前言
前面《EM概率统计基础(一)》简单讲解了后验概率和先验概率之间的关系,得到如下结果:
先验概率乘以似然函数,正比于后验概率
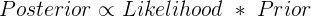
那么 似然函数是什么,它和概率又有什么关系,希望可以总结总结。
似然函数
Likelihood Function
似然函数也称为似然,是一个关于统计模型参数的函数,也就是这个函数中自变量统计模型的参数。似然函数是关于统计参数的函数,可以用来评估一组统计的参数。
似然函数的定义,它是给定联合样本值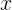
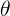
取到的值,即
;
是一个密度函数,它表示(给定)
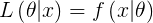
所以从定义上可以看出似然函数和密度函数完全两个数学对象:前者是关于
似然和概率的区别
首先给出一个简便的区分方法,根据定义:
“xxxx的概率”中xxxx只能是概率空间中的事件,即事件(发生)的概率是多少,因为时间具有概率结构从而刻画随机性,所以才能谈概率
“xxxx的似然”中xxxx只能是参数,比如说上文所述的参数等于
举个栗子:
已知一个硬币是均匀的(在抛的过程中,正反面的概率相等),那连续10次正面朝上的概率是多少,这是一个概率问题。
如果一个硬币在10次抛落中均正面朝上,那硬币的是均匀的(在抛落中,正反面的概率相等)概率是多少,此时的概率是似然。
Probability is used before data are available to describe possible future outcomes given a fixed value for the parameter (or parameter vector).
Likelihood is used after data are available to describe a function of a parameter (or parameter vector) for a given outcome.
The likelihood of a set of parameter values, θ, given outcomes x, is equal to the probability of those observed outcomes given those parameter values, that is
有趣的栗子
这个栗子摘自Quora上一个计算机系教授的回答,很有意思。
其将概率密度函数和似然函数之间类比成 与
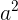
假设一个函数为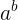
如果设置b = 2,那么可以得到一个关于a的二次函数,即
如果设置为a = 2 ,那么将得到一个指数函数,即
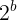

可以看出,这两个函数虽然有着不同的名字,但源自于同一个函数
同样的,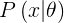
以下举一个栗子(没错,我超喜欢吃栗子的)
有一个硬币,它有 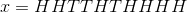
通过概率论基础我们可以得出,出现此序列的概率为:
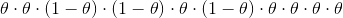
我们尝试了所有

这个曲线就是
如图所示,最可能的假设是,但实际上这个实验量太小,无法税负你这个硬币是均质的,但0.7就是最大似然估计,只是因为样本太少而导致最大似然值偏差过大,如果扩充样本空间,H和T的样本数量将趋近于1:1,那最终求得的最大似然估计将接近0.5.
总结
常说的概率指的是给定参数后,预测即将发生的事件的可能性,而似然概率则正好相反,我们关注的量不再是时间的发生概率,而是已知发生了某些事件,我们希望知道参数应该是多少。最大似然概率就是在已知观测数据的前提下,找到使得似然概率最大的参数值。
此篇只是简单介绍了下似然函数和概率之间的区别,下篇希望总结一下极大似然估计(MLE)和极大后验估计(MAP),如果有什么错误,欢迎大佬们批评指正。