-
实验目标
搭建一个Hadoop系统,包含分布式文件系统HDFS、分布式计算框架MapReduce。
-
实验原理
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上运行或重新运行。此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。它使应用程序与成千上万的独立计算的计算机和PB级的数据连接起来。
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。当前,HDFS不支持用户磁盘配额和访问权限控制,也不
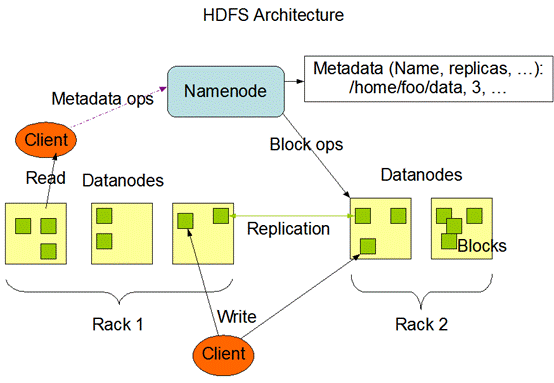
支持硬链接和软链接。但是HDFS架构并不妨碍实现这些特性。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来。应用程序可以设置HDFS保存的文件的副本数目。文件副本的数目称为文件的副本系数,这个信息也是由Namenode保存的。
Yarn是Hadoop集群的资源管理系统。Hadoop2.0对MapReduce框架做了彻底的设计重构,Hadoop2.0中的MapReduce称为MRv2或者Yarn。
重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。
上图中 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
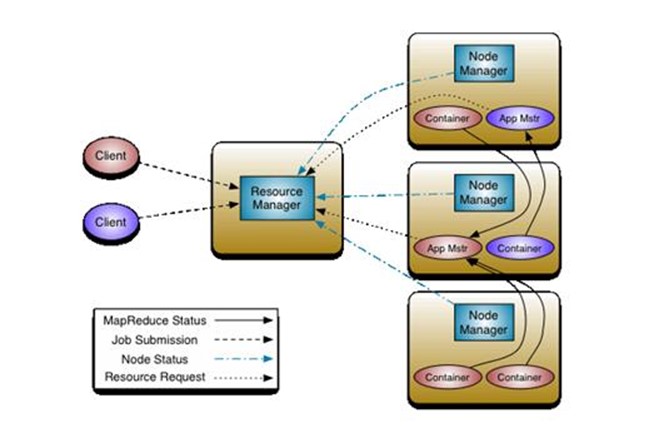
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
-
实验环境准备
三台本地Vmware虚拟机,均装有CentOS 7.2操作系统和Oracle JDK 1.8。各机器配置如下表:
| 名称 |
IP |
运行内存 |
存储 |
Cores |
启动进程 |
|
node1 |
172.16.86.130 |
1GB |
<100GB |
4 |
NameNode ResourceManager JobHistory SecondaryNamenode |
| node2 |
172.16.86.133 |
1GB |
<100GB |
4 |
DataManager NodeManager |
| node3 |
172.16.86.134 |
1GB |
<100GB |
4 |
DataManager NodeManager |
-
实验过程
3.1下载
下载hadoop的binary压缩包,下载链接:https://hadoop.apache.org/releases.html。并传到三台虚拟机上。本实验使用的hadoop-2.9.2。
3.2安装
在每个节点上,解压hadoop的安装包到安装目录即可。
3.3配置
3.3.1 编辑/etc/hosts,添加如下内容
172.16.86.130 node1
172.16.86.133 node2
172.16.86.134 node3
3.3.2配置从node1到其他节点的无密码登陆
3.3.3进入安装目录,编辑etc/Hadoop/hadoop-env.sh,修改JAVA_HOME为JDK安装目录,如下图:
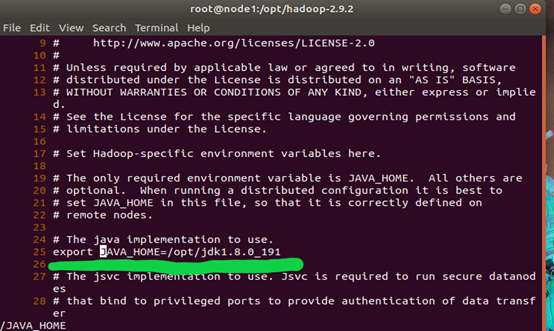
在每个节点上都进行这步操作。
3.3.4 配置core-site.xml
进入hadoop安装目录,编辑etc/hadoop/core-site.xml文件,编辑结果如下图所示:

在每个节点上都进行这步操作。
3.3.5 配置hdfs-site.xml
进入hadoop安装目录,编辑etc/hadoop/hdfs-site.xml,编辑结果如下图所示:
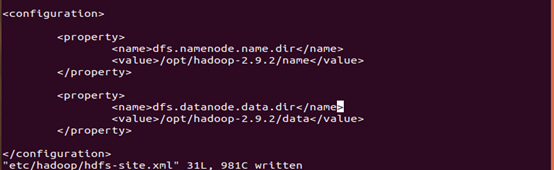
在每个节点上都进行这步操作。
3.3.6 配置yarn-site.xml
进入hadoop安装目录,编辑etc/hadoop/yarn-site.xml,编辑结果如下图所示:
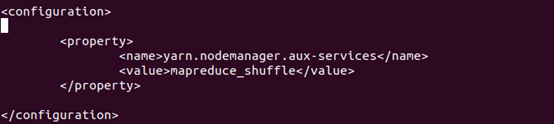
在每个节点上都进行这步操作。
3.3.7 配置mapreduce-site.xml
进入hadoop安装目录,编辑etc/Hadoop/mapreduce-site.xml,编辑结果如下图所示:
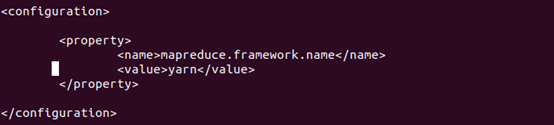
在每个节点上都进行这步操作。
3.4启动
3.4.1 格式化hdfs
在hadoop的安装目录,运行bin/hdfs namenode -format,格式化hdfs,结果如下图:
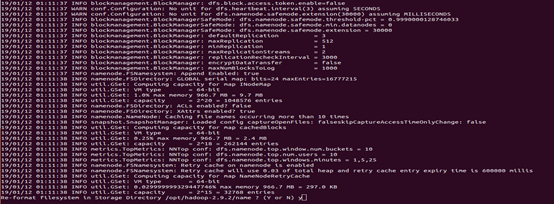

3.4.2 启动hdfs
在hadoop的安装目录下,运行sbin/start-hdfs.sh,启动hdfs。

3.4.3 启动yarn
在hadoop的安装目录下,运行sbin/start-yarn.sh,启动yarn。

3.4.4 启动JobHistory Server
在hadoop的安装目录下。运行sbin/mr-jobhistory-daemon.sh start,启动job history server。

3.5验证
3.5.1 验证hdfs

3.5.2 验证yarn

3.5.3 验证job history server