摘要
目前基于CNN的对象检测器,无论是一阶段的方法,比如YOLO、SSD、RetinaNet还是二阶段的检测器,比如Faster R-CNN、R-FCN、FPN都是直接finetune从ImageNet预训练好的模型,这些模型是专门用于图像分类的。只有很少的工作用于目标检测的backbone特征提取上。更重要的是,图像分类任务和目标检测任务都很多不同点。(i)(ii)都用来说明不同之处。根本原因在于: Large downsampling factor brings large valid receptive field, which is good for image classification but compromises the object location ability。大的下采样带来大的感受野,这个对分类任务是有利的,但对于检测任务是不利的。于是,我们提出了DetNet,它虽然相对于传统的基本网络增加了额外的阶段,但是保持了高空间分辨率in deeper layer。它在COCO标准上达到了最高的结果。
理解:提出了一个专门用于目标检测的backbone,增加了额外的stage,仍保持了high spatial resolution in deeper layers。
介绍
1.使用传统的分类backbone有两个问题:(i)为了检测多尺寸的目标,最近的检测器,如:FPN相比较于传统网络增加了额外的stages,(ii)传统的backbone由于大的下采样,产生了更大的感受野,这对于分类任务而言是有利的。然而,这对于精确定位大物体和识别小物体是不利的。
2.DetNet是怎样做的呢?增加了额外的stages,而且用了dilated bottleneck结构。**和RFB-Net一样,采用dilated bottleneck结构的主要目的是提高效率。**通过结合他们,DetNet不仅保持了高分辨率feature map而且保持了大的感受野。
3.总结一下,我们主要有以下贡献:
(1)分析了传统ImageNet预训练模型对于目标检测固有的缺点。
(2)提出了一个新颖的backbone,专门用于目标检测任务,保持了空间分辨率和感受野。
(3)依据DetNet59backbone实现了COCO检测任务的最高水平。
相关工作
在网络结构上,基于CNN的检测器可以被分为两个部分:第一个是backbone network,第二个是detection business part。下面简单介绍一下这两个部分:
2.1 Backbone Network
许多新型网络被设计,用于在ImageNet数据集上取得高分。AlexNet是第一个增加CNN深度的网络,为了减少网络计算代价,增加有效感受野,AlexNet下采样32倍,这成为后来网络设计的一个标准。VGGNet叠加3x3卷积操作构建更深的网络,仍然包含32倍下采样。后面的研究基本都是VGG网络,每个stages设计一个更好的部分。GoogleNet提出inception block来包含更多样的特征。
2.2 Object Detection Business Part
1.对于目标检测,有两种不同设计逻辑。第一种就是一阶段检测器,直接使用backbone来目标检测。比如,YOLO使用一个简单有效的backbone网络DarkNet,把检测任务看作一个回归任务。
SSD采用阶段的VGGNet,在多层提取特征,使得网络可以处理多尺寸目标。RetinaNet使用ResNet作为特征提取网络,用Focal loss来解决由于前景背景比例所造成的样本不均衡问题。另一个流行的逻辑就是两阶段检测器。具体来说,现在两阶段检测器都会先基于backbone预测很多proposals,然后一个额外的分类器用于proposal分类和回归。Faster R-CNN直接从backbone产生proposals,通过RPN网络。R-FCN从backbone的输出中产生一个位置敏感的feature map,然后使用对每个proposals使用pooling方法。。。。。
2.总之,传统的backbone都是用于ImageNet分类任务的,适用于目标检测任务的backbone仍然是空窗。。。。我们设计DetNet,其主要目的就是设计一个更好的backbone用于目标检测。
DetNet
3.1 Motivation
1.分类任务的设计原则并不适用于定位任务,因为传统的网络比如VGG16和Resnet的feature map的空间分辨率是逐渐降低的。一些技术比如FPN,空洞卷积都被用于这些网络来保持高空间分辨率。所以,分辨率逐渐降低是不好的。一些技术被用于来控制其降低,但还是会有以下几个问题:
(1)网络stages数不同。正如图1B显示的那样,典型的分类网络包含5个stages,每个stage都会下采样feature map通过2倍的pooling或者步长为2的卷积。因此输出feature map空间分辨率是32倍下采样。不同于传统分类网络,特征金字塔检测器采用了更多stages。比如,FPN中,增加额外的stage P6来处于大目标,P6和P7以相同的方式增加在RetinaNet中。显然,在ImageNet数据集中这些额外的stages不是预训练好的。
(2)大物体的弱可视性。强语义信息的feature map是输入图像的32倍下采样,会带来大的感受野,导致了ImgeNet分类任务的成功。但是,large stride对于定位是有害的。FPN中,大物体在deeper layer被预测,这些物体的边界太模糊以至于不能得到精准的回归。当更多的stages添加到分类网络中,这种情况就会更加糟糕,因为更多的下采样带来更多的stride。
(3)小物体的不可见性。large stride的另一个缺点就是丢失小物体。来自小物体的信息很容易被削弱,因为feature maps的空间分辨率会降低,大的语义信息会产生。因此,FPN在浅层预测小物体。然而,浅层只有非常低的语义信息,这对于识别目标的类别而言是不够的。因此,检测器必须增强他们的分类能力通过来自深层的高层次语义信息。然而,如果小物体在深层丢失了,那么这些语义信息也会同时丢失的。
2.为了解决这些问题,提出DetNet,它有下面几个特点:(1)stages的数量是直接为目标检测设计的。(2)即使我们增加了更多的stages,我们保持了feature map的高空间分辨率,同时也保持了large感受野。
3.DetNet有以下几个优点:(1)DetNet和ResNet的stages数目相同,因此额外stage比如P6就可以在ImageNet数据集上预训练。(2)受益于最后stage的高空间分辨率,DetNet在定位大物体的边界和找到丢失的小物体上都非常有效。
3.2 DetNet Design
1.在本节中,我们会展示DetNet的细节结构。采用ResNet50作为baseline。为了和ResNet-50公平比较,我们将stage1,2,3,4设置为原始的ResNet-50。
2.对于目标检测,构建一个有效的backbone,有两个挑战。一方面,保持deep神经网络的空间分辨率需要花费很多时间和空间。另一方面,减少下采样factor等同于减少有效感受野,对于很多视觉任务而言是极其有害的。
3.DetNet是用于解决这两个挑战的。具体来说,DetNet和ResNet的第一个stage到第四个stage的设置是完全一样的。差别从第五个stage开始,一个DetNet的概览可见下图:
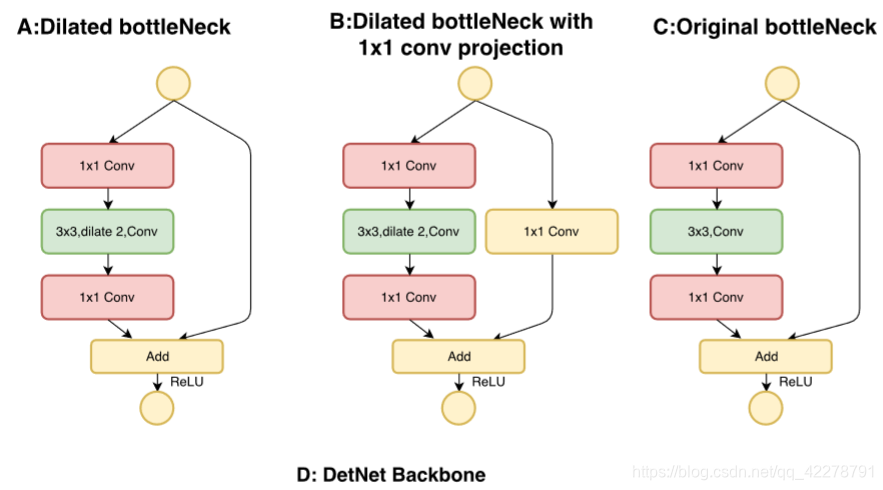
接下来讨论DetNet59的实现细节。同样,我们的DetNet也可以很容易地被ResNet101来扩展。DetNet59的实现细节如下:
(1)引入额外stage,P6。同时,stage4后固定空间分辨率为16倍下采样。
(2)因为stage4后的空间分辨率是固定的,为了引入新stage,在每个stage开始之前,我们使用dilated bottleneck:1x1卷积映射。
Experiments
COCO数据集有80类。训练集有8万张图片,验证集有4万张图片。将4万张验证集分成3.5万张large-val,5千张mini-val。
4.1 Detector training and inference
1.
2.
4.2 Backbone training and Inference
4.3 Main Results
1.用FPN和ResNet-50作为baseline。为了验证FPN的DetNet有效性,我们提出DetNet-59,相比较于ResNet-50,有一个额外的stage。在第三节中可以找到更多设计细节。我们用DetNet59来代替ResNet50,其他结构和原始的FPN保持一致。
所以:先要搞清楚ResNet50
我们首先在ImageNet分类上训练DetNet59,表一显示了结果。DetNet-59实现了23.5%top-1错误率。然后我们用DetNet-59来训练FPN,和用ResNet-50来训练FPN作比较。
因为DetNet-59比ResNet-50有更多参数,一个自然的假设就是这个提升是由于更多参数造成的。为了验证DetNet-59的有效性,我们也用ResNet101来训练FPN。
4.4 Results analysis
目标检测有两个重要的评测指标,一个是average precision(AP),另一个是average recall(AR)。AR意味着我们可以找到多少物体,AP意味着多少物体可以被正确预测(即对于分类而言正确的label)。AP和AR总是会在不同的IOU阈值上进行评估来验证回归能力。IOU越大,越需要更精确的回归。AP和AR也总是会在不同大小的bounding box上评估。