前言:
文本为根据学堂在线 xuetangx.com 的《高级数据库系统》课程的学习视频与讲义,以及习题整理得到的,主要用于概念梳理和(针对本人的)重难点摘录。仅供交流学习用途,如有遗漏或错误,请指出,谢谢!
PS:第一次用markdown写,并且是这里的第一篇正式博客,加油!(由于版权原因吧,网站只提供了图片形式讲义,因此如果涉及到相关问题,必将改正,还请谅解)
后记:用markdown写完好乱……基本上变成ppt的复刻了,前面重新排版了部分内容,后面的等用了再部分归纳,里面一些概念理解的确不到位,需要指点……课程目录
第一讲 数据文件的组织与索引技术
第二讲 查询处理与优化
第三讲 数据管理与恢复技术
第四讲 事务并发调度的相关概念
第五讲 基于封锁的并发控制机制
第六讲 并发控制的其他机制
第七讲 分布式数据库基本概念
第八讲 分布式数据库的设计
第九讲 分布式数据库查询机制
第十讲 分布式数据库的事务管理及恢复机制第一讲 数据文件的组织与索引技术
掌握数据库的数据组织和储存方式,掌握常用的索引结构,顺序索引,B+树索引,散列索引
1.1 数据文件的组织:
字段:一定长度的字节序列
记录:定长记录;变长记录
集合:物理邻接;指针连接;mixed
大字段值(BLOBS):存储在一系列块中,且这些块在磁盘上顺序分配
1.2 文件组织形式:
- 堆文件
- 顺序文件:记录按照某个搜索码的值顺序存储
优点:按搜索码检索,效率高
缺点:不利于插入删除操作,维护困难- 散列文件:将具有相同搜索码值的记录散列到外存同地址范范围中
优点:便于插入删除操作;不需要索引区,节省存储空间
缺点:支持按搜索码的随机查询;哈希函数选择不当易造成桶倾斜- 聚簇文件:每块可存储多个有关联的关系。
优点:支持高效率的多表连接查询
缺点:降低单表查询的效率- 按列存储:适应统计查询及OLAP应用的存储方式(OnLineAnalyticalProcessing)
优点:减少无用数据的读入量;利用数据压缩减少访问磁盘次数1.3 数据文件索引结构
- 索引记录:由一个搜索码值和指向具有该搜索码值的一个或多个记录的指针构成
聚集索引--非聚集索引
稠密索引--稀疏索引
有序索引--散列索引顺序文件索引
结构:文件按搜索码值的顺序存储,索引文件按搜索码值排序——主索引
稀疏索引特点:查找相对慢,但占空间小,易于维护,一般以基本块为单位建立
稠密索引特点:查找快,但占空间大,不易维护
数据修改期间索引维护:移动记录过多时,加溢出块
多级索引:先建立稠密主索引,然后在主索引文件上建立稀疏索引辅助索引:是非聚集的稠密索引,索引文件顺序和文件存储顺序不一致
B+树索引:商用软件的首选
总体结构上,是一种多级索引,采用平衡树结构,参考《数据结构》B+树的相关知识
结构:根节点;叶节点;非叶节点
特点:可以作主索引,也可以作辅助索引;作主索引时,可以是稀疏的,或稠密的。
查询:从一个根节点到叶节点的路径遍历过程,这个路径长度不超过 log[(n-1)/2]K
效率:
节点大小n是根据存储块的大小决定的,n足够大时,分裂合并(维护成本高的)情况少。
一般不多于三层;磁盘I/O数量是层数+1
假设磁盘大小4K,键值对大小20Byte,n约等于200,每个节点半满,三层B+树包含键值总数约100万个;- 散列索引:散列函数h,搜索码值K,利用h(K)将记录分布到B个桶中
静态散列(B不变)
动态散列:可扩展散列技术;线性散列技术;分段散列技术
可扩展散列特点:散列函数值转化为二进制,前i位表示桶的数量,桶数量是2的幂
散列索引特点:桶扩展代价大;直接寻址,支持随机查找;散列函数寻找困难1.4 appendix
自学:分段散列索引;R树索引;kd树索引;四叉树索引的结构和使用范围。
习题:
散列文件适合于特定值的查询,此种文件组织不适合建立索引。(正确)第二讲 查询处理与优化
掌握查询处理过程。包括:语法分析,生成查询语法树,把语法树转换成关系代数表达式,利用等价变换优化代数表达式,创建物理查询计划。
2.1 查询代价的测量方式
查询代价:查询所涉及资源(磁盘存取,CPU时间,通信开销)的使用情况
响应时间 = 磁盘存取时间 [+ CPU运算时间 + 数据传输时间(不考虑远程访问) ]
一般,查询代价指 **磁盘块传送数量** 作为实际代价的度量,忽略写操作的代价2.2 查询处理过程概述
01 SQL语句
02 语法分析(语法树) --> 查询编译(至05)
03 初始逻辑查询计划 --> 元数据 统计数据(至05)
04 优化逻辑查询计划
05 创建并优化物理查询计划
06 查询执行引擎 --> 数据
07 查询结果
参考视频实例- 创建优化物理查询计划并执行:
选定“叶子”关系表输入(扫描)策略。//由上一层关系实现算法确定
选定实现“非叶子”节点操作的算法细节和中间结果的保存形式。
确定各种物理操作执行顺序。2.3 关系操作的基础算法
主要有三类:基于排序、散列、索引的算法
根据数据规模(等同难度):有一趟、两趟、三趟算法。
2.3.1 一趟算法
一趟算法只读一次文件。对于二元操作需要至少有一个可以全部读入内存。
搜索代价为文件占磁盘块数。
方法:选择σ和投影π运算——一次多个元组;消除重复δ和分组γ——一次一个关系。2.3.2 两趟算法
- 排序(物理)归并算法
标准内存排序算法:二路归并算法,一般推广为N路归并算法
代价 = {Br*2log[M]Br} ::关系r所包含的磁盘块数Br, 缓存区用于输入的磁盘块数M。 2表示读入+读出,NlogN是归并排序的复杂度。
如果M=2,每块容纳2个记录,Br对应6块,则需要36次块传送- 基于排序算法的关系操作总体框架:
运用N路归并算法为将要运算的关系生成M个归并段
全部排序后或在归并过程中进行各种运算操作。- 基于排序的选择运算(借鉴以上框架)
一般作用在非码属性上,先排序,再二分搜索 - 消除重复元组,分组统计运算的实现(借鉴以上框架)
归并过程中运算,缓冲区中操作
注意:子表数 <= M
如M=3, 代价 = 归并代价 + 两个文件块之和*2 - 自然连接运算(类似)
- 基于排序的选择运算(借鉴以上框架)
- 基于散列的两趟算法
散列技术:搜索码值集合K到桶地址集合B上的映射函数Bi = h(Ki)
基于散列技术算法框架
利用散列函数对关系进行划分,生成N[h]个散列桶
读取操作所需的桶内数据,实现指定操作划分代价:2Br (读入读出)
当关系非常大时,要进行递归划分,直到满足 M > (Br/M)+1 。 每趟将分区大小减少为原来1/M,则划分趟数为 log[M]Br - 1 ,结合上式,递归划分代价为 2Br*趟数
整体代价 = 划分代价 + 分区读入 = 3Br- 基于索引的算法
代价 = 索引遍历代价, 如果是B+数索引,代价=树高度+取记录I/O操作
当A为非码,利用辅助索引,记录可能分布在不同磁盘块上,运算代价高
内层连接上使用索引,代价 = Br + r的记录数 * 单个元组操作代价
2.4 查询表达式的运算
- 实体化方法
过程:从树的最底层开始,输入关系利用前面算法执行运算,并将结果保存到临时关系中作为高一层和输入
代价:所有运算代价和 + 把中间结果写回磁盘的代价
所以需要估计中间结果的大小, 具体估算略。- 流水线方法
将运算组成流水线,一个运算结果传送到下一个运算,从而去除读写临时关系的代价。
通过系统中的进程或线程建模,从流水话的输入中接受元组流,并产生一个元组流输出。
对流水线中每一相邻操作,均创建缓冲区保存上一操作输出的元组。
缺点:各操作间数据的依懒性较强。
解决方法:需求驱动;生产者驱动
对算法有限制:索引嵌套循环,但归并连接不能用;比实体化方法代价高,因此实体化方法更容易接受,可采用双缓冲技术提高实体化方法效率2.5 查询优化机制
从众多查询策略中找出最有效的查询执行计划的一种处理过程。
查询优化的过程:逻辑层次(关系代数等价变换),物理层次
关系表达式的等价变换:启发式算法,选择较小代价的变换(把选择运算尽量推到叶子方向;把投影运算尽量推向叶子方向;利用统计信息确定哪些运算会产生最小的关系)
物理查询计划的选择:为每个操作符确定算法;流水线的识别;运算次序的确定(枚举技术)所以不要写太复杂的查询语句
2.6 appendix
- 关系代数运算:
- 集合操作:union, intersection, difference, cartesian_product(笛卡尔积)
- 纯关系操作:project(投影), select(选择), join(连接), division(除)
投影操作是从关系R中选出某些列
选择操作就是从关系中选出符合条件的元组
连接操作是先对两个关系做笛卡儿积生成一个新的关系,然后在新的关系上做选择操作
除操作,简单说R/S表示,R关系有的但不包含在S关系中的属性集,且product(R/S, s) 出现在R中
自然连接:一种等值连接,连接操作后取属性取值相等的,然后去掉重复列。
外连接:为避免自然连接中元组信息丢失,将未匹配元组与空元组连接。包括:左外连接,右外连接,全外连接。
ref: https://www.cnblogs.com/xidongyu/articles/5980407.html
- 习题:
对于一个提交的SQL语句,关系数据库管理系统需要在查询编译器中对其进行处理并生成最终的查询计划。
流水线方法比较适合于关系代数中的选择和投影运算
第三讲 数据管理与恢复技术
要求熟悉UNDO、REDO和UNDO/REDO三种日志类型的特点,掌握系统故障时,系统使用不同日志类型恢复数据库的算法。能够针对不同日志类型特点,编写利用日志文件恢复数据库的算法。
3.1 数据库的故障恢复
- 数据库的故障与恢复方法:
01 错误的数据输入:应用程序检测机制
02 系统错误:掉电或软件错误引起,通过数据库恢复机制进行恢复
03 介质故障:数据存储时的奇偶校正,或采用RAID技术
04 灾难性故障:数据库介质完全损坏,及时备份
3.2 事务与日志的概念
事务 Transaction:访问数据库的一个逻辑单位,由若干查询或更新数据的语句进行。
事务的特点 ACID:原子性, 一致性, 隔离性, 持久性
事务的状态:活动状态--最后一个语句--提交状态(失败状态--终止状态)
事务管理器的工作原理:
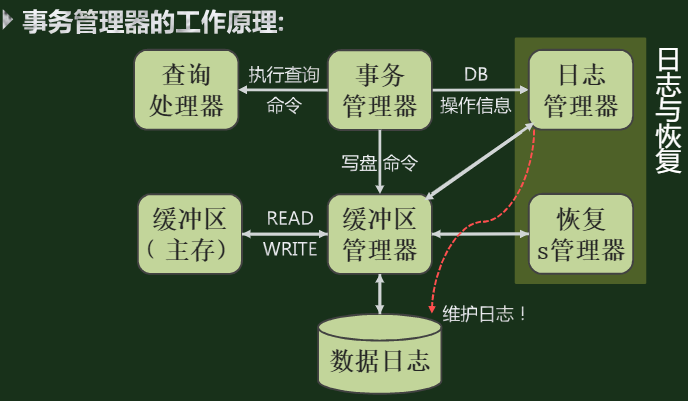
用于记录日志的重要事务原语:事务与数据库交互的三个重要地址空间:
01 磁盘块空间
02 缓冲区管理所管理的主存地址或虚存地址
03 事务的局部地址空间(变量t)
01 --> INPUT --> 02 --> READ --> 03t
03t --> WRITE --> 02 --> OUTPUT --> 01主要关心磁盘的变化,也就是input和output过程
日志:日志记录操作的序列;对于数据库来说,日志记录每个事务每个步骤执行及其效果,一个日志可以记录多个事务的执行情况。
刷新日志记录命令(FLUSH LOG):使当前缓冲区的日志记录“强制性”写入磁盘。
日志包含的元素:
<START T>
<COMMIT T>
<ABORT T>
<T2,Update,A,100,200>
Checkpoint(检查点记录)3.3 基于日志的恢复机制
常用三种日志类型:undo日志、redo日志、undo/redo日志
undo日志及其恢复机制
- 日志记录格式:<T, op, x, v> op表示更新操作类型,x表示被更新的数据对象,v表示x更新前的原值。
- 创建undo日志的规则:
(更新数据时)写日志-->写数据;
(提交事务前)写数据-->写 - 恢复原则:撤销没有提交的事务
- 恢复:进行恢复时,从后向前扫描日志,遇到有Commit的事务忽略,没有Commit的事务则将对数据库更新进行撤销
- 设置检查点的规则:
01 在某些事务开始时,写日志<START CKPT(T1,...Tk)>,并刷新日志FLUSH LOG
02 等待事务的提交或终止,在此期间可以有其他事务Tj开始
03 当T1...Tk提交或终止后,写<End CKPT(T1, Tk)>,并刷新日志FLUSH LOG- 利用检查点恢复数据库策略:
第一步,从故障点开始,逆向扫描日志文件,确定故障发生时没有完成的事务。
第二步,恢复操作沿着逆向扫描日志方向,恢复原值
注:逆向扫描时,先遇到END CKPT时,扫描至START CKPT,撤销没有提交的事务;先遇到START CKPT时,扫描至前一个START CKPT,撤销没有提交的事务。redo日志进行恢复
为了减少I/O操作,等缓冲区较满时,保存到磁盘中
日志记录格式:<T, op, x, w> w表示x更新后的新值。
**创建redo日志的规则**: (更新数据时)写日志-->写数据
(提交事务前)写<COMMIT T> --> 写数据- 恢复原则:重做已经提交的事务
- 设置检查点的规则:
01 写日志记录<START CKPT(T1,...Tk)>,并刷新日志FLUSH LOG
02 在写<START CKPT(T1,...Tk)>前,缓冲区中所有已经提交、但未写入磁盘的数据库操作,完成写盘操作。
03 写<End CKPT(T1, Tk)>,并刷新日志FLUSH LOG
注:redo日志的事务可能跨越多个检查点!!- 利用检查点恢复数据库策略:
步骤同上
注:逆向扫描时,先遇到END CKPT时,则扫描至START CKPT,重做期间COMMIT的事务;先遇到START CKPT时,则扫描至上一个START CKPT,重做期间COMMIT的事务(这些事务可能跨越多个检查点)。
undo/redo日志进行恢复
- 日志记录格式:<T, op, x, v, w>
- 创建规则:
(更新数据时)写日志-->写数据
(提交事务前)之前或之后- 恢复原则:重做已经提交的事务,撤销没有做完的事务。
- 设置检查点的规则:
写START CKPT(T1,...Tk),并FLUSH LOG
把所有缓冲区的更新数据,写入磁盘
写入END CKPT,并FLUSH LOG- 恢复策略:
故障点起逆向扫描,确定需要重做和撤销的事务
重做COMMIT的事务;逆向撤销没有COMMIT的事务。
3.4 Appendix
- RAID技术:
独立磁盘冗余阵列RAID(Redundant Arrays of Independent Drives), 被看作是由两个或更多磁盘组成的存储空间,通过并发地在多个磁盘上读写数据来提高存储系统的 I/O 性能。RAID 5把数据和与其相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当其中一个磁盘(最多一个)数据损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据,是存储性能、数据安全和存储成本兼顾的存储解决方案。(ref: 百度搜索)
第四讲 事务并发调度的相关概念
4.1 并发及相关概念
- 事务并发:在某一时间段内,多个事务同时存取相同的数据库数据。
- 并发操作(对相同对象)由于不能隔离,引起:(1)丢失修改 R1R2W1W2;(2)读入“脏”数据 R1R2W2R1;(3)不可重复读 R1W1R2
- 并发调度:一组并发执行的事务T={T1,T2,...,Tn},各事务重要操作(读写)按时间排序的一个序列S,称T的一个调度。
- 串行调度:(就是一个个来,效率太低)
- 一致性调度:如果执行一个调度S,使数据库从一个一致性状态转入另一个一致性状态,称S是一个一致性调度。(注:数据库状态的一致性与业务规则有关!)
4.2 可串行化调度
- S是T的一个串行调度,S’是T的一个调度,若S’是与S有着相同一致性状态的一个调度,则称S’是一个可串行化调度。
4.3 冲突可串行化调度
- 冲突可串行化:某一并行调度S经过非冲突指令转换成串行调度,且与该串行调度的执行结果一致,则S是冲突可串行化的,
- 构造冲突可串行化调度,允许不同事务上的非冲突操作交换执行次序。
- 必定是一致性调度。
- 冲突可串行性不是可串行性的必要条件。即,可串行性不一定是冲突可串行性。存在其他可串行调度策略(非冲突可串行调度,如,视图可串行性调度)
- 冲突可串行化的判断:优先图
- 优先图由节点和有向弧两种元素构成,节点表示事务,有向弧表达事务先后次序。
- 事务的先后次序由冲突动作的先后次序决定。
- 成环表示不可串行化调度
第五讲 基于封锁的并发控制机制
5.1 锁的概念及封锁的原理
- 锁的基本模式:共享锁(Shared--S锁);排他锁(Exclusive--X锁)
- 锁的调度策略(相容矩阵):S与S相容;S与T,T与T不相容
- 加锁不当
- 死锁现象:两个事务互相等待数据
- 饿死现象:通过对等待的事务赋予优先权解决。
5.2 两阶段锁协议
- 所有事务分两个阶段提出加锁和解锁请求:
- 增长阶段(事务可以获得锁,但不能解锁)
- 缩减阶段(事务解锁,但不能获得锁)
- 遵循两阶段协议的并发控制算法产生的调度是冲突可串行调度。解决加锁不当,但仍然存在死锁现象,级联回滚可能发生。
- 严格两阶段协议:要求事务提交之前不得释放X锁,解决级联回滚。
- 强两阶段锁协议:要求事务提交之前不得释放任何锁(S和X锁),即这个阶段为强制串行调度,可以解决死锁问题。
- 锁转换机制:在写的时候,将S锁转换成X锁,写完后再降为S锁。提高并行能力。
5.3 多粒度锁及意向锁
- 多粒度树
- 多粒度加锁的特点:显示加锁(每个节点可以单独加锁);隐式加锁(对当前节点加锁会导致隐式地对全部后代节点加上同类型的锁)
- 检查锁冲突时,必须检查祖先、后代节点。
- 意向锁:一个事务对一个数据对象显示加锁之前,必须对它的全部祖先节点加意向锁。如果一个节点有意向锁,则后代节点必有被显式加锁。
- 意向锁分类:IS锁,IX锁,SIX锁(Share Intent Exclusive Lock 同时加S锁和IX锁)。
- 可串行性多粒度锁协议:
- 必须遵守锁类型的相容性矩阵。
- 根节点必须首先加锁。
- 任何事物必须遵守两阶段锁协议。
- 任何事物加锁都必须按从根到叶子顺序进行。
- 任何事物开锁都必须按从叶子到根顺序进行。
- 多粒度锁协议优点:增加并行性,减少锁开销。
- 多粒度锁协议应用:只存取几个数据项的短事务;由整个文件或一组文件形成报表的长事务
- 封锁机制的实现由锁管理器执行,锁管理器通过维护锁表控制加锁机制。
5.4 死锁的处理
- 死锁:两个或两个以上事务处于等待状态,每个事务都在等待其他另一个事务释放资源,导致事务无法执行。
- 处理方法:
- 引入死锁预防协议,使系统不进入死锁状态:通过对加锁请求进行排序,一事务开始前要锁定所有的数据项。
- 允许系统进入死锁状态,引入死锁检测和死锁恢复机制
- 死锁预防:
- 抢占与事务回滚技术:每一个事务赋予一个时间戳。若一个事务回滚,则当重启该事务时,必须保持原时间戳。然后采用 wait-die 和 wound-wait
- 基于超时的机制:事先给出事务的等待时间,超时即回滚。
- 死锁的检验:等待图。系统周期对等待图进行环搜索,以检测有无死锁。周期的长短受死锁发生的频率以及受影响事务的数目两个因素有关。
- 从死锁中恢复:选择事务回滚。选择代价最小的事务--回滚事务--防止饿死,将回滚次数考虑在代价中--基于锁的协议开销较大,并发提升有限度。
第六讲 并发控制的其他机制
6.1 基于时间戳的调度
- 时间戳:数据库系统赋予事务的唯一时间标记,标记事务开始执行。(系统时钟值或逻辑计数值)
- 时间戳基本原理:事务的时间戳决定串行化顺序,如果TS(Ti)<TS(Tj),则系统必须保证产生的调度等价于Ti,Tj串行调度。
- 排序协议:
- 若T执行读操作read(Q), 如TS(T)<W(Q) 则T回退,如TS(T)>=W(Q)则更新R(Q)=max()
- 若T执行写操作write(Q),如TS(T)<R(Q)则T回退,如TS(T)<W(Q)则T回退,否则更新W(Q)
- 被回退的事务系统重新赋予时间戳,重新启动。
- Thomas写规则(提高并行性,忽略过时的写操作)
6.2 基于有效性检验的调度
- 与前两种预防型策略不同,本策略为诊治型。
- 协议:将事务生命周期分成三个阶段:读阶段(局部变量更新);有效性检查阶段(判断不违反可串行性);写阶段。必须顺序执行。
- 协议中的标志点:Start(T), Validation(T), Finish(T), RS(T)读数据项的集合, WS(T)写数据项的集合
- 利用完成有效性检查的时间--Validation(T)的值--作为事务的时间戳,按该时间戳排序决定可串行化顺序
- 确认事务有效性时可能发生的错误:

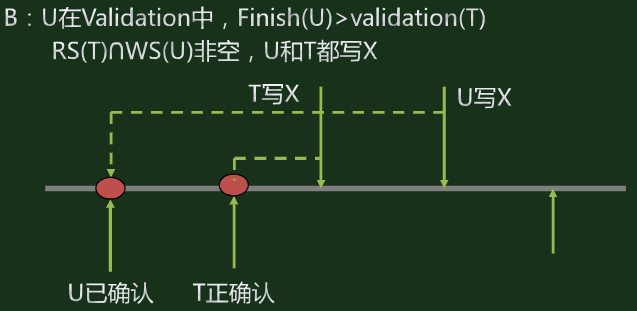
- 有效性检验规则:
对于经过有效性确认,且在T开始前还没有完成的事务Ti,如果满足以下条件之一,则Ti和T是可串行化的
Finish(Ti) < Start(T)
WS(Ti) & RS(T)==None and Finish(Ti)<Validation(T)
WS(Ti) & RS(T)==None and WS(Ti) & WS(T)==None and Validation(Ti)<Validation(T)
- 自动预防级联回滚,但是存在长事务被饿死。
- 数据库系统隔离性级别的控制:严格的隔离性实现机制本身带来许多问题,同时也降低系统的吞吐量。因此需要系统能根据应用要求灵活设置隔离级别。serializable, repeatable read, read committed, read uncommitted
第七讲 分布式数据库基本概念
7.1 分布式数据库的产生及定义
- 一个的地方需要管理另一个地方的数据库
- 第一个分布式数据库系统SDD-1
- porel系统, R*, system R, Ingres, SIRIUS-DELTA
- 1987年C.J Date提出了完全的,真正的分布式DBS应遵循的12条规则
- 本地自治性
- 不依赖于中心站点
- 可连续操作
- 位置独立性
- 数据分片独立性
- 数据复制独立性
- 分布式查询独立性
- 分布式事务管理
- 硬件独立性
- 操作系统独立性
- 网络独立性
- DBMS独立性(Database Management System)
- 定义:分布式数据库是一个数据集合,这些数据分布在由计算机网络连接起来的若干节点上,每个节点可以管理本地的数据应用,也可以参与全局数据应用。同时这些数据在逻辑上形成一个整体,由统一的数据库管理系统进行管理。DDBMS
- 站点:计算机连接的一个逻辑单位
- 本地(局部)用户、本地应用:一个用户或应用只访问他所注册的那个站点。
- 全局用户、全局应用:一个用户访问涉及两个或两个以上的站点中的数据。
- 全局数据库GDB,局部数据库LDB
- 基本特点:
- 结构特点:物理分布,逻辑相关
- 应用特点:站点自治
- 数据分布透明性:数据的物理独立性内容更丰富
- 集中与自治兼备的数据库系统控制机制,实现两个层次的数据共享:局部/全局数据共享。
- 增加数据冗余度:提高系统可靠性、可用性和系统性能
- 事务管理的分布性:分布环境下,维护事务的原子性、一致性、隔离性和持久性。
- 分类:
- 同构型(数据模型相同),同质同构,异质同构;异构型(数据模型不同)
- 按全局控制系统类型:全局控制集中型(中心站点协调);全局控制分散型;全局控制可变型(主从)
7.2 分布式数据库系统的模式结构与功能

除了具有集中式DBMS具有的功能外,还附加如下功能:数据追踪;分布式查询处理的能力;分布式事务管理的能力;复制数据的能力;安全性;分布式目录管理
7.3 分布式数据库系统中存在的技术问题
设计(全局模式的设计, 数据分片,分布);查询处理(全局查询的分解锁定);事务管理及并发控制;可靠性(结构有关);异构数据库的连接;安全性(数据、网络);目录管理
7.4 Appendix
- 习题:
分布式数据库系统从结构上来说可以通过互联网分布于不同的地理位置,数据也因此分布于不同的地理位置,但从逻辑上来看,整个系统只拥有一个逻辑模式。 (正确)
对于分布式数据库系统的各个站点,都有一个比较完整的数据库系统,这些系统使用的DBMS必须相同。 (错误)
分布式数据库系统能够实现两层数据共享:全局数据共享和局部数据共享。 (正确)
通过增加数据的冗余性,可以提高分布式数据库系统的性能。(错误?)
第八讲 分布式数据库的设计
8.1 分布式数据库的设计方法、内容和目标
根据设计是基于现存的数据系统还是构造一个全新的数据库系统,有两种方法创建分布式数据库:
组合法:基于现有系统,建立一个协调管理系统(采用自底向上的方式构建
重构法:创建全新的数据库系统,采用自顶向下的方式构建设计内容:需求分析(数据需求,应用需求),全局模式设计、局部数据库设计、数据分片设计、片段位置分配设计
- 目标:
- 确保数据库数据和应用具有最大程度的本地性
- 分布式数据的可用性和可靠性
- 工作负荷分布
- 存储的能力和费用
8.2 自顶向下方法构建数据库
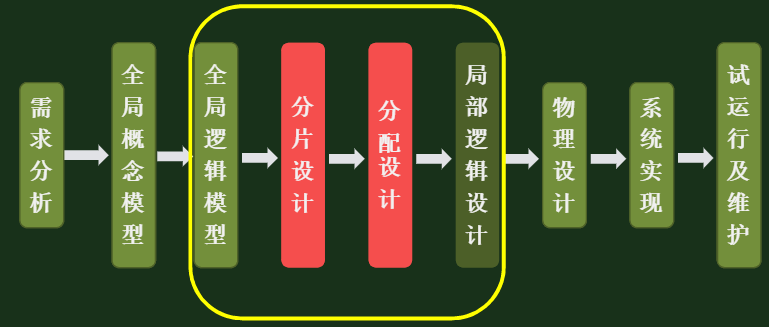
8.3 数据的分片和分布设计
- 片段:分布式数据库系统中,某一站点上存储的数据集合
- 分片设计的目的:产生全局数据的一个合理的划分,从而使每个站点只获得它所需要的数据,最大可能保证应用的本地性
- 分片应遵循的一般规则:设R={R1, R2, ..., Rn}
- 完整性
- 可重构性:
- 不相交性:片段相交为空或主码属性
- 分片基本类型和方法:
- 水平分片:全关系选择操作,把具有相同性质的元组进行分组,构成若干不相交子集。(初级分片:以自身属性分组;导出分片:用其他关系的属性对某一全关系进行分组)
- 垂直分片:利用投影操作把全关系的属性分成若干组,目标是把频繁使用的属性聚集在一起,且各片段只在键属性下重叠。
- 混合分片
- 分配设计:
- 非冗余分配:一个片段映射到一个站点
- 冗余分配:一个片段映射到多个站点
- 非冗余“最佳适应”分配法:把片段映射到最大访问次数(最需要)的站点上。
- 冗余分配比较复杂:所有站点得益法(宏观利益最大,选择一组站点进行分配,大于从其他站点对Ri实施更新代价);附加复制法(从获得片段Ri最大益处站点开始分配,对各站点依次附加片段Ri,直到系统无明显效益增加)。
- 总结:片段和分配设计的参数,来自应用需求(频率表,划分表,极化表)
- 频率表:各站点每一应用激活次数
- 划分表:各实体的潜在水平分片规则
- 极化表:给定站点发出一给定应用访问一给定片段的概率
8.4 分布式数据库设计实例
最频繁的20%的应用,覆盖80%的数据访问。
详见视频实例。
第九讲 分布式数据库查询机制
要点:理解分布式数据库查询优化步骤,并与集中式数据库查询优化比较;理解利用半连接算法实现直接连接运算的全局查询优化方法特点,半连接算法和直接连接算法的代价比较。
9.1 分布式查询处理的步骤和代价
- 步骤:
- 查询分析:局部查询则处理后结束
- 查询分解:把全局查询或远程查询转换成定义在全局关系上的关系代数表达式,并优化该表达式。
- 查询本地化:把全局关系的查询,转化为对片段的局部查询
- 全局查询优化:找出对各个片段局部查询结果之间的最佳操作次序,使得代价最小。其重点在连接运算、并运算的优化。
- 局部优化:由确定的片段所在站点执行
- 代价估算:QC= I/O代价 + 通信代价(传输次数,每次传输延迟时间+每次传输数据量/传输速率)
9.2 基于等价变换的查询优化
- 分布式查询优化的重要性(通信代价大)
- 基于关系代数等价变换的查询优化
- 从全局查询到片段查询的转换;
- 优化片段查询树:水平分片和垂直分片
9.3 基于半连接算法的查询优化
- 半连接运算:由投影和连接操作导出的一种关系代数操作。(R与S在R.A=S.B上的半连接运算,即R与S的直接连接运算后,做R的投影,等价于先做S的投影B运算,再做与R的直接连接运算;半连接运算不具有交换性)
- R与S的自然连接运算 = (R与S的半连接运算结果)与S的直接连接运算 = (S与R的半连接运算结果)与R的直接连接运算
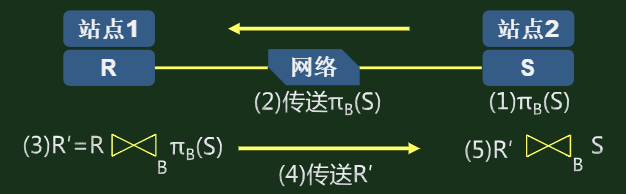
- 总代价:两次半连接操作的代价 + 通讯速率 * (半连接操作结果1 + 半连接操作结果2)
- 两个关系进行连接操作之前,去掉无用的元组,减少了数据处理量。
选择半连接运算实现连接运算的原则:经半连接操作产生少量元组。(相比直接连接运算,直接连接运算只传递一次全部关系,并只做一次连接操作)
策略:计算各种半连接运算的代价;计算直接连接运算的代价;比较选出最优方案
9.4 基于直接连接算法的查询优化
利用站点依赖信息的连接算法
- 站点依赖:设Ri, Rj, Si, Sj分别表示关系R和S在站点i,j的A属性上的取值。若Ri & Sj == None 则称关系R和S在属性A上站点依赖。
- 性质:若关系R和S在属性A上站点依赖,则:

- 站点依赖的传递律:如果R和S在属性A上站点依赖,其B包含A,则R和S在属性B上站点依赖
- 站点依赖的结合律:如果R和S在属性A上站点依赖,S和T在属性B上站点依赖,则 R--S--T = U(Ri--Si--Ti)
- 优点:无数据传送;可进行并行计算;可利用本地索引
分片和复制算法
当查询不能再无数据传递方式下处理,可采用分片和复制算法
- 原理:选择一组站点,将查询中的某一个关系的所有片段分布到这些站点上,然后把查询中的其余关系复制到每一个选定的站点上。(冗余分配)
- 优点:可进行并行计算;在一定程度上课利用本地索引。
- 策略:从假定某一关系分片,其余关系复制,计算代价,然后再选择另一关系为分片,最后从中选择代价最小的方案。
第十讲 分布式数据库的事务管理及恢复机制
10.1 分布式事务概述
- 全局事务:分布式数据库的事务。一个全局事务在执行时分解为由若干与相应站点有关的操作序列组成的“子事务”。
- 元素:Begin Transaction; T1; T2; ... ; Tn; Commit/Abort(Rollback)
- 特点:(原子性、隔离性、一致性、持久性)、系统效率、系统可用性->分布式事务既不能影响本站点上事务的执行,也不能影响其他站点上事务的执行。
- 分布式事务代理执行机制:

# 全局应用事务 --> 转成代理
read(@AMOUNT, @FROM_ACC, @TO_ACC);
begin transaction
select BALANCE into @FROM_AMOUNT
from ACCOUNT_TABLE
where ACCOUNT_NO = @FROM_ACC;
if @FROM_AMOUNT - @AMOUNT < 0
then abort
else begin
update ACCOUNT_TABLE
set BALANCE = BALANCE - @AMOUNT
where ACCOUNT_NO = @FROM_ACC;
update ACCOUNT_TABLE
set BALANCE = BALANCE + @AMOUNT
where ACCOUNT_NO = @TO_ACC;
commit
end# ROOT_AGENT
read(@AMOUNT, @FROM_ACC, @TO_ACC);
begin transaction
select BALANCE into @FROM_AMOUNT
from ACCOUNT_TABLE
where ACCOUNT_NO = @FROM_ACC;
if @FROM_AMOUNT - @AMOUNT < 0
then abort
else begin
update ACCOUNT_TABLE
set BALANCE = BALANCE - @AMOUNT
where ACCOUNT_NO = @FROM_ACC;
>>>>>>>>>>>>>>>>>>>
creat AGENT
send to AGENT(@AMOUNT, @TO_ACC);
waitting
commit/abort
<<<<<<<<<<<<<<<<<<<
end# AGENT
begin transaction
receive from ROOT_AGENT(@AMOUNT, @TO_ACC);
update ACCOUNT_TABLE
set BALANCE = BALANCE + @AMOUNT
where ACCOUNT_NO = @TO_ACC;
send to ROOT_AGENT('SUCCESS' / 'FAIL')
waitting
commit/abort
end10.2 分布式事务的两阶段提交协议
2-PC:Two-Phase Commitment Protocal
- 执行过程:
1)表决阶段:对当前事务形成一个决定;- 协调者:开始;向各参与者发出准备命令;等待;
每一个参与者:接收准备消息;检查子事务确定是否提交
case 1 可以提交子事务:参与者写“就绪”日志,向协调者发“建议提交”,参与者进入“就绪”状态
case 2 不可以提交子事务:参与者写“撤销”日志,向协调者发“建议撤销”,参与者进入“撤销”状态协调者接收到所有参与者回答后,做出决定(一票否决制)
case 1 所有参与者建议提交,协调者写提交日志,发出“全局提交”消息,进入提交状态。
case 2 一票否决,协调者写撤销日志,发出“全局撤销”消息,参与者进入撤销状态。
2)执行阶段- 对每一个处于“就绪”状态的参与者:根据全局事务处理指令,撤销或提交子事务,发出“确认”收到全局事务处理指令消息,进入“撤销”或“提交”状态。
协调者:写“结束事务”日志。

- 特点:
- 参与者有权单方面撤销事务
- 参与者做出“建议提交”或“建议撤销”决定后,不能反悔
- 处于“就绪”状态的参与者可能进入提交状态,或撤销状态
- 协调者和参与者可能进入互相等待状态。【存在的问题】
10.3 分布式并发控制概述
- 定义:与集中式并发控制从原理上一致;更复杂;集中式并发控制的一种扩展
- 目的:为并发执行的全局事务,产生一个可串行化调度。
局部调度:每个站点上的调度称为局部调度。
全局调度:数据库系统全局事务的调度。
全局调度的可行性,则局部调度可串行性;反之不成立 - 全局调度的冲突可串行化应满足
- 条件1:单副本控制协议
每一个局部变量是冲突可串行化的
任意两个冲突操作在它们同时出现的各个局部调度中,必须有相同的执行顺序。 - 条件2:读一个写全部
- 条件1:单副本控制协议
- 并发控制法:
- 集中式加锁法:网络中某一个站点被指定为主站点,用于存放整个分布式数据库的加锁表,负责整个系统事务的加锁。
- 主副本加锁法:每个数据对象指定一个主副本,不同数据对象的主副本放在不同站点上。算法:主副本加锁;执行更新操作;开锁
- 分布式加锁算法:锁的管理由各个站点调度器参与、协调,本地调度器负责本站数据加锁。算法:对全部副本加锁;执行更新操作;开锁。
10.4 并发控制的加锁机制
- 加锁准则:
遵守锁的相容性规则
遵守两段锁协议
持有X锁的事务,必须到结束事务才能开锁
读,锁一个;写,锁全部(ROWA协议) - 死锁管理
- 全局死锁:分布式数据库中,涉及多个站点的死锁称为全局死锁。
- 全局等待图 GWFG:存在环?
- 死锁的检测:
A 集中式死锁检测法
指定某站点上的锁管理器作为全局死锁检测器
其余站点周期性地向全局死锁检测器发送LWFG
全局死锁检测器产生GWFG,并检测有无回路
B 分布式死锁检测法
每个站点都有死锁检测器,负责检测本地可能的死锁
每个站点按照一定规则,向相关站点发送潜在的死锁回路图 - 死锁的解决
原则:撤销并恢复代价最小的事务
撤销并恢复年轻的事务
撤销并恢复站东资源较少的事务
撤销并恢复具有最短运行时间的事务
10.5 并发控制的时标技术
- 时标:唯一识别一个事务,并用于对事务进行排序的标识符。
构成:本地计数器值,站点标识符
创建:一个事务Ti初始化时,事务管理器给该事务分配一个时标ts(Ti)
排序原则:已知Qi和Qj是分别属于事务Ti和Tj冲突操作。若ts(Ti)<ts(Tj),则Qi在Qj之前执行。 - 基本时标法:(与集中式的一致)
- 保守时标法:
- 特点:采用缓冲区缓冲“年轻操作”,以便尽量消除“拒绝操作”,避免事务重新启动。
每个事务只在一个站点执行。不激活远程程序,只能向远程站点发出读写操作请求。
每个站点必须按照时标时间的顺序发送读写数据的请求。对于每个事务的更新操作,必须做到对同一数据对象先读后写。
每个站点都开辟一个缓冲区,用于保存其他站点发来的读写操作。 - 执行过程:一旦某个站点上的各个缓冲区队列都不空,即,每个站点至少向该站点发送一个读和写,就停止接收,转入处理缓冲区队列上的操作。
- 特点:采用缓冲区缓冲“年轻操作”,以便尽量消除“拒绝操作”,避免事务重新启动。
乐观方法(类似有效性检验)
- 习题:
- 两阶段提交协议中,所有参与者与协调者均需要写日志文件。(错误)
- 一个分布式查询可能包含以下哪种类型:远程查询,全局查询。
- 分片的目的是把全局逻辑模型按站点应用的需求划分成若干个数据片段,以保证后面应用时可以让某个站点拥有它最需要的数据片段。(正确)