1.使用FPN等网络的缺点:
- 预训练不一致:传统的ResNet或者VGG的stride等于32(就是输入图片和最后的特征图大小的比例),按照每个阶段(stage)的特征图尺度减少为原来的1/2来计算,通常会有5个stage(P1-P5),而FPN中存在P6,RetinaNet中存在P6和P7,而P6和P7是没有被预训练过的。(然而P6和P7已经对任务很敏感了,还需要预训练么,会不会多余?当然文章中并没有讨论这个问题)
- 大物体的回归弱:在FPN等物体检测网络中,大物体是在比较深的特征图上预测(因为深的特征图对应原图的比例大,感受野大,对应的anchor的scale大),然而由于特征图越深,物体边缘的清晰度就越差(模糊),就很难准确回归;
- 小物体在小分辨率特征图上不可见:由于特征图的分辨率减少到原来的1/32,或者更小,小物体在上面是不可见的(32x32的物体在上面只有一个点),FPN等方法,使用分辨率大但是比较浅的层来解决这个问题,由于这些层的语义信息比较弱,没有充分的能力去识别物体,FPN把浅层和语意信息强的深层相加,来提升浅层的语义表达能力,但是由于小物体已经在“深层”中消失,所以他们的语义信息也会丢失。
2. 为了解决上述问题—DetNet:
- stages的数量是为物体检测设计的(个人理解是在ImageNet上预训练和训练物体检测时的stage数目一致);
- 引入了更多的stage(6-7),保持了特征图的分辨率,同时也保证的感受野的大小;
3. 针对Detection设计网络的两大挑战:
- 需要保持特征图的尺度足够大(小物体不会消失,同时保证特征图的保存更清晰的边缘信息),但是这样会占用更多的内存(显存爆了)和计算量;
- 减少下采样的数目(为了保持特征图的分辨率),但是这样感受野的大小无法保证(物体分类和语意分割都需要足够的感受野);
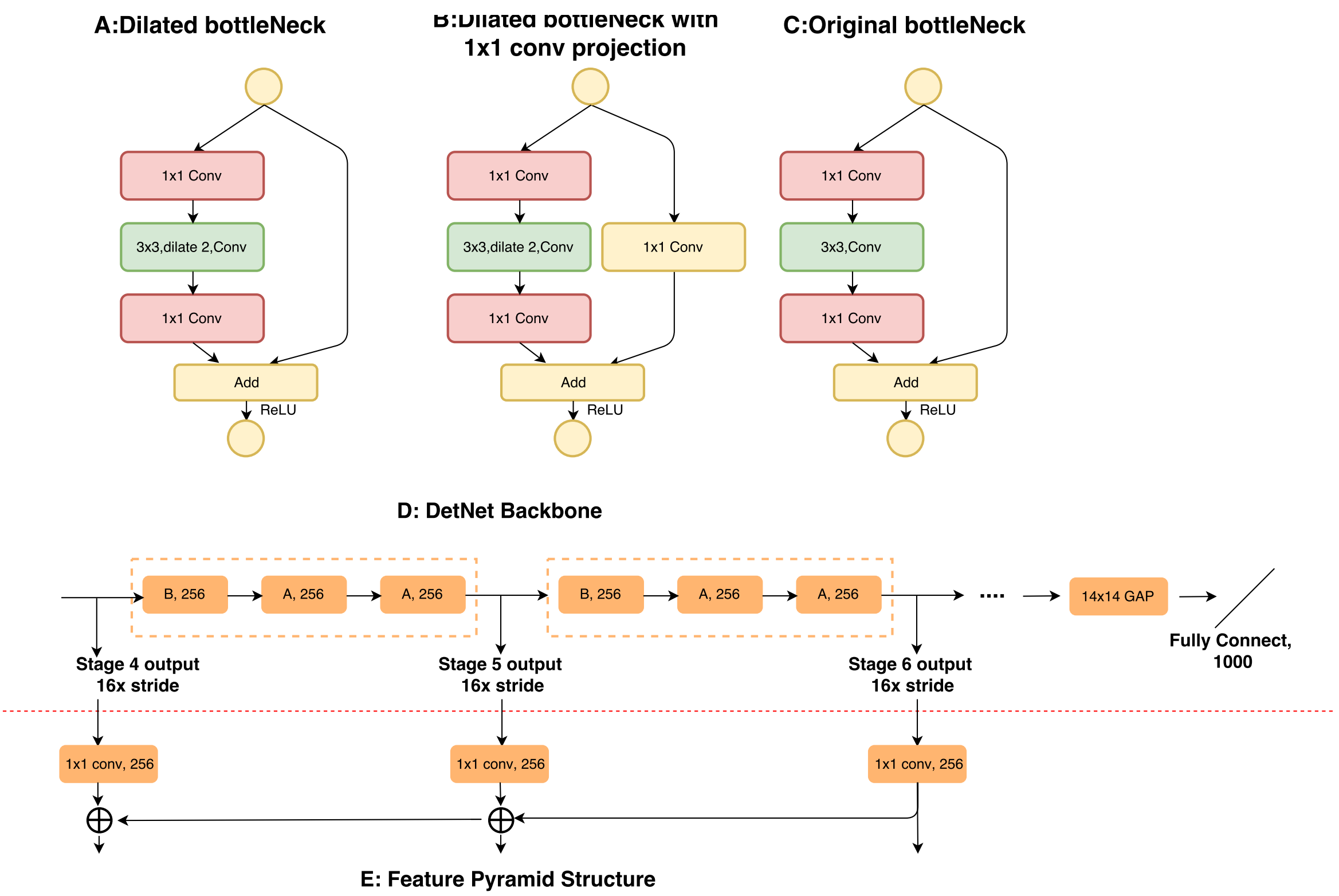
4. DetNet结构:
与ResNet相比,DetNet保留了ResNet50中的stage1-4(ResNet50一共有stage1-5);
针对Detection的两大挑战,DetNet的stage5与ResNet50不同,同时增加了额外的stage6,其设计细节如下:
- stage4-6这三个stage的stride都是16,也就是这三个stage的特征图都是原图尺寸的1/16,而原本的ResNet50的stage5的特征图是原图尺寸的1/32;
- 提出了dilated bottleneck,分成A和B两种,具体的使用顺序如图D;
- 使用dilation技术的目的是增大感受野(保证了特征图的尺寸),然而考虑到计算量和内存,stage5和stage6保持了相同的通道数目(256的输入通道,而不是像传统的backbone一样,每个阶段通道数增加一倍)
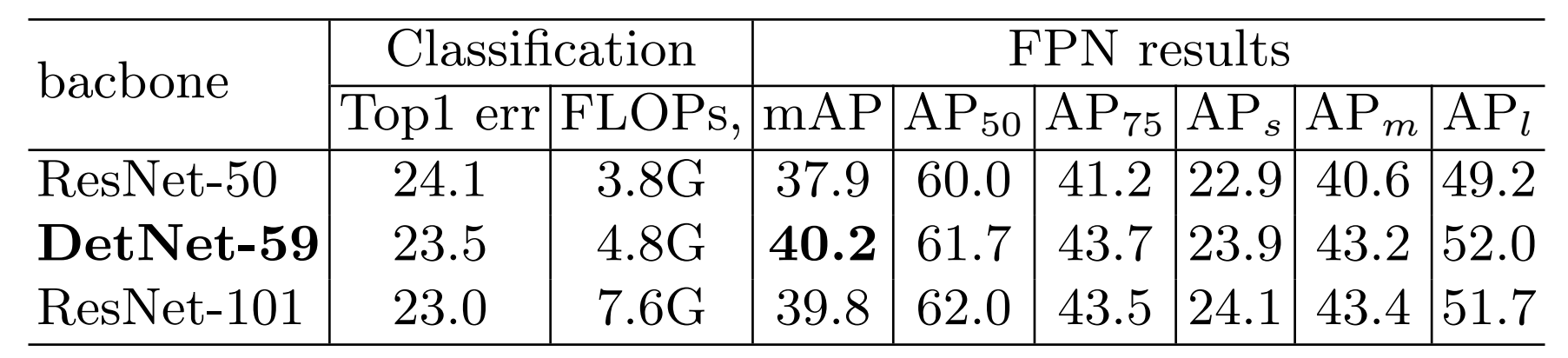
5. 实验结论
首先需要说明,虽然是针对Detection设计的网络,但还是需要在ImageNet Pretrain才可以,足以说明Pretrain的重要性,同时像BatchNorm等参数在Finetune时需要固定,所以这些参数需要在Pretrain时得到;