文章目录
倒排索引
首先倒排索引的概念是这样的:
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
如果你是第一个见到这个词,那么理解起来肯定会很懵,下面我们一起来探究一下倒排索引到底是怎么回事:
当然首先:倒排索引的概念是基于MySQL这样的正向索引而言的
那什么是正向索引呢?
1.正向索引
那么什么是正向索引呢?
例如给下表(tb_goods)中的id创建索引:
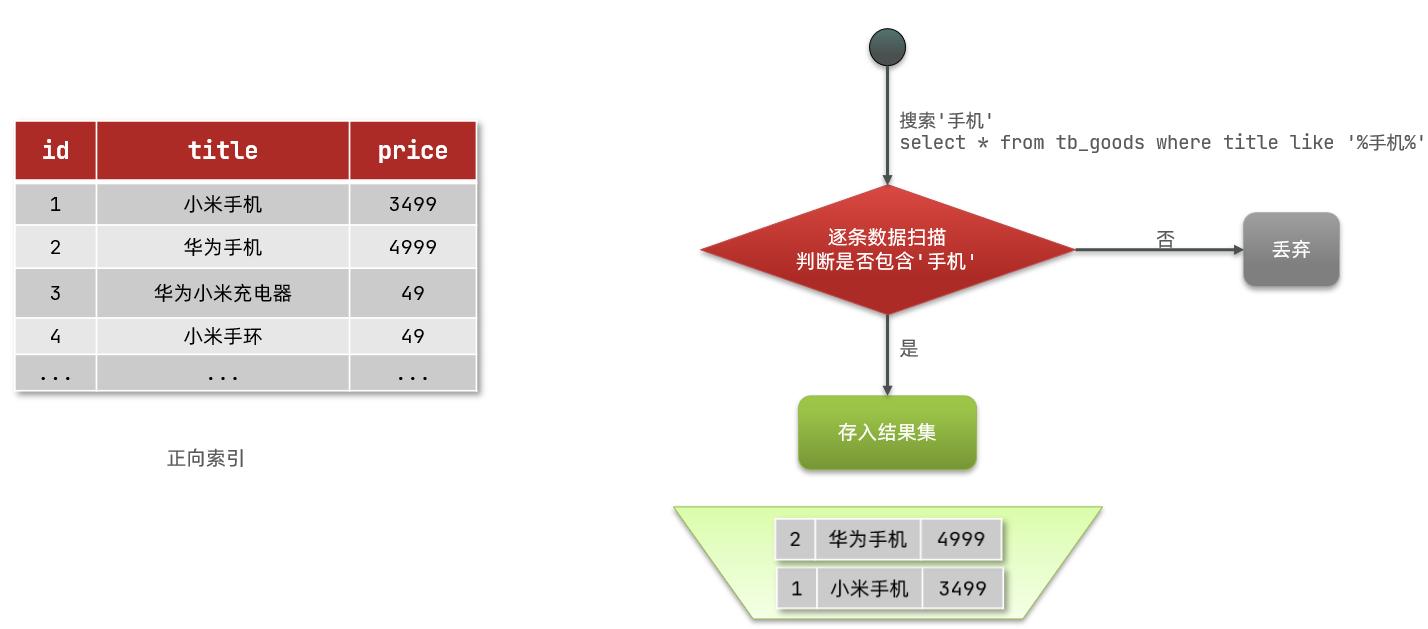
如果是根据id查询,那么直接走索引,查询速度非常快。
- 比如说我要查id为1的数据信息,那么歘chua的一下子就查出来了
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。

针对上面的问题,此时就出现了我们的倒排索引的查找方法
2.倒排索引
首先倒排索引中有两个非常重要的概念,文档与词条:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
将上面案例按照倒排索引的流程创建索引, 如图:

按照上面流程具体分解下每个步骤:
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:
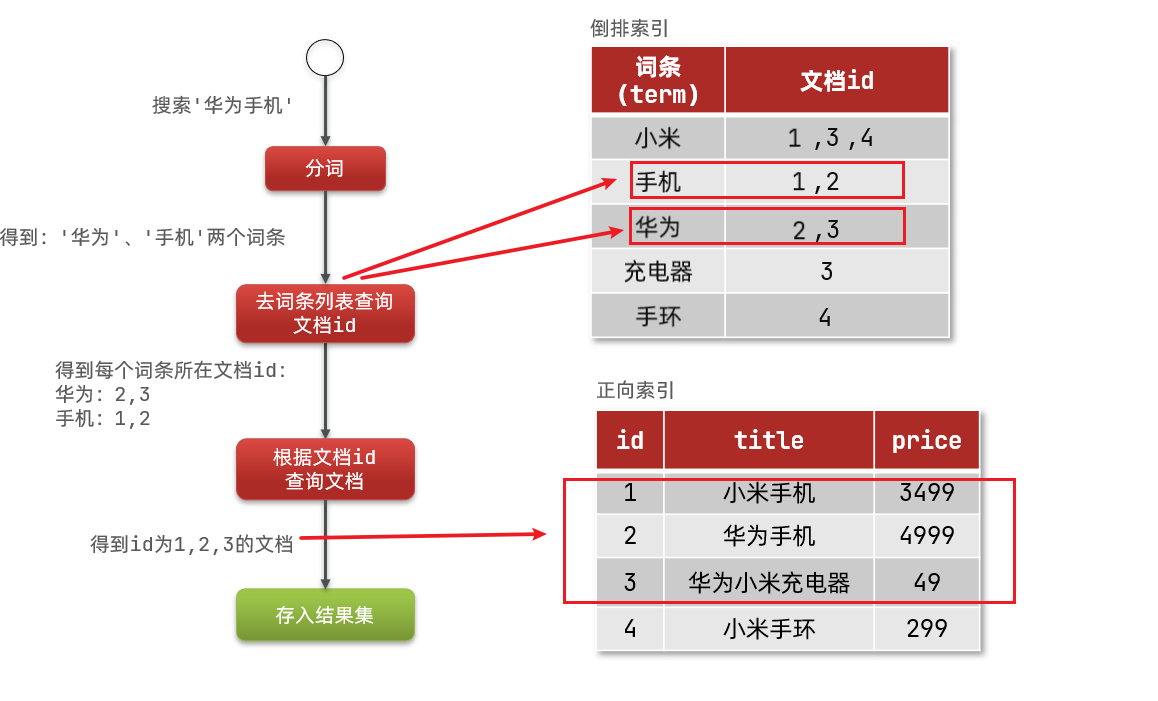
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
3.正向和倒排区分
那么为什么一个叫做正向索引,一个叫做倒排索引呢?怎么区分呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保存词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
从查询上流程来看这两个不是恰好反过来的,所以一个叫正向一个叫倒排;从查询查询的内容来看如果是去先查询词条,那么就是倒排索引,如果先查询所有文档,那么就是正向索引
4.正向和倒排优缺点:
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序