| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
|---|---|---|---|---|---|---|
| node01 | √ | √ | √ | |||
| node02 | √ | * | * | √ | √ | |
| node03 | * | * | √ | |||
| node04 | * | * |
这里有些原则:各个进程(角色)放在一台主机上,本地化传输方便,减少了网络IO
但是一台节点上又会加重该节点的负载(cpu,内存,磁盘等)
高可用解决了NN单点故障问题,提高了可用性
有时候需要度量可用性与一致性的权衡问题:关于JN需要半数以上一致,NN就可以继续写入.首先明确一个概念:防止发生脑裂的最少需要同步的节点数叫做势力范围(恒为奇数),为了发生脑裂就得半数以上都同步才行,如果不可抗拒因素导致节点网络通讯中断被分裂为2个独立的通信节点群,那么少数的就会自杀,即使少数的是对的也会自杀,为了防止这种脑裂的事情发生所以需要同步的节点是半数以上(大于等于势力范围)。这样就是说并不需要等待完全同步,NN再继续写入,只需要写入的节点数大于等于势力范围即可,提高了可用性。
关于SSH免密比较特殊的是:需要NN2的公钥给的主机和NN1配置一样,因为standby和active能够随时转换,同理hosts文件也需要一样。
(这里有个主备切换的过程:当active坏了或者active的zkfc坏了,zookeeper都会通过zkfc的心跳接收到信息,从而通过选举找到下一个需要变为active的节点,通知到该节点的zkfc,然后先去连接那个坏的active节点,如果他是active(这种情况是因为原先的zkfc坏了,而NN没坏,但是还是会被zookeeper更换状态的),那就将其置为standby,然后将zkfc自己下面的NN置为active)
借鉴的一些说法:
HA即为High Availability,用于解决NameNode单点故障问题,该特性通过热备的方式为主NameNode提供一个备用者,一旦主NameNode出现故障,可以迅速切换至备NameNode,从而实现对外提供更稳定的服务
SecondaryNameNode(冷备):只是阶段性的合并edits和fsimage。当NN失效的时候,SNN无法立刻提供服务,甚至无法保证数据完整性:在SNN进行合并时,如果NN数据丢失的话,SNN也无法感知到,从而丢失部分操作
HDFS HA提供两个NameNode,一个处于active状态,对外提供服务;另一个处于standby状态,同步元数据(在内存中)。当active状态的NameNode挂掉时,standby转为active。HA 是通过代理对外提供服务,客户端请求由代理接收然后转发到active状态的NN
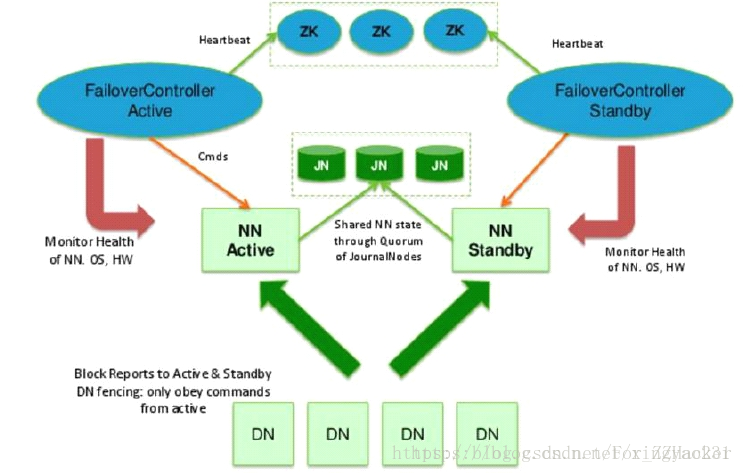
为了能够实时同步Active和Standby两个NameNode的元数据信息,我们将元数据状态(fsimage)和对元数据的操作(editlog)存放到 JN 集群中,standby状态的NN实时从JN中读取数据并执行重演,同时所有DataNode向两个NameNode都发送心跳,从而保证两个NameNode状态的同步
JNN集群遵从半数以上的势力划分,所以其节点数量总为奇数。active-NN向JNN写入editlog时,当半数以上的JNN节点存储成功则停止写入,其它JNN节点从这些已写入的节点copy editlog。正常情况下集群内各节点间保持通信,standby-NN可以从任意节点上读取到正确的数据,若是因为不可抗力而导致集群分裂(集群内节点通讯中断),此时还可以相互通信的节点组成集群小势力,那么规定势力范围(集群内节点数量)小于半数的集群提供的数据视为无效。例如现在有3个JNN,分裂成了 1+1 和 1 两股势力,那么此时即使 1 中的数据是正确的也会被视为无效,standby得知其节点数小于半数时会转而去 1+1 中读取数据
接下来,如果active状态的NN挂掉了,我们就将另一台切换为active状态。那么问题来了,active状态的NN什么时候会挂掉呢?难道我们要一直盯着服务器看吗?这当然是不可能的。这里我们用到了zookeeper作为一个管理者代替我们进行监视。当然管理员也有管理员的脾气,所以监视这种累人的工作zookeeper就交给了FailoverController。于是FailoverController就开始了兢兢业业的工作,认真的监视着两个NN,并定时向zookeeper汇报NN的状态信息。如果active的NN挂掉了,FailoverController就汇报情况给zookeeper,得知情况后的zookeeper就通知监视另一个NN的FailoverController将standby的NN转为active(如果有多个standby的NN则由zookeeper选举出一个转为active)。
那么这里有一个问题就是如果监视active状态NN的FailoverController不幸挂掉了,那么一定时间内没有得到来自FailoverController心跳的zookeeper无法得知当前active状态的NN究竟是否存活,就会认为其已经挂掉,会去选举启动一个新的active-NN,那么这时可能就会同时存在两台active-NN,这时对外提供服务的代理可能就感觉不太好了,因为它无法确定要将请求转发到哪一台active-NN上。所以当FailoverController启动新的active-NN的同时也会将原来为active状态的NN置为standby而不管其是否已经挂掉,确保同一时间avtive状态的NN只有一台
具体的一些配置:
- 高可用性完全分布式中需要先配置zookeeper,再启动(zkfc进程的格式化需要依赖这个)
关于zookeeper,没有在hadoop安装包中
下载zookeeper安装包并解压,这里以 zookeeper-3.4.12 为例。zookeeper是运行在 node02,node03 和 node04 上的,这里我们先将安装包放在node02上进行配置,配置结束后发送到 node03 和 node04
将 zookeeper 安装包下 conf 目录下的 zoo_simple.cfg 修改为 zoo.cfg
[root@node02 conf]# mv zoo_simple.cfg zoo.cfg
修改 zoo.cfg 文件,修改 dataDir 的位置(随意修改)并添加服务配置,其中1、2、3是zookeeper的服务编号,后面是对应服务器的主机名
dataDir=/var/abc/zookeeper
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
创建你刚才声明 dataDir的目录,并在下面 创建一个myid文件,在这个文件中只写上当前节点所对应的服务ID号。当前为 node02 节点,由上配置 server.1=node02:2888:3888 确定服务ID号为 1
[root@node02 ~]# cat /var/zgl/zookeeper/myid
将配置好的zookeeper安装包发送到node03 node04
[root@node02 software]# scp -r zookeeper-3.4.12 root@node03:/opt/software/
[root@node02 software]# scp -r zookeeper-3.4.12 root@node04:/opt/software/
在node03,node04 上分别修改 myid 中的 ID号。node03–>2,node04–>3
在 node02 node03 node04 上配置zookeeper的环境变量,这里配置到用户环境中,在 ~/.bashrc 文件中添加如下
export PATH=$PATH:/opt/software/zookeeper-3.4.12/bin
在 node02 node03 node04 上分别执行 zkServer.sh start 命令启动 zookeeper。
使用 jps 命令查看,如果 QuorumPeerMain 进程启动则配置成功
[root@node04 zgl]# jps
22035 QuorumPeerMain
23100 Jps
- 几个配置文件的配置
先在 node01 上进行配置,配置完成后发送到其他节点
修改 hdfs-site.xml 文件
<property>
<name>dfs.nameservices</name> <!-- 配置一个服务(集群名称) -->
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name> <!-- 提供服务的节点 -->
<value>nn1,nn2</value>
</property>
<!-- 配置两个NameNode的rpc协议的地址和端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<!-- 配置两个NameNode的http协议的地址和端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
<!-- 设置journalnade的位置信息 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<!-- journalnade保存数据用的目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/abj/hadoop/ha/jn</value>
</property>
<!-- 通过代理类来让客户端连接active的NameNode -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 通过远程登录,杀掉NameNode来保证只有一个active的NameNode(保证
已经设置了免密登录) -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置NameNode的自动切换的开关 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
修改core-site.xml 文件
<property>
<name>fs.defaultFS</name> <!-- HDFS文件默认地址前缀(简化实际访问时路径书写) -->
<value>hdfs://mycluster</value>
</property>
<!--配置三台zookeeper的位置信息 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
<!-- HDFS文件存储位置,实际上默认是引用该地址这里只是被引用了,所以该目录下有很多数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/abcd/hadoop/cluster</value>
</property>
修改slaves配置文件
配置DataNode节点,注意每行写一个
node02
node03
node04
修改hadoop-env.sh配置文件
#The java implementation to use.
export JAVA_HOME=/opt/zgl/jdk1.8.0_151
#在hadoop-env.sh 配置一条hadoop配置文件所在目录
export HADOOP_CONF_DIR=/opt/zgl/hadoop-2.6.5/etc/hadoop
刷新配置 source hadoop-env.sh
高可用性完全分布式的启动顺序:
1.zookeeper启动zkServer.sh start-》是zkfc进程格式化的前提
2.JN启动hadoop-daemon.sh start journalnode-》主要用于namenode格式化
3.ANN格式化hdfs namenode -format-》如何用到journalnode集群?一开始没有edits文件的(因为在完全分布式中NN的格式化只是创建了fsimage“文件”和edits“对象”,可以通过在格式化完成后在文件中寻找发现只有fsimage文件,但没有edits文件)??就是一些简单的连通,在集群启动的时候才会创建edits文件
4.ANN启动 hadoop-daemon.sh start namenode-》用于standbyNN的同步引导
5.SNN引导同步(不是启动)hdfs namenode -bootstrapStandby->需要同步2台name node之间的元数据。具体做法:从第一台NN拷贝元数据(fsimage)到放到另一台NN(磁盘中)(如果是格式化了那就没有了,所以这一步也不需要了),然后启动第一台的NameNode进程,再到另一台名称节点上做standby引导(将集群号之类基本信息同步过去)。重启动的时候内存中肯定已经没有了元数据等,这个同步引导的过程??就是将一些信息复制到SNN中磁盘中
6.格式化ZKFC(ZooKeeperFailoverContraller) hdfs zkfc -formatZK->依赖zookeeper的启动,不知是否依赖NN的格式化?NN启动??不依赖。仅仅依赖zookeeper启动
7.关闭hdfs的进程(zookeeper除外)stop-dfs.sh-》这里为何要关闭?为何要同时启动??其实这里没有硬性要求,主要是防止脑裂
8.启动start-dfs.sh
一些常用到的命令:
用命令查看namenode的状态(两台namenode,2个namenode节点的名字为nn1,nn2)
hdfs haadmin -getServiceState nn1
使用如下命令,将nn1强制切为active–>自动切换模式没用,手动模式可以用
hdfs haadmin -transitionToActive --forcemanual nn1
active与standby切换,kill namenode 此时zkfc(监控)和zookeeper(监控和选举)就会去自动切换,将另一个变为active ,你再去启动刚才关闭的namenode就会被置为standby hadoop-daemon.sh namenode 自动模式就会来实现主备切换
关于格式化的一些理解:
格式化操作:删除数据信息以及日志文件,生成一些参数文件
每一次format主节点namenode,dfs/name/current目录下的VERSION文件会产生新的clusterID、namespaceID。但是如果子节点的dfs/name/current仍存在,hadoop格式化时就不会重建该目录,因此形成子节点的clusterID、namespaceID与主节点(即namenode节点)的clusterID、namespaceID不一致。最终导致hadoop启动失败。
format:hdfs namenode -format,hdfs zkfc -formatZK
在执行hdfs namenode –format时仅创建了fsimage文件,并没有创建edits文件,但已经创建了相关对象。这一点也可以在执行完format后在本地文件系统中确认,目录中只有fsimage文件,但是可以理解为创建了