摘要:
无论是但阶段的检测器还是双阶段的检测器都是在原有的分类网络上进行微调的,首先目标检测不仅涉及到分类,还要进行定位。另外就是目标检测使用了类似FPN的这种额外的阶段进行不同尺度的物体的检测。下采样可以带来大的感受野但是削弱了检测的能力,所以作者提出的这个网络是专门用来进行object detection
网络的特点就是:可以在深层网络保持高分辨率。
1 Introduction
- 原因
作者说在使用分类的backbone为了适应不同尺度的要求就需要增加额外的阶段;传统的backbone在下采样的时候可以获得很大的感受野,但是空间分辨率的损失带来了检测精度的下降。
- 网络的特点
DetNet与传统的预训练网络不同,他可以维持特征图的空间分辨率,维持高分辨对于计算量和内存都是一个极大的挑战。为了keep the efficient,检录一种dilate bottleneck structure,总之,DetNet不仅保持了高分辨率,而且好保证了大感受野。
-
论文的贡献
1,分析传统的预训练的网络对于目标检测的drawback
2,发明了一种新的backbone,是为目标检测任务设计的具备高分辨和大感受野的网络
3,在mscoco数据集上使用DetNet59作为backbone进行目标检测和实例分割都却哦啊了很好的结果
2 related work
传统的网络都是分为两部分
one:backbone
two:detect business
one:一些网络,包括Alexnet,VGG使用33 的卷积构建更深层的网络,GoogleNet使用了inception,Resnet使用了bottleneck 。resnext和xception使用了goup 卷积取代了传统的卷积,在增加精确度的同时减少了参数。densnet使用了稠密的连接,进一步减少参数,但是保持了具有竞争力的精确度。另外Dilated Residual Network 使用了更少的stride来提取特征。这些都是用来分类比较好。
two:者一部分的设计就是分为one stage和two stage。单价段的包括yolo(darknet),ssd(VGG,在多层提取特征,处理不同尺度的目标)RetinaNet(resnet,使用focal loss,解决了前景和背景导致的不平衡的问题)。另外就是two-stage的检测器,,首先就是backbone的基础上产生很多的建议区域,faster rcnn使用了一种RPN,R-FCN使用了一中position sensitive feature map 。还是用来一种 position sensitive pooling进行池化。
Deformable convolution Networks使用了一种不带有监督的额外的偏移量来实现卷积操作。 FPN使用一种金字塔建立卷积神经网络。FPN使用U-shape 结构的进行多层输出。
3 DetNet: A Backbone network for Object Detection
motivation
1,网络的stage的数目是不一定的
经典的网络是五层,每一层都包括下采样层,步长位2的卷积层,输出的特征图是3232 的,然而金字塔网络使用的是更多的层,例如,FPN增加了第六层处理大物体,RetinaNet增加了六七层。
2,大物体的识别率
语义信息比较强的特征图是stride是32,可以带来很大的感受野,但是在深层网络进行预测的时候,大的物体的边界就比较迷糊,很难精确的回归。
3,小物体不可见
large stride丢失了小物体,小目标的信息将会削弱,特征图的空间信息变弱,大量的语义信息被整合,因此,FPN设计了在浅层检测小物体,这样就会导致浅层的语义信息很少不足以分类和检测。因此网络需要将来自深层网络的高层语义信息用来提高分类的能力。然而,小物体经常会在深层消失,语义信息同时也会消失。
作者设计网络,虽然stage的数量有所增加,但是增加带来了高分辨率,并且还有大的感受野,另外stage数量增加都是为目标检测设计的。可以检测到小物体。 -
DetNet design
采用了rennet50 作为backbone,保持了resnet 的1234层,
将backbone作为目标检测,提高效率具有俩个挑战,
1,在深层网路保持空间分辨率就会导致时间和空间的消耗
2,减少下采样就会减少有效的感受野,对于多视觉的识别是有害的,例如图像分类,和语义分割。
DetNet解决了两个问题,第一阶段与第四阶段都保持了相同的设置,从第五层就不一样了detail design不同描述如下:

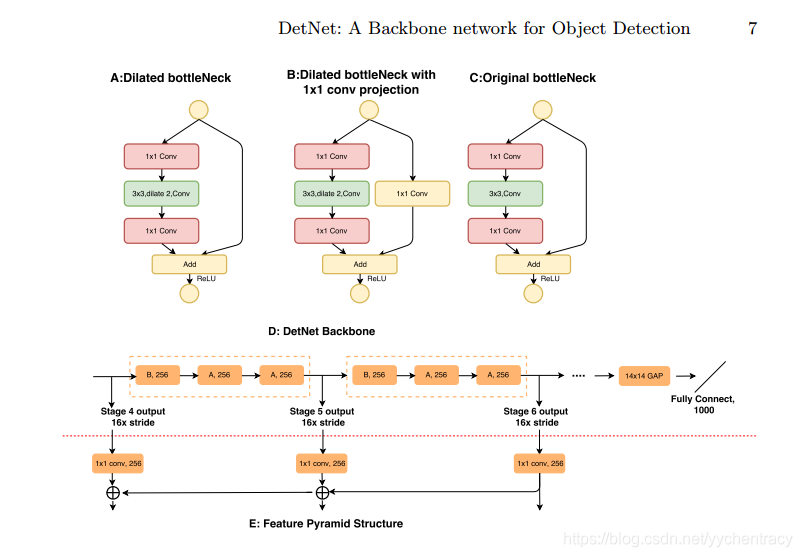
采用了FPN作为baseline去验证DetNet的有效性因为我们不会减少第四层的spacial size。至顶向下的方式sum the output 。
4 experiment
使用了MSCOCO,一共是81类,训练集是80K,验证集是40k,又把验证集分为35k的large 和5k的mini。测试集是5k。 -
Detector training and inference
SGD
monument:0.9
每个mini-batch是2张图片
batch size是16
将图像的短边是800pixel,长边是1333为了减少内存的消耗。
learing rate设置为0.02开始。在120k从迭代和160k迭代减少至0.1,最终是180k的迭代。We also warm-up our training by using
smaller learning rate 0:02 × 0:3 for first 500 iteration(这句是什么意思不懂)

-
Backbone training and Inference
不详细介绍了 -
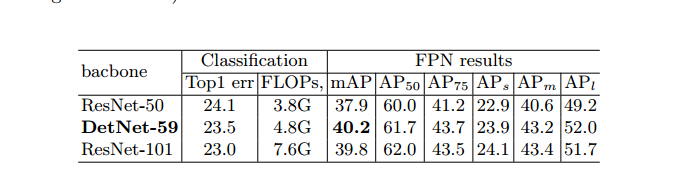
Main Results
DetNet: A Backbone network for Object Detection 笔记 - Jinlong_Xu的博客 - CSDN博客 https://blog.csdn.net/Jinlong_Xu/article/details/80006127