系列前言
参考文献:
- RNNLM - Recurrent Neural Network Language Modeling Toolkit(点此阅读)
- Recurrent neural network based language model(点此阅读)
- EXTENSIONS OF RECURRENT NEURAL NETWORK LANGUAGE MODEL(点此阅读)
- Strategies for Training Large Scale Neural Network Language Models(点此阅读)
- STATISTICAL LANGUAGE MODELS BASED ON NEURAL NETWORKS(点此阅读)
- A guide to recurrent neural networks and backpropagation(点此阅读)
- A Neural Probabilistic Language Model(点此阅读)
- Learning Long-Term Dependencies with Gradient Descent is Difficult(点此阅读)
- Can Artificial Neural Networks Learn Language Models?(点此阅读)
这篇内容的函数比较好理解,很多地方含义都差不多,某处的注释适用于其他地方,就无需赘述了,直接上代码。
//保存网络的所有信息到rnnlm_file
void CRnnLM::saveNet() //will save the whole network structure
{
FILE *fo;
int a, b;
char str[1000];
float fl;
//这里把rnnlm_file的文件名加上.temp送入到str
sprintf(str, "%s.temp", rnnlm_file);
//以二进制方式创建文件
fo=fopen(str, "wb");
if (fo==NULL) {
printf("Cannot create file %s\n", rnnlm_file);
exit(1);
}
fprintf(fo, "version: %d\n", version); //初始化时version=10
fprintf(fo, "file format: %d\n\n", filetype); //初始化时filetype=TEXT
fprintf(fo, "training data file: %s\n", train_file);
fprintf(fo, "validation data file: %s\n\n", valid_file);
fprintf(fo, "last probability of validation data: %f\n", llogp);//TBD
fprintf(fo, "number of finished iterations: %d\n", iter);
fprintf(fo, "current position in training data: %d\n", train_cur_pos);
fprintf(fo, "current probability of training data: %f\n", logp);
fprintf(fo, "save after processing # words: %d\n", anti_k);
fprintf(fo, "# of training words: %d\n", train_words);
fprintf(fo, "input layer size: %d\n", layer0_size);
fprintf(fo, "hidden layer size: %d\n", layer1_size);
fprintf(fo, "compression layer size: %d\n", layerc_size);
fprintf(fo, "output layer size: %d\n", layer2_size);
fprintf(fo, "direct connections: %lld\n", direct_size);
fprintf(fo, "direct order: %d\n", direct_order);
fprintf(fo, "bptt: %d\n", bptt);
fprintf(fo, "bptt block: %d\n", bptt_block);
fprintf(fo, "vocabulary size: %d\n", vocab_size);
fprintf(fo, "class size: %d\n", class_size);
fprintf(fo, "old classes: %d\n", old_classes);
fprintf(fo, "independent sentences mode: %d\n", independent);
fprintf(fo, "starting learning rate: %f\n", starting_alpha);
fprintf(fo, "current learning rate: %f\n", alpha);
fprintf(fo, "learning rate decrease: %d\n", alpha_divide);
fprintf(fo, "\n");
fprintf(fo, "\nVocabulary:\n");
for (a=0; a<vocab_size; a++) fprintf(fo, "%6d\t%10d\t%s\t%d\n", a, vocab[a].cn, vocab[a].word, vocab[a].class_index);
//以文本方式存入,即以ascii来存,能够方便阅读,不会乱码
if (filetype==TEXT) {
fprintf(fo, "\nHidden layer activation:\n");
for (a=0; a<layer1_size; a++) fprintf(fo, "%.4f\n", neu1[a].ac);
}
if (filetype==BINARY) {
for (a=0; a<layer1_size; a++) {
fl=neu1[a].ac;
//fwrite()是以二进制方式输出到文件
//第一个参数表示获取数据的地址
//第二个参数表示要写入内容的单字节数
//第三个参数表示要进行写入size字节的数据项的个数
fwrite(&fl, sizeof(fl), 1, fo);
}
}
//////////
if (filetype==TEXT) {
fprintf(fo, "\nWeights 0->1:\n");
for (b=0; b<layer1_size; b++) {
for (a=0; a<layer0_size; a++) {
fprintf(fo, "%.4f\n", syn0[a+b*layer0_size].weight);
}
}
}
if (filetype==BINARY) {
for (b=0; b<layer1_size; b++) {
for (a=0; a<layer0_size; a++) {
fl=syn0[a+b*layer0_size].weight;
fwrite(&fl, sizeof(fl), 1, fo);
}
}
}
/////////
if (filetype==TEXT) {
if (layerc_size>0) {
fprintf(fo, "\n\nWeights 1->c:\n");
for (b=0; b<layerc_size; b++) {
for (a=0; a<layer1_size; a++) {
fprintf(fo, "%.4f\n", syn1[a+b*layer1_size].weight);
}
}
fprintf(fo, "\n\nWeights c->2:\n");
for (b=0; b<layer2_size; b++) {
for (a=0; a<layerc_size; a++) {
fprintf(fo, "%.4f\n", sync[a+b*layerc_size].weight);
}
}
}
else
{
fprintf(fo, "\n\nWeights 1->2:\n");
for (b=0; b<layer2_size; b++) {
for (a=0; a<layer1_size; a++) {
fprintf(fo, "%.4f\n", syn1[a+b*layer1_size].weight);
}
}
}
}
if (filetype==BINARY) {
if (layerc_size>0) {
for (b=0; b<layerc_size; b++) {
for (a=0; a<layer1_size; a++) {
fl=syn1[a+b*layer1_size].weight;
fwrite(&fl, sizeof(fl), 1, fo);
}
}
for (b=0; b<layer2_size; b++) {
for (a=0; a<layerc_size; a++) {
fl=sync[a+b*layerc_size].weight;
fwrite(&fl, sizeof(fl), 1, fo);
}
}
}
else
{
for (b=0; b<layer2_size; b++) {
for (a=0; a<layer1_size; a++) {
fl=syn1[a+b*layer1_size].weight;
fwrite(&fl, sizeof(fl), 1, fo);
}
}
}
}
////////
if (filetype==TEXT) {
fprintf(fo, "\nDirect connections:\n");
long long aa;
for (aa=0; aa<direct_size; aa++) {
fprintf(fo, "%.2f\n", syn_d[aa]);
}
}
if (filetype==BINARY) {
long long aa;
for (aa=0; aa<direct_size; aa++) {
fl=syn_d[aa];
fwrite(&fl, sizeof(fl), 1, fo);
//这里被注释掉的代码,没看懂
//不知道为啥可以省50%的空间
//希望明白的朋友告知一下哈
/*fl=syn_d[aa]*4*256; //saving direct connections this way will save 50% disk space; several times more compression is doable by clustering
if (fl>(1<<15)-1) fl=(1<<15)-1;
if (fl<-(1<<15)) fl=-(1<<15);
si=(signed short int)fl;
fwrite(&si, 2, 1, fo);*/
}
}
////////
fclose(fo);
//最后将名字更改为指定的rnnlm_file,那为啥最开始要改呢?
//这里不太明白,希望明白的朋友告知一下哈
rename(str, rnnlm_file);
}
//从文件流中读取一个字符使其ascii等于delim
//随后文件指针指向delim的下一个
void CRnnLM::goToDelimiter(int delim, FILE *fi)
{
int ch=0;
while (ch!=delim) {
ch=fgetc(fi);
if (feof(fi)) {
printf("Unexpected end of file\n");
exit(1);
}
}
}
//从rnnlm_file中读取网络的所有信息
void CRnnLM::restoreNet() //will read whole network structure
{
FILE *fi;
int a, b, ver;
float fl;
char str[MAX_STRING];
double d;
fi=fopen(rnnlm_file, "rb");
if (fi==NULL) {
printf("ERROR: model file '%s' not found!\n", rnnlm_file);
exit(1);
}
//注意前面一些基本的信息,如version,filetype等都是以ascii输入的
//前面均是用:做标记
//ver表示该模型被哪个rnnlm版本的程序所训练得到的
//version表示现在rnnlm的版本号
//下面几个跟ver有关的条件判断,应该是解决兼容问题,因为新的版本加了新的功能
goToDelimiter(':', fi);
fscanf(fi, "%d", &ver);
if ((ver==4) && (version==5)) /* we will solve this later.. */ ; else
if (ver!=version) {
printf("Unknown version of file %s\n", rnnlm_file);
exit(1);
}
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &filetype);
//
goToDelimiter(':', fi);
if (train_file_set==0) {
fscanf(fi, "%s", train_file);
} else fscanf(fi, "%s", str);
//
goToDelimiter(':', fi);
fscanf(fi, "%s", valid_file);
//
goToDelimiter(':', fi);
fscanf(fi, "%lf", &llogp);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &iter);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &train_cur_pos);
//
goToDelimiter(':', fi);
fscanf(fi, "%lf", &logp);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &anti_k);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &train_words);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &layer0_size);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &layer1_size);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &layerc_size);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &layer2_size);
//
if (ver>5) {
goToDelimiter(':', fi);
fscanf(fi, "%lld", &direct_size);
}
//
if (ver>6) {
goToDelimiter(':', fi);
fscanf(fi, "%d", &direct_order);
}
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &bptt);
//
if (ver>4) {
goToDelimiter(':', fi);
fscanf(fi, "%d", &bptt_block);
} else bptt_block=10;
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &vocab_size);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &class_size);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &old_classes);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &independent);
//
goToDelimiter(':', fi);
fscanf(fi, "%lf", &d);
starting_alpha=d;
//
goToDelimiter(':', fi);
if (alpha_set==0) {
fscanf(fi, "%lf", &d);
alpha=d;
} else fscanf(fi, "%lf", &d);
//
goToDelimiter(':', fi);
fscanf(fi, "%d", &alpha_divide);
//
//下面是把vocab从train_file中恢复过来
if (vocab_max_size<vocab_size) {
if (vocab!=NULL) free(vocab);
vocab_max_size=vocab_size+1000;
vocab=(struct vocab_word *)calloc(vocab_max_size, sizeof(struct vocab_word)); //initialize memory for vocabulary
}
//
goToDelimiter(':', fi);
for (a=0; a<vocab_size; a++) {
//fscanf(fi, "%d%d%s%d", &b, &vocab[a].cn, vocab[a].word, &vocab[a].class_index);
fscanf(fi, "%d%d", &b, &vocab[a].cn);
readWord(vocab[a].word, fi);
fscanf(fi, "%d", &vocab[a].class_index);
//printf("%d %d %s %d\n", b, vocab[a].cn, vocab[a].word, vocab[a].class_index);
}
//
if (neu0==NULL) initNet(); //memory allocation here
//
//由于对网络的权值分为两种模式,所以这里也应该分情况读入
//对于大量的实数,二进制模式肯定更省空间
if (filetype==TEXT) {
goToDelimiter(':', fi);
for (a=0; a<layer1_size; a++) {
fscanf(fi, "%lf", &d);
neu1[a].ac=d;
}
}
if (filetype==BINARY) {
fgetc(fi);
for (a=0; a<layer1_size; a++) {
fread(&fl, sizeof(fl), 1, fi);
neu1[a].ac=fl;
}
}
//
if (filetype==TEXT) {
goToDelimiter(':', fi);
for (b=0; b<layer1_size; b++) {
for (a=0; a<layer0_size; a++) {
fscanf(fi, "%lf", &d);
syn0[a+b*layer0_size].weight=d;
}
}
}
if (filetype==BINARY) {
for (b=0; b<layer1_size; b++) {
for (a=0; a<layer0_size; a++) {
fread(&fl, sizeof(fl), 1, fi);
syn0[a+b*layer0_size].weight=fl;
}
}
}
//
if (filetype==TEXT) {
goToDelimiter(':', fi);
if (layerc_size==0) { //no compress layer
for (b=0; b<layer2_size; b++) {
for (a=0; a<layer1_size; a++) {
fscanf(fi, "%lf", &d);
syn1[a+b*layer1_size].weight=d;
}
}
}
else
{ //with compress layer
for (b=0; b<layerc_size; b++) {
for (a=0; a<layer1_size; a++) {
fscanf(fi, "%lf", &d);
syn1[a+b*layer1_size].weight=d;
}
}
goToDelimiter(':', fi);
for (b=0; b<layer2_size; b++) {
for (a=0; a<layerc_size; a++) {
fscanf(fi, "%lf", &d);
sync[a+b*layerc_size].weight=d;
}
}
}
}
if (filetype==BINARY) {
if (layerc_size==0) { //no compress layer
for (b=0; b<layer2_size; b++) {
for (a=0; a<layer1_size; a++) {
fread(&fl, sizeof(fl), 1, fi);
syn1[a+b*layer1_size].weight=fl;
}
}
}
else
{ //with compress layer
for (b=0; b<layerc_size; b++) {
for (a=0; a<layer1_size; a++) {
fread(&fl, sizeof(fl), 1, fi);
syn1[a+b*layer1_size].weight=fl;
}
}
for (b=0; b<layer2_size; b++) {
for (a=0; a<layerc_size; a++) {
fread(&fl, sizeof(fl), 1, fi);
sync[a+b*layerc_size].weight=fl;
}
}
}
}
//
if (filetype==TEXT) {
goToDelimiter(':', fi); //direct conenctions
long long aa;
for (aa=0; aa<direct_size; aa++) {
fscanf(fi, "%lf", &d);
syn_d[aa]=d;
}
}
//
if (filetype==BINARY) {
long long aa;
for (aa=0; aa<direct_size; aa++) {
fread(&fl, sizeof(fl), 1, fi);
syn_d[aa]=fl;
/*fread(&si, 2, 1, fi);
fl=si/(float)(4*256);
syn_d[aa]=fl;*/
}
}
//
saveWeights();
fclose(fi);
}
//清除神经元的ac,er值
void CRnnLM::netFlush() //cleans all activations and error vectors
{
int a;
for (a=0; a<layer0_size-layer1_size; a++) {
neu0[a].ac=0;
neu0[a].er=0;
}
for (a=layer0_size-layer1_size; a<layer0_size; a++) { //last hidden layer is initialized to vector of 0.1 values to prevent unstability
neu0[a].ac=0.1;
neu0[a].er=0;
}
for (a=0; a<layer1_size; a++) {
neu1[a].ac=0;
neu1[a].er=0;
}
for (a=0; a<layerc_size; a++) {
neuc[a].ac=0;
neuc[a].er=0;
}
for (a=0; a<layer2_size; a++) {
neu2[a].ac=0;
neu2[a].er=0;
}
}
下面这个函数将隐层神经元(论文中的状态层s(t))的ac值置1,s(t-1),即输入层layer1_size那部分的ac值置1,bptt+history清0,相关变量的含义在下面的图中:
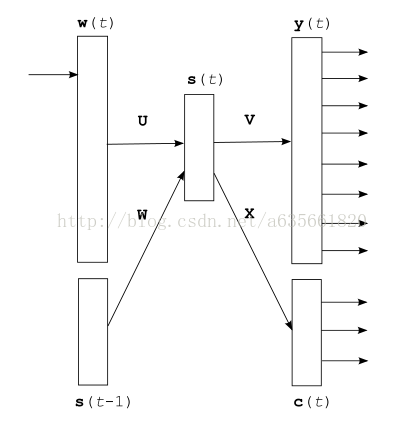
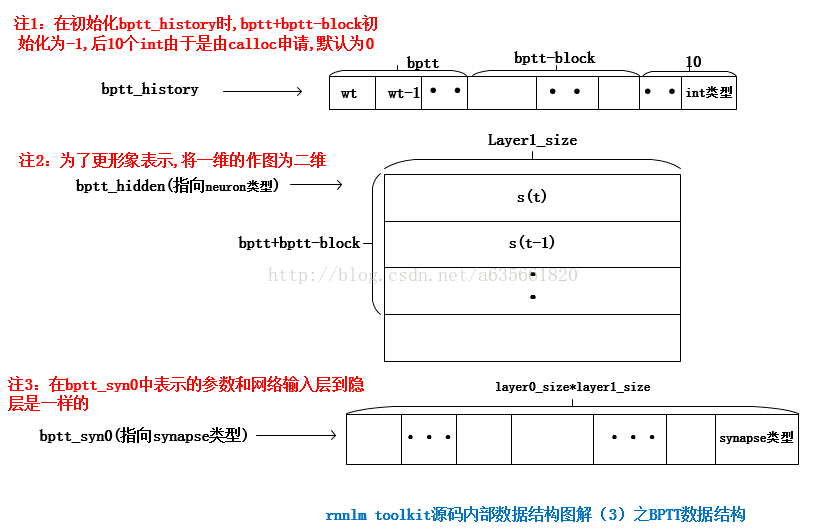
void CRnnLM::netReset() //cleans hidden layer activation + bptt history
{
int a, b;
//将隐层神经元ac值置1
for (a=0; a<layer1_size; a++) {
neu1[a].ac=1.0;
}
//这个函数将隐层的神经元的ac值复制到输入层layer1_size部分
//也就是输入层的layer1_size那部分的ac值置1
copyHiddenLayerToInput();
if (bptt>0) {
//这里见图,容易理解,下标为0没被清除,下标为0没被清除是因为后面学习算法中会使用这个空位
//这个在后面会看到
for (a=1; a<bptt+bptt_block; a++) bptt_history[a]=0;
for (a=bptt+bptt_block-1; a>1; a--) for (b=0; b<layer1_size; b++) {
bptt_hidden[a*layer1_size+b].ac=0;
bptt_hidden[a*layer1_size+b].er=0;
}
}
//todo
for (a=0; a<MAX_NGRAM_ORDER; a++) history[a]=0;
}
下面这个函数用于权值矩阵乘以神经元向量,并将计算结果存入目的神经元向量,type == 0时,计算的是神经元ac值,相当于计算srcmatrix × srcvec, 其中srcmatrix是(to-from)×(to2-from2)的矩阵,srcvec是(to2-from2)×1的列向量,得到的结果是(to-from)×1的列向量,该列向量的值存入dest中的ac值;type == 1, 计算神经元的er值,即(srcmatrix)^T × srcvec,T表示转置,转置后是(to2-from2)×(to-from),srcvec是(to-from)×1的列向量。这里的矩阵相乘比下面被注释掉的的快,好像是叫做Strassen’s method,记不太清楚了,很久之前看算法导论时学的,感兴趣的可以看看算法导论英文版第三版的79页,如果这不是Strassen’s method麻烦懂的朋友纠正一下~
void CRnnLM::matrixXvector(struct neuron *dest, struct neuron *srcvec, struct synapse *srcmatrix, int matrix_width, int from, int to, int from2, int to2, int type)
{
int a, b;
real val1, val2, val3, val4;
real val5, val6, val7, val8;
if (type==0) { //ac mod
for (b=0; b<(to-from)/8; b++) {
val1=0;
val2=0;
val3=0;
val4=0;
val5=0;
val6=0;
val7=0;
val8=0;
for (a=from2; a<to2; a++) {
val1 += srcvec[a].ac * srcmatrix[a+(b*8+from+0)*matrix_width].weight;
val2 += srcvec[a].ac * srcmatrix[a+(b*8+from+1)*matrix_width].weight;
val3 += srcvec[a].ac * srcmatrix[a+(b*8+from+2)*matrix_width].weight;
val4 += srcvec[a].ac * srcmatrix[a+(b*8+from+3)*matrix_width].weight;
val5 += srcvec[a].ac * srcmatrix[a+(b*8+from+4)*matrix_width].weight;
val6 += srcvec[a].ac * srcmatrix[a+(b*8+from+5)*matrix_width].weight;
val7 += srcvec[a].ac * srcmatrix[a+(b*8+from+6)*matrix_width].weight;
val8 += srcvec[a].ac * srcmatrix[a+(b*8+from+7)*matrix_width].weight;
}
dest[b*8+from+0].ac += val1;
dest[b*8+from+1].ac += val2;
dest[b*8+from+2].ac += val3;
dest[b*8+from+3].ac += val4;
dest[b*8+from+4].ac += val5;
dest[b*8+from+5].ac += val6;
dest[b*8+from+6].ac += val7;
dest[b*8+from+7].ac += val8;
}
for (b=b*8; b<to-from; b++) {
for (a=from2; a<to2; a++) {
dest[b+from].ac += srcvec[a].ac * srcmatrix[a+(b+from)*matrix_width].weight;
}
}
}
else { //er mod
for (a=0; a<(to2-from2)/8; a++) {
val1=0;
val2=0;
val3=0;
val4=0;
val5=0;
val6=0;
val7=0;
val8=0;
for (b=from; b<to; b++) {
val1 += srcvec[b].er * srcmatrix[a*8+from2+0+b*matrix_width].weight;
val2 += srcvec[b].er * srcmatrix[a*8+from2+1+b*matrix_width].weight;
val3 += srcvec[b].er * srcmatrix[a*8+from2+2+b*matrix_width].weight;
val4 += srcvec[b].er * srcmatrix[a*8+from2+3+b*matrix_width].weight;
val5 += srcvec[b].er * srcmatrix[a*8+from2+4+b*matrix_width].weight;
val6 += srcvec[b].er * srcmatrix[a*8+from2+5+b*matrix_width].weight;
val7 += srcvec[b].er * srcmatrix[a*8+from2+6+b*matrix_width].weight;
val8 += srcvec[b].er * srcmatrix[a*8+from2+7+b*matrix_width].weight;
}
dest[a*8+from2+0].er += val1;
dest[a*8+from2+1].er += val2;
dest[a*8+from2+2].er += val3;
dest[a*8+from2+3].er += val4;
dest[a*8+from2+4].er += val5;
dest[a*8+from2+5].er += val6;
dest[a*8+from2+6].er += val7;
dest[a*8+from2+7].er += val8;
}
for (a=a*8; a<to2-from2; a++) {
for (b=from; b<to; b++) {
dest[a+from2].er += srcvec[b].er * srcmatrix[a+from2+b*matrix_width].weight;
}
}
//这里防止梯度向量突发增长,导致训练失败
//论文中有提及,少数情况下,误差可能会增长过大,这里限制
if (gradient_cutoff>0)
for (a=from2; a<to2; a++) {
if (dest[a].er>gradient_cutoff) dest[a].er=gradient_cutoff;
if (dest[a].er<-gradient_cutoff) dest[a].er=-gradient_cutoff;
}
}
//struct neuron *dest, struct neuron *srcvec, struct synapse *srcmatrix, int matrix_width, int from, int to, int from2, int to2, int type
//this is normal implementation (about 3x slower):
/*if (type==0) { //ac mod
for (b=from; b<to; b++) {
for (a=from2; a<to2; a++) {
dest[b].ac += srcvec[a].ac * srcmatrix[a+b*matrix_width].weight;
}
}
}
else //er mod
if (type==1) {
for (a=from2; a<to2; a++) {
for (b=from; b<to; b++) {
dest[a].er += srcvec[b].er * srcmatrix[a+b*matrix_width].weight;
}
}
}*/
}