input来预测output
定义代价函数(平方误差代价函数:square error cost function )
J(θ0,θ1)=2m1i∑n(hθ(x(i))−y(i))2
其中
hθ(xi)=θ0+θ1x(i)
为我们要求出的预测函数。
我们要做的事是求出
θ0和θ1使得代价函数最小。
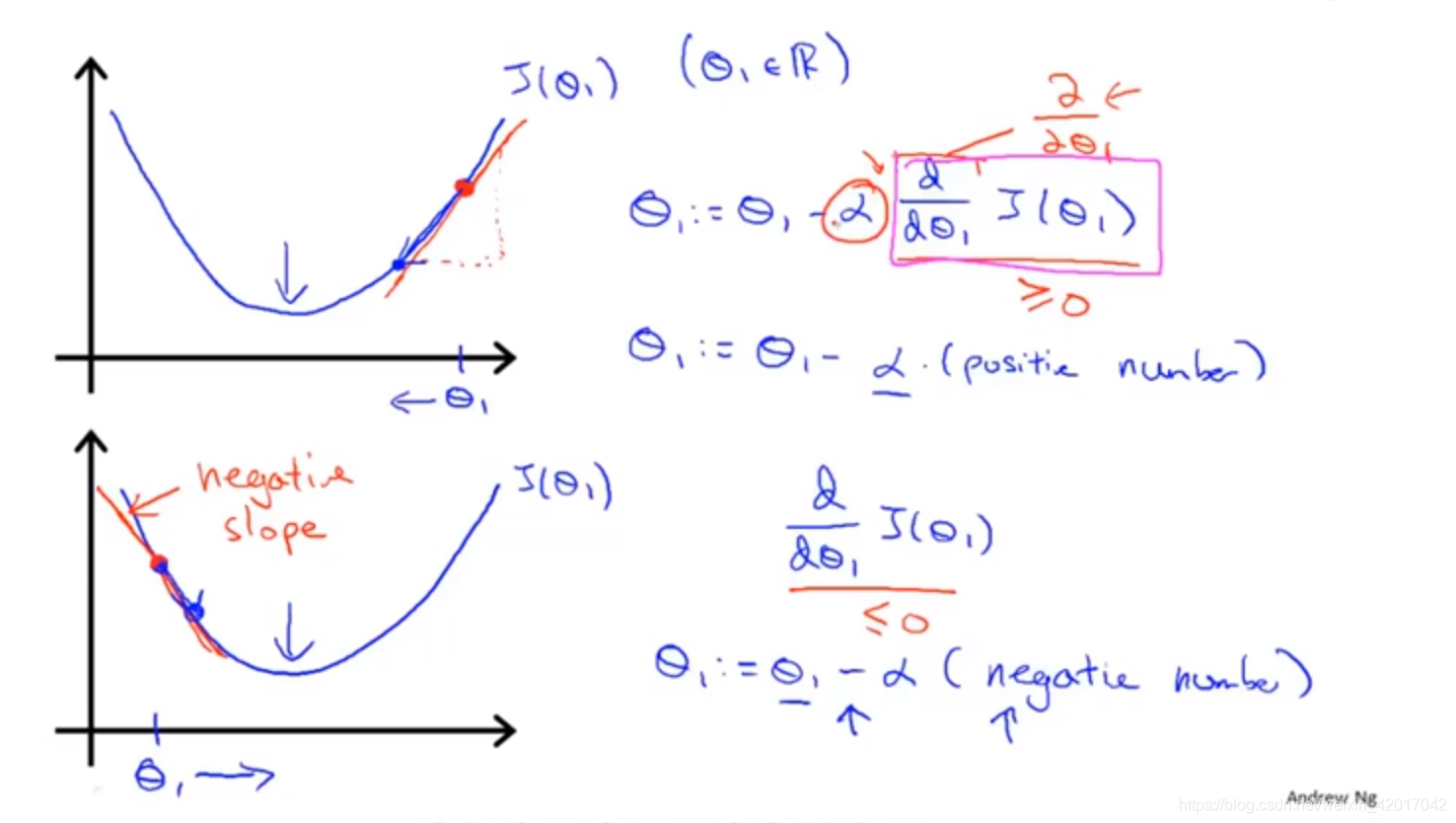
- ** 梯度下降法**( Gradient Descent)
给出一个函数
J(θ0,θ1,...,θn)梯度下降法可以求得其取最小值时,参数
θ0,θ1,...θn的值。
- 过程(此处的梯度下降法为“Batch” Gradient Descent,每一步更新都会遍历整个数据集,还有其他的梯度下降法)
repeat until convergence {
θj:=θj−α∂θj∂J(θ0,θ1)
(j=0 and j=1)
}
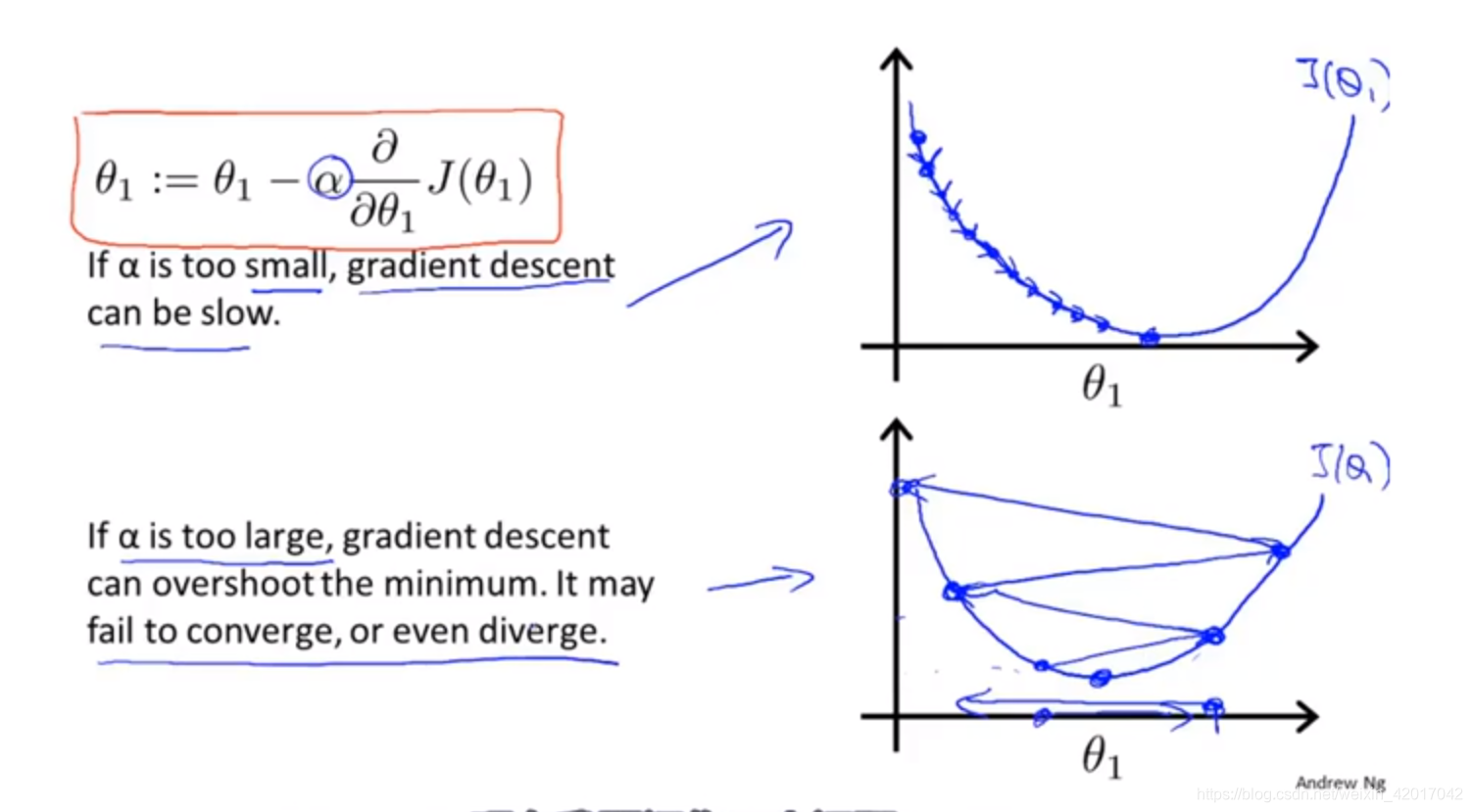
α被称为学习率(learning rate),它决定了梯度下降的速度
- 同时更新
temp0:=θ0−∂θ0∂J(θ0,θ1)
temp1:=θ1−∂θ1∂J(θ0,θ1)
θ0:=temp0
θ1:=temp1
- 梯度下降法单变量时的直观解释
- 学习率
α的直观解释
线性回归的梯度下降
根据公式,求偏导代入即可

转载自blog.csdn.net/weixin_42017042/article/details/86353915