DetNet: A Backbone network(骨干网络) for Object Detection
3.1
最近目标检测依赖于在ImageNet预训练好的骨干网络。ImageNet分类任务不同于目标检测的地方是目标检测不仅需要识别目标类别而且需要目标的空间位置信息。ImageNet的设计原则在定位任务上并不好因为特征图的空间分辨率逐渐降低,VFGG16和Resnet都是如此。一少部分方法例如FPN和扩张卷积被用在这些网络中来维持空间分辨率。然而,训练骨干网络中仍有一下三大麻烦。
多加入的stage无法pre-train。
large object localization不准。
small objects丢失。
DetNet克服了这些缺点
(i) stage数量直接为目标检测而设计,多加入的stage可以pre-train。
(ii) 尽管我们加入了更多的stages,我们获得了高的空间分辨率,大的感受野。
large object localization更准,能找到丢失的small objects。
3.2 DetNet Design
采用ResNet-50做baseline,stage 1,2,3,4保留原来网络。
细节如下:
引入额外的层P6。
stage4后用3x3扩张卷积保持尺寸,加入 1x1 projection convolution。
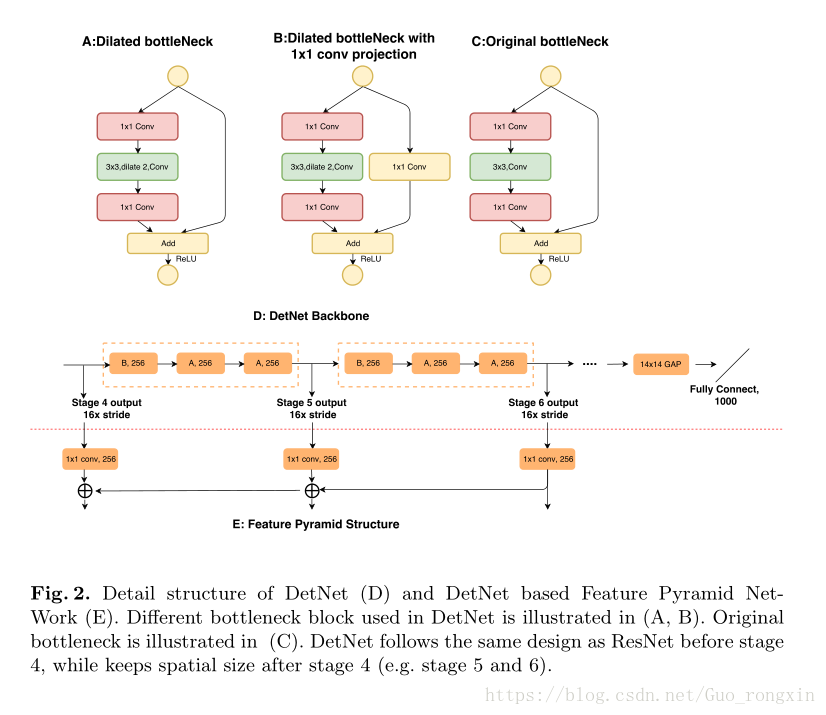
加入扩张卷积的bottleneck输出维度保持输入大小(256)不加倍,减少运行时间。
实验
训练策略参见https://github.com/facebookresearch/Detectron
所有实验用ImageNet预训练的权重初始化。
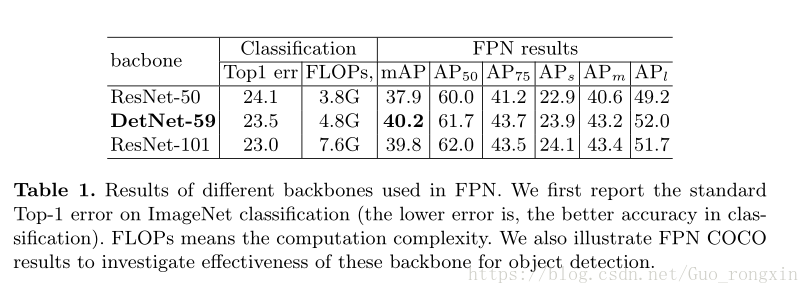

目标检测中两个指标最为重要,平均准确率AP,平均召回率AR。AR指示找到多少目标,AP指示多少目标被正确预测。
DetNet-59大大提高了定位大目标的表现,
提高了5.5个百分点。原因是初始的基于ResNet的FPNstride太大,大目标位置太模糊。
DetNet发现丢失的小目标能力更强。
因为DetNet-59的stage-6和stage-5的spatial size一样,一个自然的想法就是DetNet-59只是用了一个更深的stage-5.为了证明DetNet-59确实加了一层stage,实验去掉 1x1 projection convolution,结果如下。
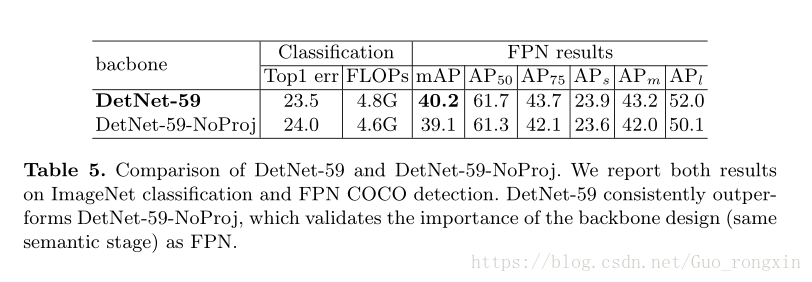
当没有 1x1 projection convolution的时候,输出特征图和输入特征图区别不大,因为输出只是简单的输入和输入的变形相加。因此提取不到新的语义信息。当加入 1x1 projection convolution时,输入输出差别更大,more divergent,可以得到新的语义。
另一个自然的想法是如果我们用ResNet-50的参数初始化FPN的训练,fine-tuning的时候再扩大到stage-5(ResNet-50-dilated),结果会如何。

显然,消耗资源更多,效果更差。因此,直接训练基础模型非常重要。