hbase版本 2.0.4 与hadoop兼容表
http://hbase.apache.org/book.html#hadoop
我的 hadoop版本是3.1
1.单机版hbase
1.1解压安装包
tar xf hbase-2.0.4-bin.tar.gz -C /opt/
1.2配置环境变量
编辑/etc/profile
export HBASE_HOME=/opt/hbase-2.0.4 export PATH=$PATH:$HBASE_HOME/bin
生效环境变量
source /etc/profile
1.3.配置hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64 export HBASE_MANAGES_ZK=false
1.4配置hbase-env.sh
<property> <name>hbase.rootdir</name> <value>file:///home/testuser/hbase</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/testuser/zookeeper</value> </property>
1.5启动hbase
start-hbase.sh
报错
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hbase-2.0.4/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.1.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See
http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
running master, logging to /opt/hbase-2.0.4/logs/hbase-root-master-node04.out
原因是有两个log4j的jar起了冲突,只需要删除其中一个
mv /opt/hadoop-3.1.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar /opt/hadoop-3.1.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar.bak
在hbase-env.sh 配置中默认使用的是hbase自带的zk实例,在完全分布式环境中需要改为false
注意:如果是下面配置是true,就关闭当前的zk实例。

进入hbase shell

2.高可用完全分布式部署
2.1节点角色分配
|
节点
|
namenode01
|
namenode02
|
zk
|
datanode
|
zkfc
|
journalnode
|
Hmaster
|
Hregionserver
|
|
node01
|
√
|
|
|
|
√
|
√
|
√
|
|
|
node02
|
|
√
|
√
|
√
|
√
|
√
|
√
|
√
|
|
node03
|
|
|
√
|
√
|
|
√
|
|
√
|
|
node04
|
|
|
√
|
√
|
|
|
|
√
|
2.2配置环境变量/etc/profile
全部节点配置,配置不要忘记 source一下
export HBASE_HOME=/opt/hbase-2.0.4 PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin
2.3配置hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64 export HBASE_MANAGES_ZK=false
2.3配置hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node02,node03,node04</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <name>hbase.master.maxclockskew</name> <value>150000</value> </property> </configuration>
2.4配置regionservers
[root@node01 conf]# cat regionservers node02 node03 node04
2.5配置backup-masters
(注意:这个配置文件默认没有,单独创建编辑)
[root@node01 conf]# cat backup-masters node02
2.6拷贝hdfs-site.xml
将hdfs-site.xml拷贝到hbase的配置目录
[root@node01 conf]# cp /opt/hadoop-3.1.1/etc/hadoop/hdfs-site.xml /opt/hbase-2.0.4/conf/
2.7分发hbase到其他节点
略。。。
2.8启动中出现的一些问题
根据日志 增加一些相应的配置。
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
hbase-site.xml增加配置
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
regionserver.HRegionServer: STOPPED: Unhandled: org.apache.hadoop.hbase.ClockOutOfSyncException: Server node02,16020,1548146100212 has been rejected; Reported time is too far out of sync with master. Time difference of 122815ms > max allowed of 30000ms
hbase-site.xml增加配置
<property>
<name>hbase.master.maxclockskew</name>
<value>150000</value>
</property>
2.9启动hbase集群
[root@node01 conf]# start-hbase.sh running master, logging to /opt/hbase-2.0.4/logs/hbase-root-master-node01.out node02: running regionserver, logging to /opt/hbase-2.0.4/bin/../logs/hbase-root-regionserver-node02.out node04: running regionserver, logging to /opt/hbase-2.0.4/bin/../logs/hbase-root-regionserver-node04.out node03: running regionserver, logging to /opt/hbase-2.0.4/bin/../logs/hbase-root-regionserver-node03.out node02: running master, logging to /opt/hbase-2.0.4/bin/../logs/hbase-root-master-node02.out
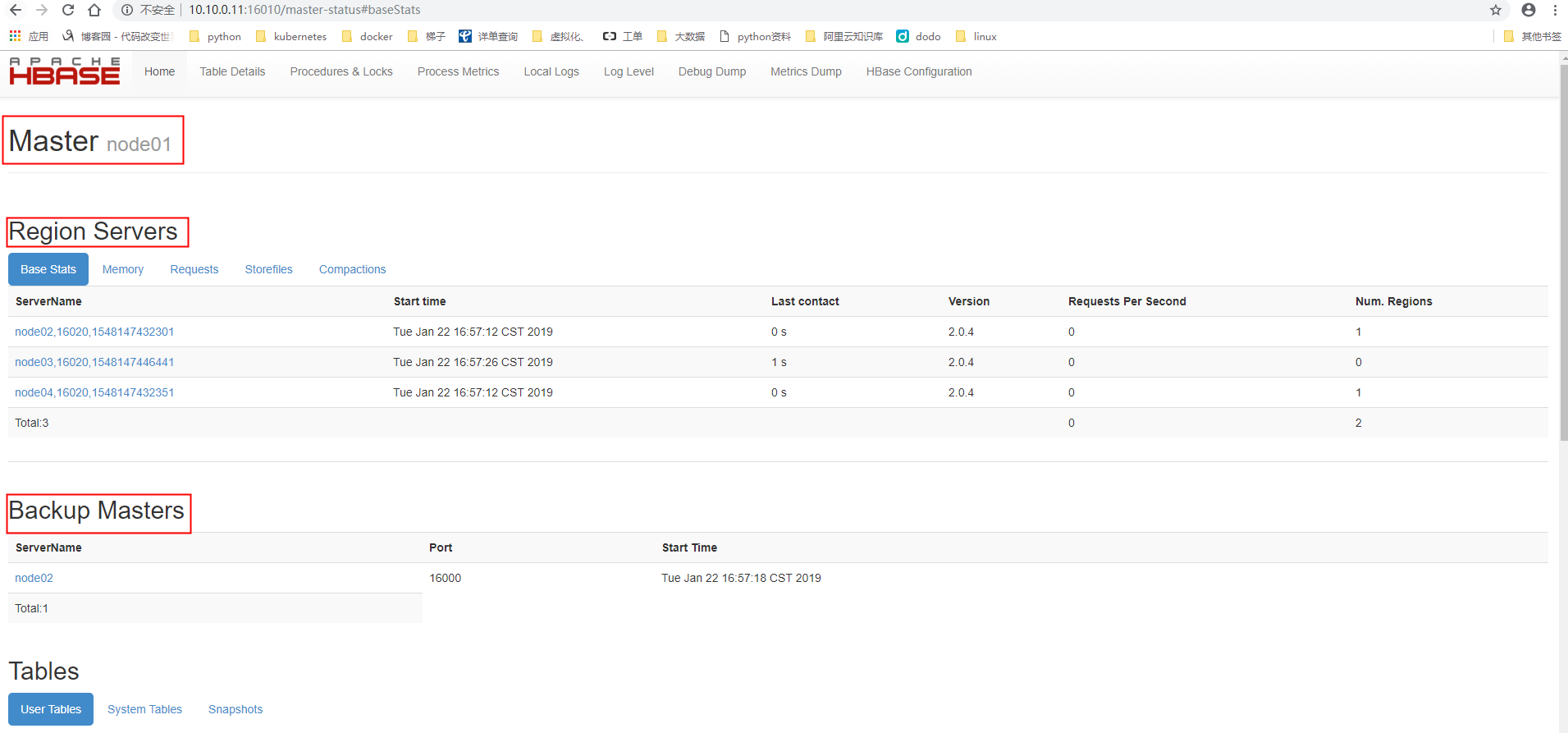
2.10验证
通过网页访问hbase
查看web portal使用端口16010

网页 node01:16010
符合预期
使用 hbase shell
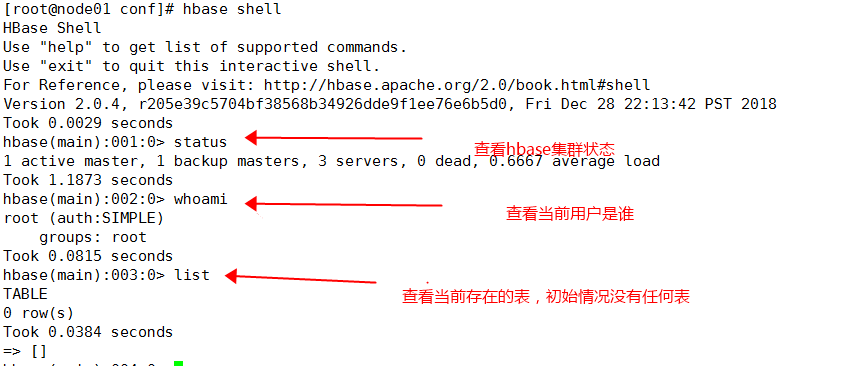
2.11 hbase shell 使用
创建test表,列族为 cf
hbase(main):004:0> create 'test','cf' Created table test Took 4.6111 seconds => Hbase::Table - test
向这个cf列族put 列名为name,值为 xiaoming的数据
hbase(main):005:0> put 'test','111','cf:name','xiaoming' Took 1.8724 seconds
当我们将数据塞进表里后不会立马写入到hdfs上,这是由于hbase的数据会暂存在内存中当内存使用达到一定阀值后会溢写到磁盘上。
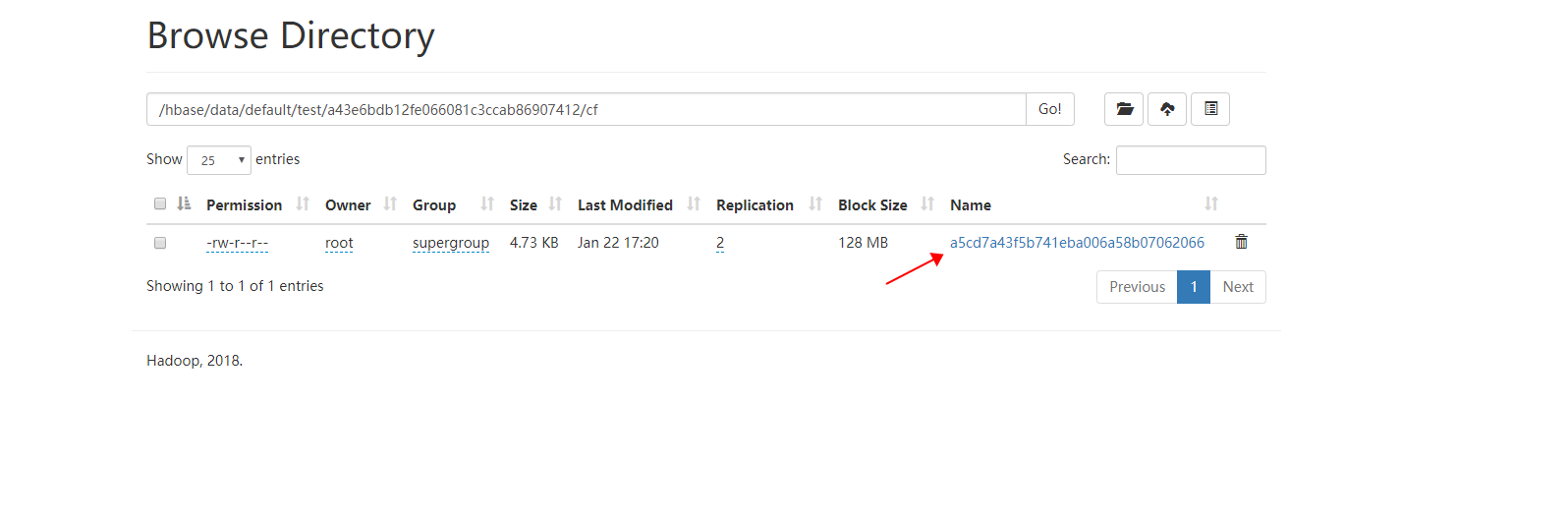
如果想让他立即写到磁盘需要使用flush 命令
hbase(main):007:0> flush 'test' Took 2.6511 seconds
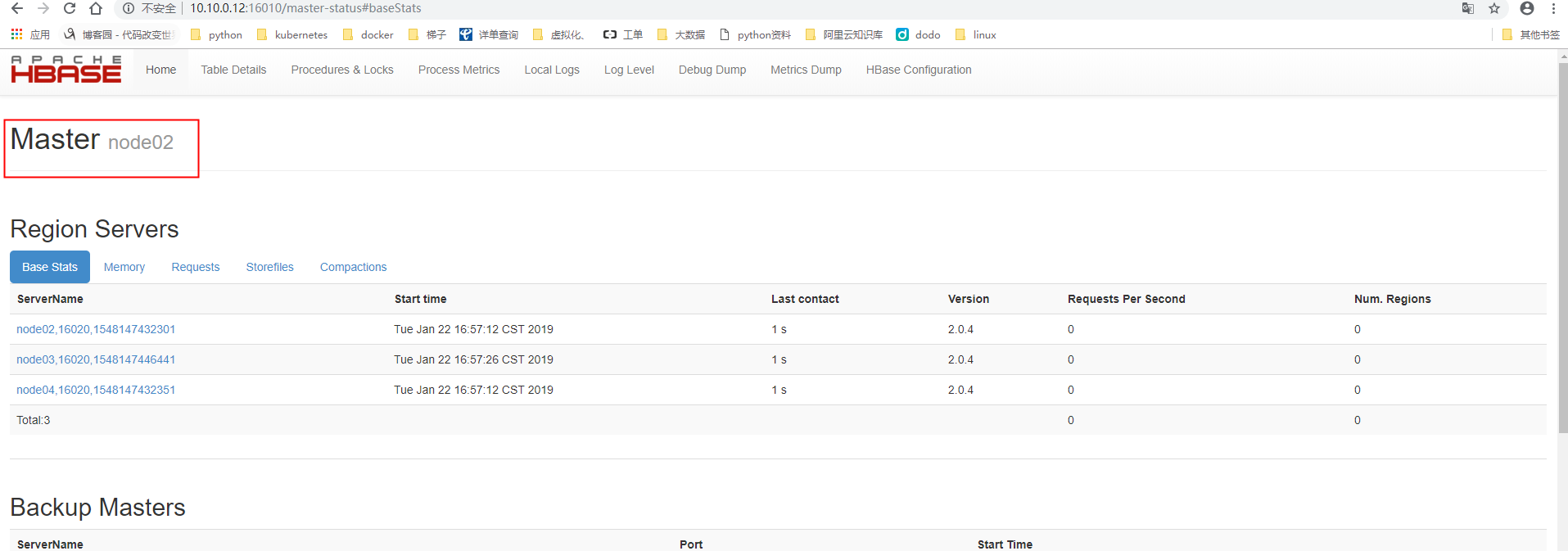
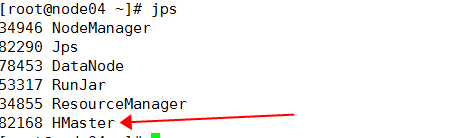
2.12验证高可用
手动kill node01上的Hmaster进程,看是master是否会切换到node02