倒排索引
倒排索引参考 Elasticsearch官方文档
Elasticsearch 使用一种倒排索引的结构,适用于快速的全文搜索。一个倒排索引会包含文档中所有不重复词项组成的列表以及列出每个词项出现在哪个文档中。
例如,假设我们有两个文档,每个文档的 content 域包含如下内容:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
为了创建倒排索引,首先将每个文档的 content 域拆分成单独的词项,创建一个包含所有不重复词项组成的排序列表,然后列出每个词项出现在哪个文档中。
结果如下:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
------------------------
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1
从结果中可以看出两个文档都匹配,如果采取只计算匹配词项数量的简单相似性算法,则第一个文档比第二个文档匹配度更高。
列式存储
列式存储参考 Elasticsearch官方文档
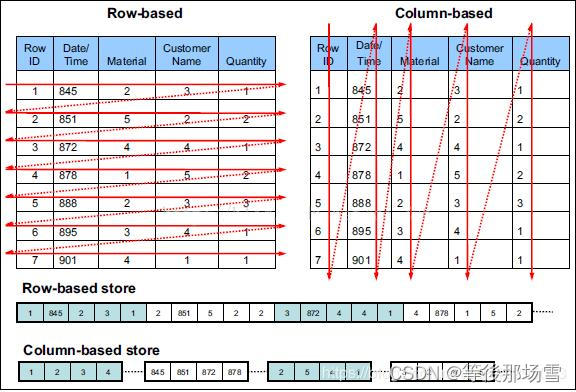
在 Elasticsearch 中,Doc Values 就是一种列式存储结构,默认情况下每个字段的 Doc Values 都是激活的,Doc Values 是在索引时创建的,当字段索引时,Elasticsearch 为了能够快速检索,会把字段的值加入倒排索引中,同时它也会存储该字段的 Doc Values。
Elasticsearch 中的 Doc Values 常被应用到以下场景:
- 对一个字段进行排序
- 对一个字段进行聚合
- 某些过滤,比如地理位置过滤
- 某些与字段相关的脚本计算
Elasticsearch 的列式存储中按照文档写入的顺序(没有按照 doc_id 的顺序)进行存储。