文章目录
书的目录与索引



书与搜索引擎是相似的。
·目录页对应正排索引
·索引页对应倒排索引
搜索引擎
·正排索引
-文档Id到文档内容、单词的关联关系
·倒排索引
-单词到文档Id的关联关系
正排与倒排索引简介
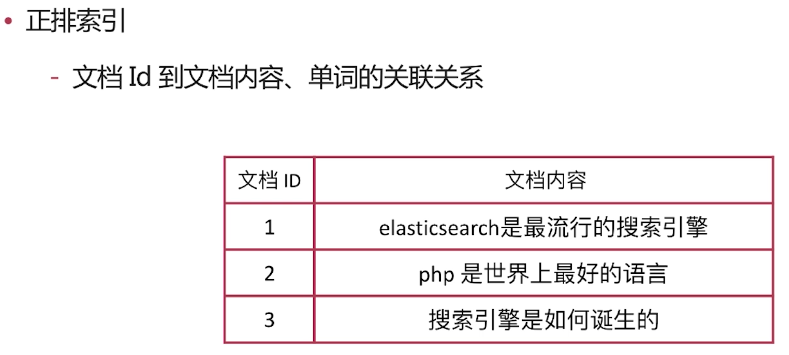
正排索引
-文档Id到文档内容、单词的关联关系
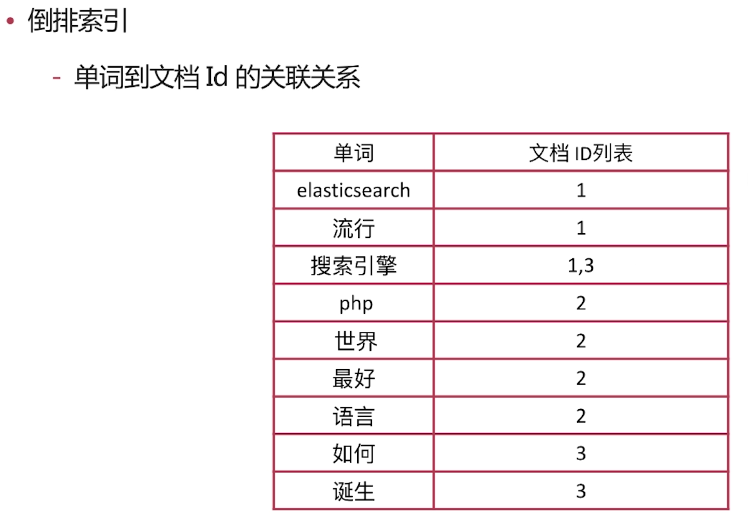
·倒排索引
-单词到文档Id的关联关系
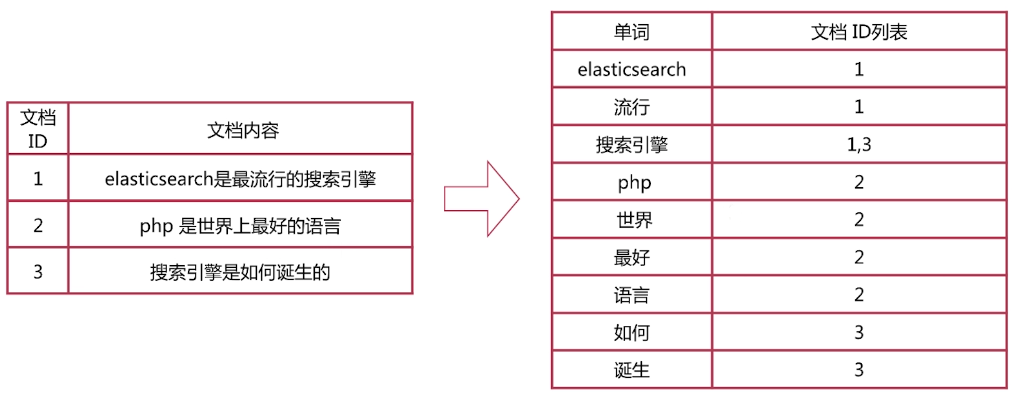
倒排索引-查询流程
·查询包含"搜索引擎"的文档
-通过倒排索引获得"搜索引擎"对应的文档Id有1和3
-通过正排索引查询1和3的完整内容
-返回用户最终结果
倒排索引详解
倒排索引组成:
倒排索引是搜索引擎的核心,主要包含两部分:
-单词词典( Term Dictionary)
-倒排列表( Posting List )
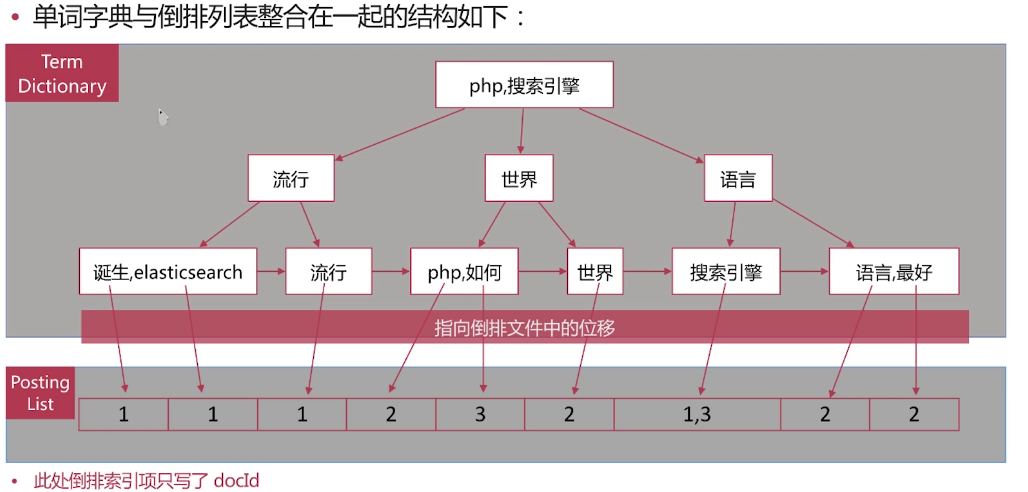
倒排索引一单词词典
·单词词典( Term Dictionary )是倒排索引的重要组成
-记录所有文档的单词,一般都比较大
-记录单词到倒排列表的关联信息
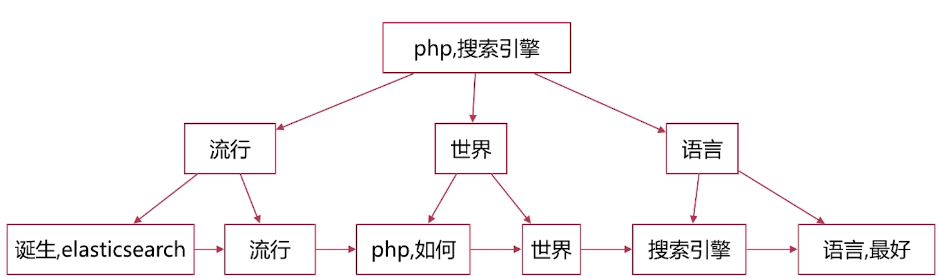
·单词字典的实现一般是用B+ Tree ,示例如下图:
-下图排序采用拼音实现,构造方法参见如下网址
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
倒排索引-倒排列表
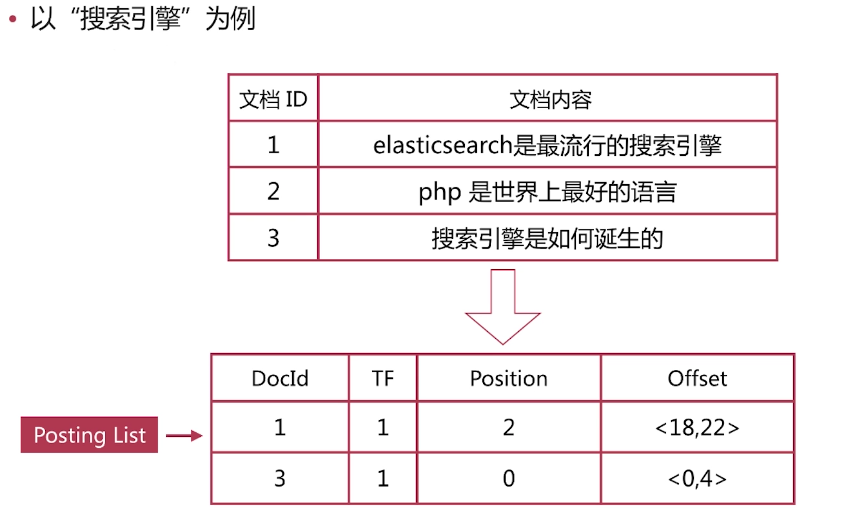
·倒排列表( Posting List )记录了单词对应的文档集合,由倒排索引项( Posting )组成
·倒排索引项( Posting )主要包含如下信息:
-文档Id ,用于获取原始信息
-单词频率( TF, Term Frequency ) ,记录该单词在该文档中的出现次数,用于后续相关性算分
-位置( Position ) ,记录单词在文档中的分词位置(多个) ,用于做词语搜索(Phrase Query)
-偏移( Offset ) ,记录单词在文档的开始和结束位置,用于做高亮显示·
以“搜索引擎”为例
. es存储的是一个json格式的文档,其中包含多个字段,每个字段会有自己的倒排索引
类似下图:

分词介绍
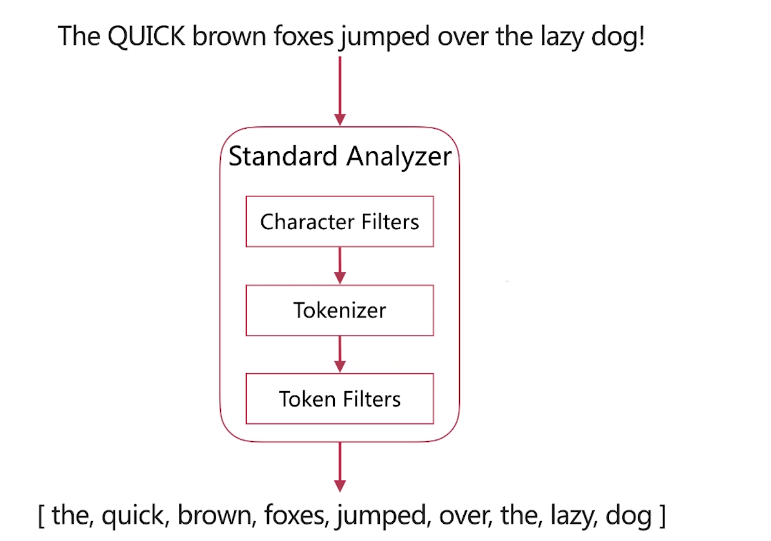
·分词是指将文本转换成一系列单词( term or token )的过程,也可以叫做文本分析,在es里面称为Analysis ,如下图所示:

·分词器是es中专门处理分词的组件,英文为Analyzer ,它的组成如下
- Character Filters
-针对原始文本进行处理,比如去除html特殊标记符
- Tokenizer
-将原始文本按照一定规则切分为单词
- Token Filters
-针对tokenizer处理的单词就行再加工,比如转小写、删除或新增等处理
analyze_api
. es提供了一个测试分词的api接口,方便验证分词效果, endpoint是_analyze
-可以直接指定analyzer进行测试
-可以直接指定索引中的字段进行测试
-可以自定义分词器进行测试
·直接指定analyzer进行测试,接口如下:
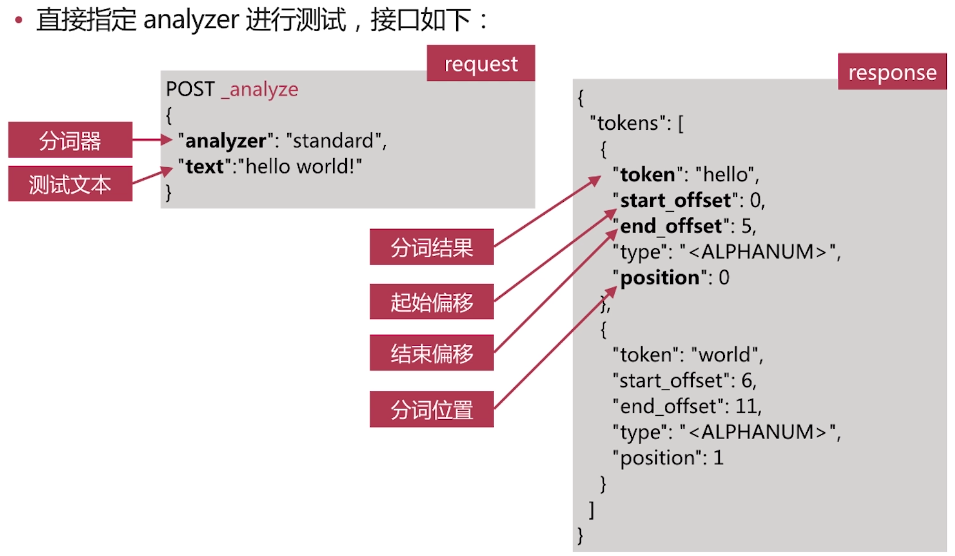
当没有定义analyzer的时候会使用默认分词器”analyzer”:”standard”

自定义分词器:tokenizer指名要用哪个分词器,filter指明的是token filter:

自带分词器
.es自带如下的分词器
-Standard Simple
-Whitespace
-Stop
-Keyword
-Pattern
-Language
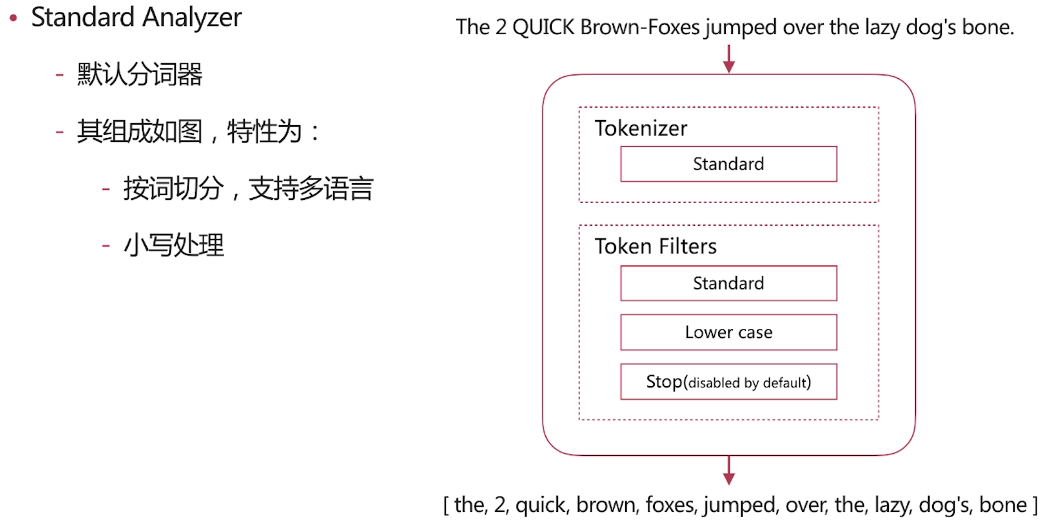
Standard Analyzer
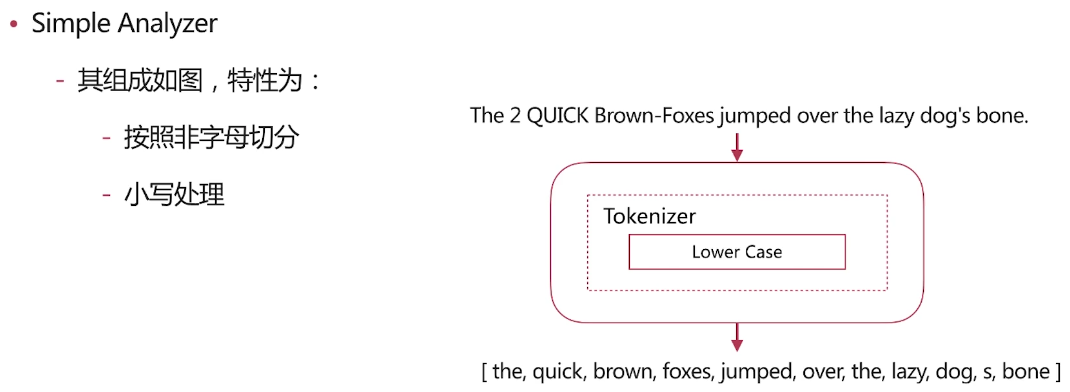
Simple Analyzer
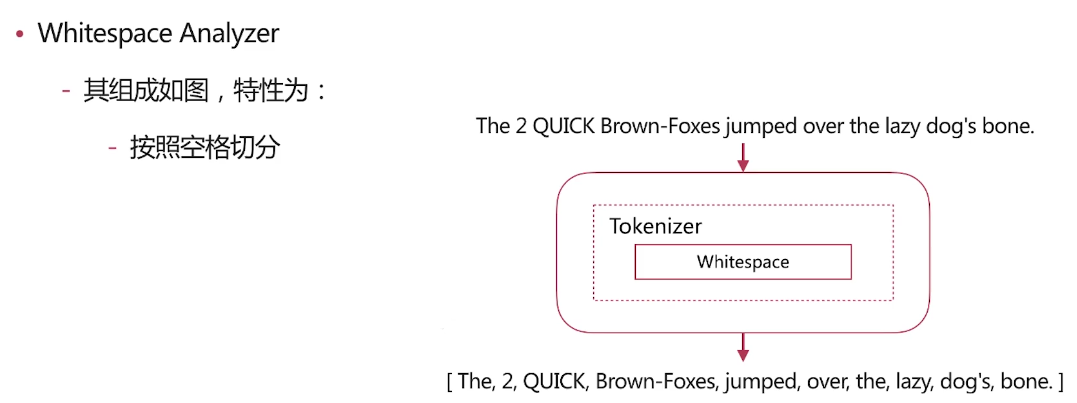
Whitespace Analyzer
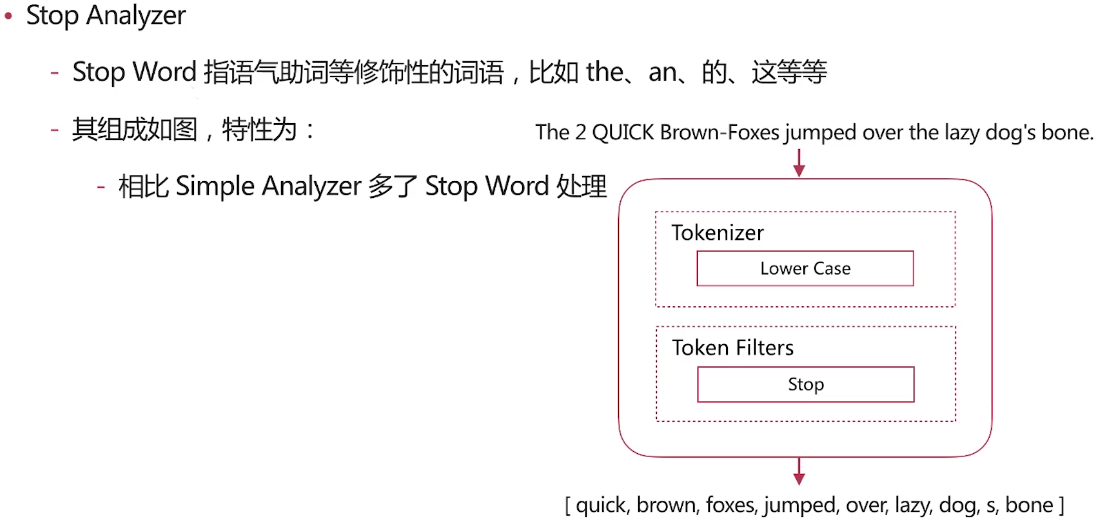
Stop Analyzer
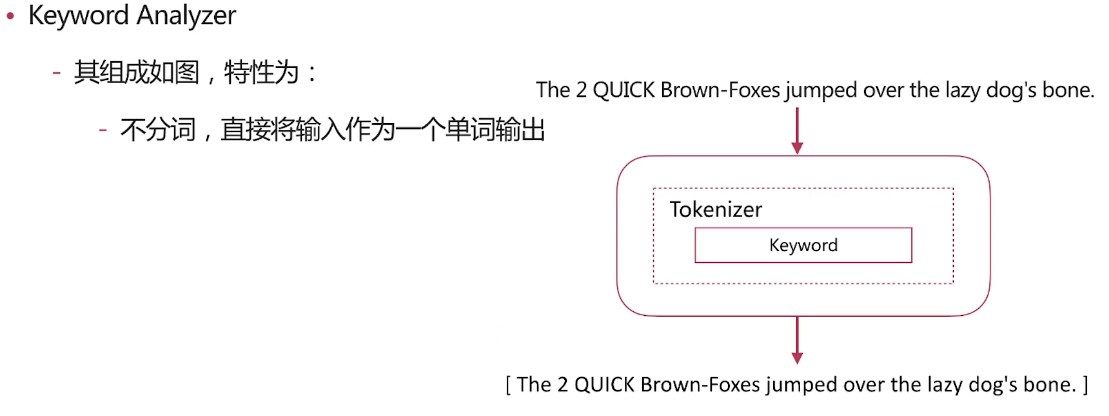
Keyword Analyzer
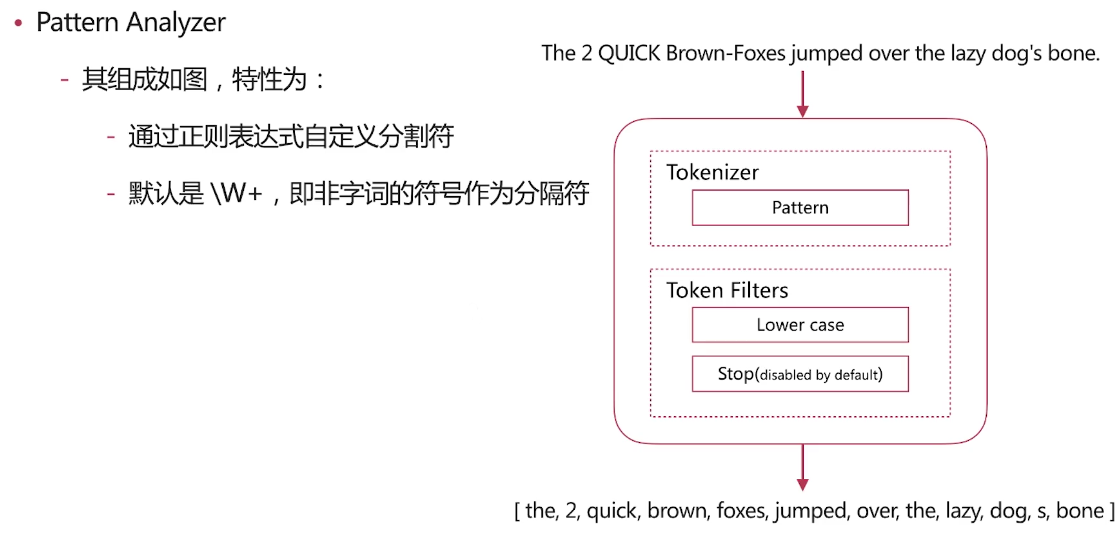
Pattern Analyzer
Language Analyzer

中文分词
·难点
-中文分词指的是将一个汉字序列切分成一个一个单独的词。在英文中,单词之间是以空格作为自然分界符,汉语中词没有一个形式上的分界符。
-上下文不同,分词结果迥异,比如交叉歧义问题,比如下面两种分词都合理
-乒乓球拍/卖完了
-乒乓球/拍卖/完了
- https://mp.weixin.qq.com/s/SiHSMrn8lxCmrtHbcwL-NQ
·常用分词系统
-IK
-实现中英文单词的切分,支持ik smart, ik maxword等模式
-可自定义词库,支持热更新分词词典,
- https://github.com/medcl/elasticsearch-analysis-ik
- jieba
-python中最流行的分词系统,支持分词和词性标注
-支持繁体分词、自定义词典、并行分词等
- https://github.com/sing1ee/elasticsearch-jieba-plugin
·基于自然语言处理的分词系统
- Hanlp
-由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用
- https://github.com/hankcs/HanLP
-THULAC
-THU Lexical Analyzer for Chinese ,由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能
- https://github.com/microbun/elasticsearch-thulac-plugin
自定义分词
CharacterFilter
·当自带的分词无法满足需求时,可以自定义分词
-通过自定义Character Filters, Tokenizer和Token Filter实现. Character Filters
-在Tokenizer之前对原始文本进行处理,比如增加、删除或替换字符等
-自带的如下:
-HTML Strip去除html标签和转换html实体
-Mapping进行字符替换操作
-Pattern Replace进行正则匹配替换
-会影响后续tokenizer解析的postion和offset信息
. Character Filters测试时可以采用如下api :

Tokenizer
Tokenizer
-将原始文本按照一定规则切分为单词( term or token )
-自带的如下:
-standard按照单词进行分割
-letter按照非字符类进行分割
-whitespace按照空格进行分割
-UAX URL Email按照standard分割,但不会分割邮箱和url
-NGram和Edge NGram连词分割
-Path Hierarchy按照文件路径进行切割
Tokenizer测试时可以采用如下api:

TokenFilter
. Token Filters
-对于tokenizer输出的单词( term )进行增加、删除、修改等操作
-自带的如下:
-lowercase将所有term转换为小写
-stop删除stop words
-NGram和Edge NGram连词分割
-Synonym添加近义词的term
Filter测试时可以采用如下api:

自定义分词
.自定义分词的api
-自定义分词需要在索引的配置中设定,如下所示:

自定义如下图所示的分词器:
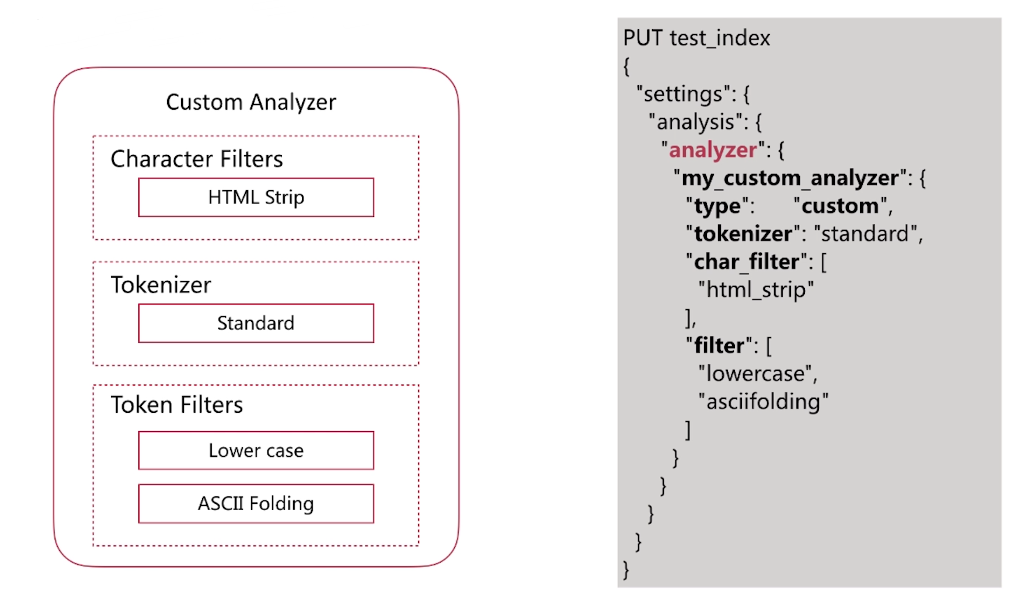
自定义分词验证:

自定义如下图所示的分词器二:
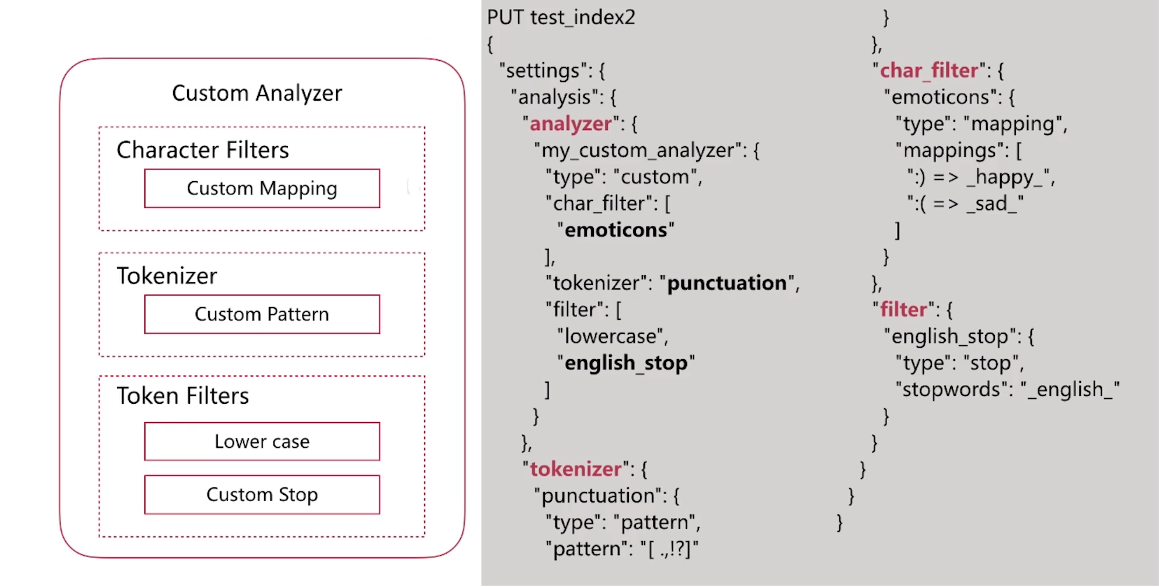
自定义分词验证:

分词使用说明
·分词会在如下两个时机使用:
-创建或更新文档时(Index Time ) ,会对相应的文档进行分词处理
-查询时( Search Time ) ,会对查询语句进行分词
索引时分词
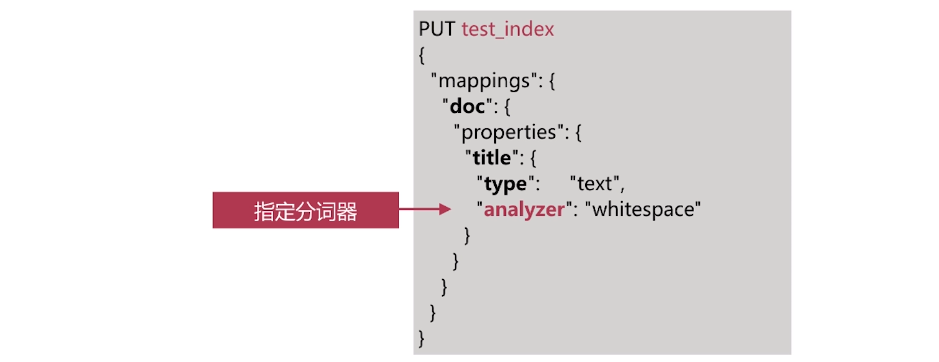
·索引时分词是通过配置Index Mapping中每个字段的analyzer属性实现的如下:
不指定分词时,使用默认standard
查询时分词
·查询时分词的指定方式有如下几种:
-查询的时候通过analyzer指定分词器
-通过index mapping设置search_analyzer实现

.一般不需要特别指定查询时分词器,直接使用索引时分词器即可,否则会出现无法匹配的情况
分词建议
·明确字段是否需要分词,不需要分词的字段就将type设置为keyword ,可以节省空间和提高写性能
·善用_analyze API ,查看文档的具体分词结果
·动手测试,
官方文档分词链接
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis.html