系列前言
参考文献:
- RNNLM - Recurrent Neural Network Language Modeling Toolkit(点此阅读)
- Recurrent neural network based language model(点此阅读)
- EXTENSIONS OF RECURRENT NEURAL NETWORK LANGUAGE MODEL(点此阅读)
- Strategies for Training Large Scale Neural Network Language Models(点此阅读)
- STATISTICAL LANGUAGE MODELS BASED ON NEURAL NETWORKS(点此阅读)
- A guide to recurrent neural networks and backpropagation(点此阅读)
- A Neural Probabilistic Language Model(点此阅读)
- Learning Long-Term Dependencies with Gradient Descent is Difficult(点此阅读)
- Can Artificial Neural Networks Learn Language Models?(点此阅读)
上一篇写到learnVocabFromTrainFile(),下面继续,下面连续几个函数的功能都是保存网络部分信息,或者恢复信息,先把前面的图放在这儿供对比
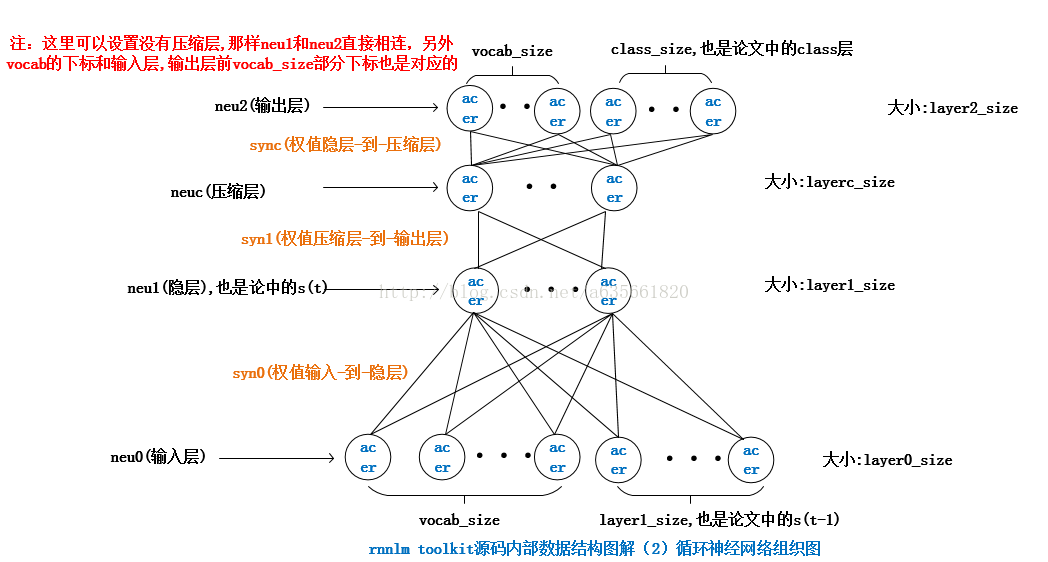
//保存当前的权值,以及神经元信息值,网络的数据结构见图
void CRnnLM::saveWeights()
{
int a,b;
//暂存输入层神经元值
for (a=0; a<layer0_size; a++) {
neu0b[a].ac=neu0[a].ac;
neu0b[a].er=neu0[a].er;
}
//暂存隐层神经元值
for (a=0; a<layer1_size; a++) {
neu1b[a].ac=neu1[a].ac;
neu1b[a].er=neu1[a].er;
}
//暂存压缩层神经元值
for (a=0; a<layerc_size; a++) {
neucb[a].ac=neuc[a].ac;
neucb[a].er=neuc[a].er;
}
//暂存输出层神经元值
for (a=0; a<layer2_size; a++) {
neu2b[a].ac=neu2[a].ac;
neu2b[a].er=neu2[a].er;
}
//暂存输入层到隐层的权值
for (b=0; b<layer1_size; b++) for (a=0; a<layer0_size; a++) {
//这里输入到隐层的所有权值可以理解为一个layer_size*layer0_size的矩阵,只不过用了一维数组来装
//而对应的parameter[b][a]映射到一维数组的下标就是a + b*layer0_size
//对其他层到层的权值存储也是同理的
syn0b[a+b*layer0_size].weight=syn0[a+b*layer0_size].weight;
}
//如果有压缩层
if (layerc_size>0) {
//暂存隐层到压缩层的权值
for (b=0; b<layerc_size; b++) for (a=0; a<layer1_size; a++) {
syn1b[a+b*layer1_size].weight=syn1[a+b*layer1_size].weight;
}
//暂存压缩层到输出层的权值
for (b=0; b<layer2_size; b++) for (a=0; a<layerc_size; a++) {
syncb[a+b*layerc_size].weight=sync[a+b*layerc_size].weight;
}
}
else { //如果没有压缩层
//直接暂存隐层到输出层的权值
for (b=0; b<layer2_size; b++) for (a=0; a<layer1_size; a++) {
syn1b[a+b*layer1_size].weight=syn1[a+b*layer1_size].weight;
}
}
//因为被注释掉了,这里并没有存储输入层到输出层的直接连接参数
//for (a=0; a<direct_size; a++) syn_db[a].weight=syn_d[a].weight;
}
//上面是暂存当前权值及神经元值,这里是从前面存下的数据中恢复
//含义都差不多,不做具体注释
void CRnnLM::restoreWeights()
{
int a,b;
for (a=0; a<layer0_size; a++) {
neu0[a].ac=neu0b[a].ac;
neu0[a].er=neu0b[a].er;
}
for (a=0; a<layer1_size; a++) {
neu1[a].ac=neu1b[a].ac;
neu1[a].er=neu1b[a].er;
}
for (a=0; a<layerc_size; a++) {
neuc[a].ac=neucb[a].ac;
neuc[a].er=neucb[a].er;
}
for (a=0; a<layer2_size; a++) {
neu2[a].ac=neu2b[a].ac;
neu2[a].er=neu2b[a].er;
}
for (b=0; b<layer1_size; b++) for (a=0; a<layer0_size; a++) {
syn0[a+b*layer0_size].weight=syn0b[a+b*layer0_size].weight;
}
if (layerc_size>0) {
for (b=0; b<layerc_size; b++) for (a=0; a<layer1_size; a++) {
syn1[a+b*layer1_size].weight=syn1b[a+b*layer1_size].weight;
}
for (b=0; b<layer2_size; b++) for (a=0; a<layerc_size; a++) {
sync[a+b*layerc_size].weight=syncb[a+b*layerc_size].weight;
}
}
else {
for (b=0; b<layer2_size; b++) for (a=0; a<layer1_size; a++) {
syn1[a+b*layer1_size].weight=syn1b[a+b*layer1_size].weight;
}
}
//for (a=0; a<direct_size; a++) syn_d[a].weight=syn_db[a].weight;
}
//保存隐层神经元的ac值
void CRnnLM::saveContext() //useful for n-best list processing
{
int a;
for (a=0; a<layer1_size; a++) neu1b[a].ac=neu1[a].ac;
}
//恢复隐层神经元的ac值
void CRnnLM::restoreContext()
{
int a;
for (a=0; a<layer1_size; a++) neu1[a].ac=neu1b[a].ac;
}
//保存隐层神经元的ac值
void CRnnLM::saveContext2()
{
int a;
for (a=0; a<layer1_size; a++) neu1b2[a].ac=neu1[a].ac;
}
//恢复隐层神经元的ac值
void CRnnLM::restoreContext2()
{
int a;
for (a=0; a<layer1_size; a++) neu1[a].ac=neu1b2[a].ac;
}
至于为什么会建立压缩层,见论文EXTENSIONS OF RECURRENT NEURAL NETWORK LANGUAGE MODEL,里面说的压缩层是为了减少输出到隐层的参数,并且减小了总的计算复杂度,至于为什么增加压缩层能够使计算量减小,我也不太明白,如果明白的朋友看到还请告知一下哈。
下面这个函数是初始化网络,内容有点多,并且里面有的内容需要图解才能更清楚,所以把这个函数分成两部分写。下面是该函数内部前面的内容,主要是完成分配内存,初始化等工作,这个过程也就相当于把上图那个网络给搭建起来了,参照图能更清楚一些。
void CRnnLM::initNet()
{
int a, b, cl;
layer0_size=vocab_size+layer1_size; //layer1_size初始为30
layer2_size=vocab_size+class_size; //class_size初始时为100
//calloc是经过初始化的内存申请
//分别建立输入层,隐层,压缩层,输出层
neu0=(struct neuron *)calloc(layer0_size, sizeof(struct neuron));
neu1=(struct neuron *)calloc(layer1_size, sizeof(struct neuron));
neuc=(struct neuron *)calloc(layerc_size, sizeof(struct neuron));
neu2=(struct neuron *)calloc(layer2_size, sizeof(struct neuron));
//建立隐层到输入层的权值参数
syn0=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
//如果没有设置压缩层
if (layerc_size==0)
//建立压缩层到隐层的权值参数
syn1=(struct synapse *)calloc(layer1_size*layer2_size, sizeof(struct synapse));
else { //含有压缩层
//建立压缩层到隐层的权值参数
syn1=(struct synapse *)calloc(layer1_size*layerc_size, sizeof(struct synapse));
//建立输出层到压缩层的权值参数
sync=(struct synapse *)calloc(layerc_size*layer2_size, sizeof(struct synapse));
}
if (syn1==NULL) {
printf("Memory allocation failed\n");
exit(1);
}
if (layerc_size>0) if (sync==NULL) {
printf("Memory allocation failed\n");
exit(1);
}
//建立输入层到输出层的参数,direct_size是long long类型的,由-direct参数指定,单位是百万
//比如-direct传进来的是2,则真实的direct_size = 2*10^6
syn_d=(direct_t *)calloc((long long)direct_size, sizeof(direct_t));
if (syn_d==NULL) {
printf("Memory allocation for direct connections failed (requested %lld bytes)\n", (long long)direct_size * (long long)sizeof(direct_t));
exit(1);
}
//创建神经元备份空间
neu0b=(struct neuron *)calloc(layer0_size, sizeof(struct neuron));
neu1b=(struct neuron *)calloc(layer1_size, sizeof(struct neuron));
neucb=(struct neuron *)calloc(layerc_size, sizeof(struct neuron));
neu1b2=(struct neuron *)calloc(layer1_size, sizeof(struct neuron));
neu2b=(struct neuron *)calloc(layer2_size, sizeof(struct neuron));
//创建突触(即权值参数)的备份空间
syn0b=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
//syn1b=(struct synapse *)calloc(layer1_size*layer2_size, sizeof(struct synapse));
if (layerc_size==0)
syn1b=(struct synapse *)calloc(layer1_size*layer2_size, sizeof(struct synapse));
else {
syn1b=(struct synapse *)calloc(layer1_size*layerc_size, sizeof(struct synapse));
syncb=(struct synapse *)calloc(layerc_size*layer2_size, sizeof(struct synapse));
}
if (syn1b==NULL) {
printf("Memory allocation failed\n");
exit(1);
}
//下面对所有神经元进行初始化,值为0
for (a=0; a<layer0_size; a++) {
neu0[a].ac=0;
neu0[a].er=0;
}
for (a=0; a<layer1_size; a++) {
neu1[a].ac=0;
neu1[a].er=0;
}
for (a=0; a<layerc_size; a++) {
neuc[a].ac=0;
neuc[a].er=0;
}
for (a=0; a<layer2_size; a++) {
neu2[a].ac=0;
neu2[a].er=0;
}
//将所有权值参数全部初始化为随机数,范围为[-0.3, 0.3]
for (b=0; b<layer1_size; b++) for (a=0; a<layer0_size; a++) {
syn0[a+b*layer0_size].weight=random(-0.1, 0.1)+random(-0.1, 0.1)+random(-0.1, 0.1);
}
if (layerc_size>0) {
for (b=0; b<layerc_size; b++) for (a=0; a<layer1_size; a++) {
syn1[a+b*layer1_size].weight=random(-0.1, 0.1)+random(-0.1, 0.1)+random(-0.1, 0.1);
}
for (b=0; b<layer2_size; b++) for (a=0; a<layerc_size; a++) {
sync[a+b*layerc_size].weight=random(-0.1, 0.1)+random(-0.1, 0.1)+random(-0.1, 0.1);
}
}
else {
for (b=0; b<layer2_size; b++) for (a=0; a<layer1_size; a++) {
syn1[a+b*layer1_size].weight=random(-0.1, 0.1)+random(-0.1, 0.1)+random(-0.1, 0.1);
}
}
//输入到输出直连的参数初始化为0
long long aa;
for (aa=0; aa<direct_size; aa++) syn_d[aa]=0;
if (bptt>0) {
bptt_history=(int *)calloc((bptt+bptt_block+10), sizeof(int));
for (a=0; a<bptt+bptt_block; a++) bptt_history[a]=-1;
//
bptt_hidden=(neuron *)calloc((bptt+bptt_block+1)*layer1_size, sizeof(neuron));
for (a=0; a<(bptt+bptt_block)*layer1_size; a++) {
bptt_hidden[a].ac=0;
bptt_hidden[a].er=0;
}
//
bptt_syn0=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
if (bptt_syn0==NULL) {
printf("Memory allocation failed\n");
exit(1);
}
}
//saveWeights里面并没有保存输入层到输出层的参数,即syn_d
saveWeights(); 第二部分是对单词的分类,注意下面的vocab是从大到小排好序的,下面都是对word进行分类,分类的依据就是他们的一元词频,分类的最终结果就是越靠近前面类别的word很少,他们出现的频数比较高,越靠近后面的类别所包含的word就非常多,他们在语料中出现比较稀疏。 下面这段代码所建立的结构如下图:
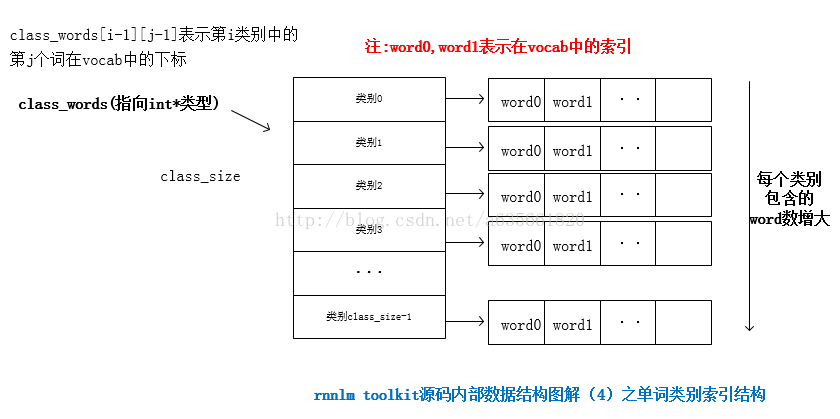
double df, dd;
int i;
df=0;
dd=0;
a=0;
b=0;
//注意这里vocab是从大到小排好序的
//下面都是对word进行分类,分类的依据就是他们的一元词频
//分类的最终结果就是越靠近前面类别的word很少,他们出现的频数比较高
//越靠近后面的类别所包含的word就非常多,他们在语料中出现比较稀疏
if (old_classes) { // old classes
for (i=0; i<vocab_size; i++) b+=vocab[i].cn;
for (i=0; i<vocab_size; i++) {
df+=vocab[i].cn/(double)b;
if (df>1) df=1;
if (df>(a+1)/(double)class_size) {
vocab[i].class_index=a;
if (a<class_size-1) a++;
}
else {
vocab[i].class_index=a;
}
}
} else { // new classes
for (i=0; i<vocab_size; i++) b+=vocab[i].cn;
for (i=0; i<vocab_size; i++) dd+=sqrt(vocab[i].cn/(double)b);
for (i=0; i<vocab_size; i++) {
df+=sqrt(vocab[i].cn/(double)b)/dd;
if (df>1) df=1;
if (df>(a+1)/(double)class_size) {
vocab[i].class_index=a;
if (a<class_size-1) a++;
} else {
vocab[i].class_index=a;
}
}
}
//allocate auxiliary class variables (for faster search when normalizing probability at output layer)
//下面是为了加速查找,最终达到的目的就是给定一个类别,能很快的遍历得到该类别的所有word,该结构见图
class_words=(int **)calloc(class_size, sizeof(int *));
class_cn=(int *)calloc(class_size, sizeof(int));
class_max_cn=(int *)calloc(class_size, sizeof(int));
for (i=0; i<class_size; i++) {
class_cn[i]=0;
class_max_cn[i]=10;
class_words[i]=(int *)calloc(class_max_cn[i], sizeof(int));
}
for (i=0; i<vocab_size; i++) {
cl=vocab[i].class_index;
class_words[cl][class_cn[cl]]=i;
class_cn[cl]++;
if (class_cn[cl]+2>=class_max_cn[cl]) {
class_max_cn[cl]+=10;
class_words[cl]=(int *)realloc(class_words[cl], class_max_cn[cl]*sizeof(int));
}
}
}
上面的函数初始化网络涉及最大熵模型,即可以简单的理解为输入层到输出层的直接连接,虽然作者在论文中总是强调可以这么认为,但我觉的并不是那样简单的直接连接着,中间会有一个历史数组,这个后面会谈到。下一篇的几个函数很容易明白,直接上注释即可,为了省篇幅,放在下一篇