一、HDFS-Hadoop分布式文件系统
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分

1、Client:就是客户端。
1)文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个128M的Block,然后进行存储。
2)与 NameNode 交互,获取文件的位置信息。
3)与 DataNode 交互,读取或者写入数据。
4)Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
5)Client 可以通过一些命令来访问 HDFS。
配置项:
hdfs-site.xml
dfs.blocksize 128M
dfs.relication 3
如:一个260M的文件 生成2个128M块和一个4M块,产生9条信息,占用磁盘空间260M*3
2、NameNode:就是 master,它是一个主管、管理者。
1)管理 HDFS 的名称空间,维护文件系统树,以两种文件永久保存在磁盘:命名空间镜像文件fsimage和编辑日志editlog
注:名称空间(文件名称、文件目录结构、文件属性(创建时间 权限 副本数)、文件对应那些数据块(分布在那些DataNode))
2)管理数据块(Block)映射信息
块映射blockmap, namenode不会持久化存储这种映射关系,DataNode会定时发送blockReport给namenode节点,以此namenode在内存中动态维护这种映射关系。
3)配置副本策略
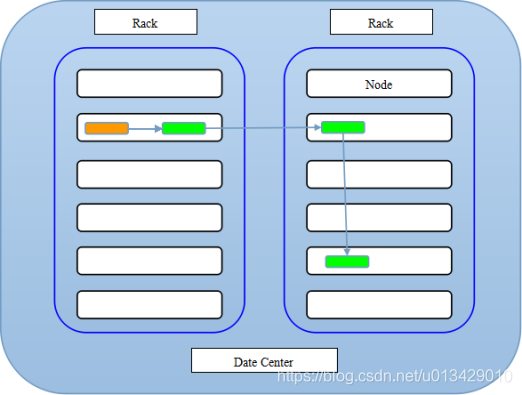
注:如果提交文件的节点就是datanode,那么就近原则,第一个快就存放在本节点
如果不是,就随机挑选一台磁盘不太慢的 cpu不太繁忙的节点上(该节点有namenode指定);
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
1)存储实际的数据块。
2)执行数据块的读/写操作。
3)每隔3秒发送一个心跳包到NameNode,每10次发送一个blockReport
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
1)辅助 NameNode,分担其工作量。
2)定期合并 fsimage和fsedits为新fsimage,并推送给NameNode。
3)在紧急情况下,可辅助恢复 NameNode。
多长时间备份一次fsimage和fsedits
hdfs-site.xml 生产中通常设置1800秒(半小时)
dfs.namenode.checkpoint.period 3600
fsimage:镜像文件 文件系统树
fsedits:操作日志 读写的操作记录
备份的流程:
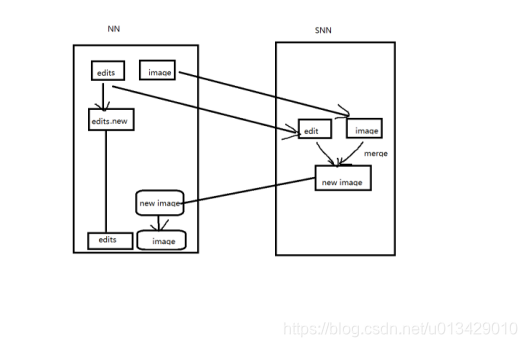
缺点:
假如备份时间为1:00 2:00 3:00 4:00 5:00
而在4:50的时候NameNode主节点挂了,此时备用NN还没有备份,会造成4:00~4:50之间的操作文件丢失
后边会介绍NameNode-HA,NameNode的高可用,热备份的效果
5、HDFS写流程
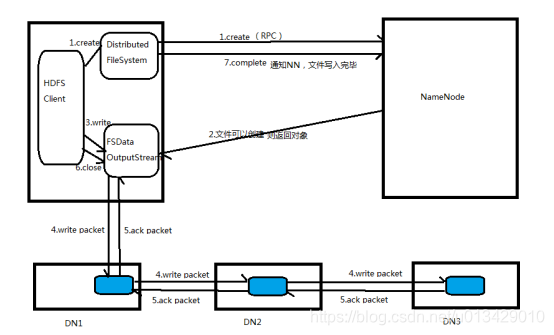
写流程:hdfs dfs -put a.txt /user/Hadoop/a.txt
当我们在HDFS Client上传文件时, client会调用DistributedFileSystem.create(path)的方法,与NameNode进行rpc通信,NameNode检查对应的path是否已经存在或者是否有权限创建,如果文件已经存在或者没有权限,那么就给client返回一个异常,流程结束;如果文件可以创建,则返回一个FSDataOutputStream对象,client调用FSDataOutputStream.write()方法向DataNode发送一个write packet(包含3副本块的)包,复制第一个块到第一个副本节点,然后第一个副本节点把块复制给第二个节点,最后第二个节点把块复制给第三个节点,当第三个节点收到块并写完之后会向第二个节点返回ack packet的包,当第二个节点向第一个节点返回ack packet,最终FSDataOutputStream收到ack后,client调用FSDataOutputStream的close关闭数据流,然后client调用DistributedFileSystem.complete()告知NameNode数据写完毕
5、HDFS读流程
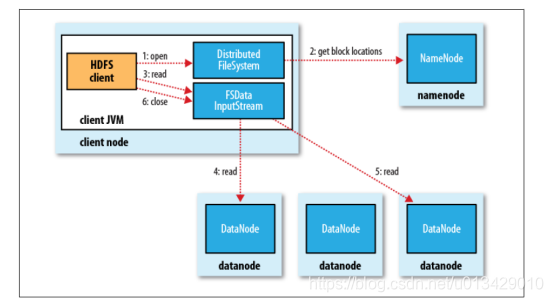
1.客户端通过调用FileSystem对象的open()来读取希望打开的文件。对于HDFS来说,这个对象是分布式文件系统的一个实例。
2.DistributedFileSystem通过RPC来调用namenode,以确定文件的开头部分的块位置。对于每一块,namenode返回具有该块副本的datanode地址。此外,这些datanode根据他们与client的距离来排序(根据网络集群的拓扑)。如果该client本身就是一个datanode,便从本地datanode中读取。DistributedFileSystem 返回一个FSDataInputStream对象给client读取数据,FSDataInputStream转而包装了一个DFSInputStream对象。
3.接着client对这个输入流调用read()。存储着文件开头部分块的数据节点地址的DFSInputStream随即与这些块最近的datanode相连接。
4.通过在数据流中反复调用read(),数据会从datanode返回client。
5.到达块的末端时,DFSInputStream会关闭与datanode间的联系,然后为下一个块找到最佳的datanode。client端只需要读取一个连续的流,这些对于client来说都是透明的。
二、Yarn
YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
YARN总体上仍然是master/slave结构,在整个资源管理框架中,resourcemanager为master,nodemanager是slave。Resourcemanager负责对各个nademanger上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
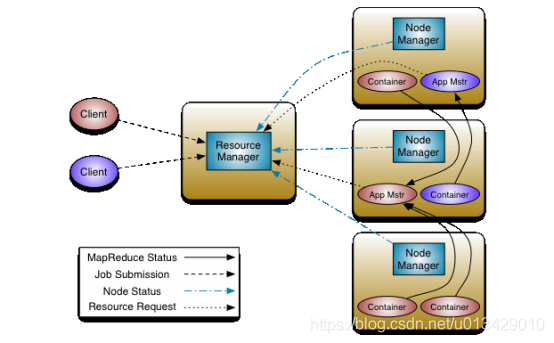
1. Yarn中提交任务流程以及各组件介绍
当我们在Client上提交程序时,ResourceManager会找到对应的NodeManager,同时启动一个ApplicationMaster,AM会和RM协调内部任务运行需要用到的资源,RM返回Container(容器包含内存、CPU以及IO的信息),AM进而把Container的资源分配给内部任务,并与NM通信来启动AM内的任务。同时监控任务状态,并且在任务执行失败的时候重新和RM协商资源用来重新启动任务。
在运行过程中,NodeManager会定时向RM汇报本节点资源使用情况,以及Container的运行状态(CPU和内存等资源)。
(1)ResourceManager:
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等(公平调度、计算调度)。
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
(2)ApplicationMaster:
用户提交的每个应用程序均包含一个AM。
与RM调度器协商以获取资源(用Container表示);
将得到的任务进一步分配给内部的任务(资源的二次分配);
与NM通信以启动/停止任务;
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
注:RM只负责监控AM,在AM运行失败时候启动它,RM并不负责AM内部任务的容错,这由AM来完成。
(3)NodeManager:
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
(4)Container:
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
2.Yarn的内存管理:
因为一个节点上内存会被若干个服务贡享,比如一部分给了yarn,一部分给了hdfs,一部分给了hbase、kafka、zookeeper等,yarn配置的只是自己可用的,配置
yarn-site.xml参数如下:
yarn.nodemanager.resource.memory-mb 12G #总的Container内存容量
yarn.scheduler.minimum-allocation-mb 2G #单个Container最小内存容量
yarn.scheduler.maximum-allocation-mb 12G #单个Container最大内存容量
可能出现的countainer个数是1-6个其中1,2,3,4,6个Container是可以充分利用配置的内存的
#是否启用一个线程检查每个任务使用的物理内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.nodemanager.pmem-check-enabled true
#是否启用一个线程检查每个任务使用的虚拟内存量,如果任务超出了分配值,则直接将其kill,默认是true。
yarn.nodemanager.vmem-check-enabled true
#任务使用1m物理内存最多可以使用虚拟内存量,默认是2.1
yarn.nodemanager.vmem-pmem-ratio 2.1
3.Yarn的CPU管理:
在YARN中有一个虚拟CPU的概念,1个物理CPU对应2个虚拟CPU,比如:
生产中8个core对应16个vcore
预留2个core,那么就剩余12个vcore
配置如下,单个任务能调用的最少和最多虚拟CPU:
yarn.nodemanager.resource.cpu-vcore 12
yarn.scheduler.minimum-allocation-vcore 1
yarn.scheduler.maximum-allocation-vcore 12
Yarn启动时的JVM配置:
vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
YRAN_OPTS=”$YARN_OPTS -Xms2048m -Xmx2048m”
三、Hadoop配置NameNode+ResourceManager高可用原理分析
关于NameNode高可靠需要配置的文件有core-site.xml和hdfs-site.xml
关于ResourceManager高可靠需要配置的文件有yarn-site.xml
逻辑结构:
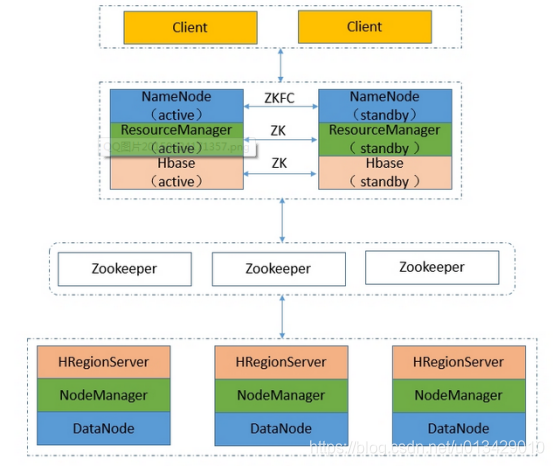
1、NameNode-HA工作原理:
在一个典型的HA集群中,最好有2台独立的机器的来配置NameNode角色,无论在任何时候,集群中只能有一个NameNode作为Active状态,而另一个是Standby状态,Active状态的NameNode负责集群中所有的客户端操作,这么设置的目的,其实HDFS底层的机制是有关系的,同一时刻一个文件,只允许一个写入方占用,如果出现多个,那么文件偏移量便会混乱,从而导致数据格式不可用,当然状态为Standby的NameNode这时候仅仅扮演一个Slave的角色,以便于在任何时候Active的NameNode挂掉时,能够第一时间,接替它的任务,成为主NameNode,达到一个热备份的效果,在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持从NameNode时时的与主NameNode的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode,当任何修改操作在主NameNode上执行时,它同时也会记录修改log到至少半数以上的JornalNode中,这时状态为Standby的NameNode监测到JournalNode里面的同步log发生变化了会读取JornalNode里面的修改log,然后同步到自己的的目录镜像树里面,当发生故障时,Active的NameNode挂掉后,Standby的NameNode会在它成为Active NameNode前,读取所有的JournalNode里面的修改日志,这样就能高可靠的保证与挂掉的NameNode的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
为了达到快速容错的掌握全局的目的,Standby角色也会接受来自DataNode角色汇报的块信息,前面只是介绍了NameNode容错的工作原理,下面介绍下,当引入Zookeeper之后,为啥可以NameNode-HA可以达到无人值守,自动切换的容错。
在主备切换上Zookeeper可以干的事:
(1)失败探测 在每个NameNode启动时,会在Zookeeper上注册一个持久化的节点,当这个NameNode宕机时,它的会话就会终止,Zookeeper发现之后,就会通知备用的NameNode,Hi,老兄,你该上岗了。
(2)选举机制, Zookeeper提供了一个简单的独占锁,获取Master的功能,如果那个NameNode发现自己得到这个锁,那就预示着,这个NameNode将被激活为Active状态
当然,实际工作中Hadoop提供了ZKFailoverController角色,在每个NameNode的节点上,简称zkfc,它的主要职责如下:
(1)健康监测,zkfc会周期性的向它监控的NameNode发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态
(2)会话管理, 如果NameNode是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NameNode挂掉时,
这个znode将会被删除,然后备用的NameNode,将会得到这把锁,升级为主NameNode,同时标记状态为Active,当宕机的NameNode,重新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NameNode。
(3)master选举,如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态。

具体的高可用配置将在后续《完全分布式Hadoop》系列文章中写出来,敬请期待!