LogisticRegression原理及算法
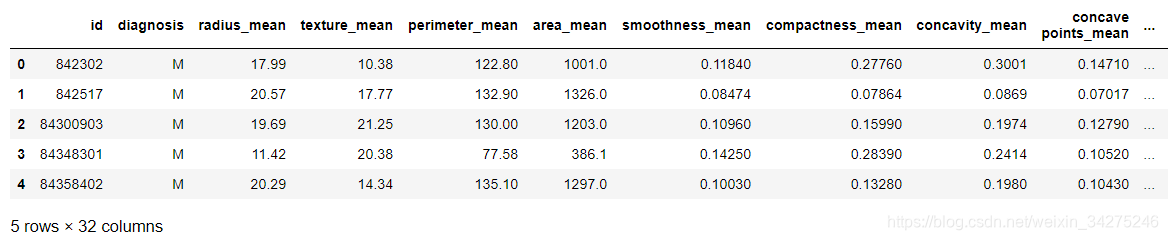
该数据共有569个样本,每个样本有11列不同的数值:第一列是检索的ID,中间9列是与肿瘤相关的医学特征,以及一列表征肿瘤类型的数值。所有9列用于表示肿瘤医学特质的数值均被量化为1-10之间的数字。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r'D:\machinelearningDatasets\BreastCancerLR\Breast cancer.csv')
data.head()
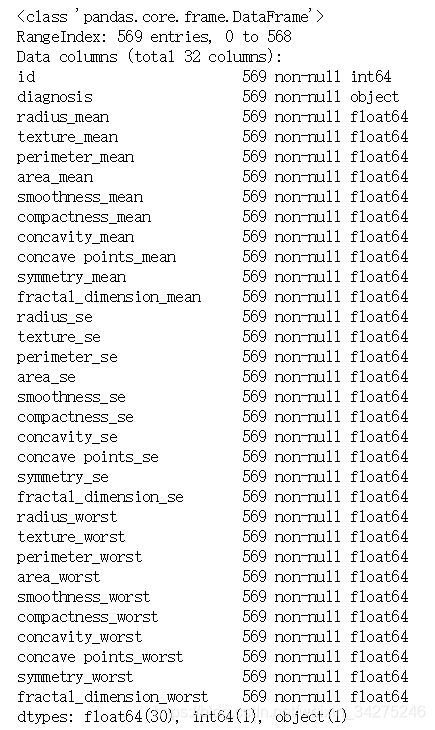
data.info()
#data.isnull().any().sum()
#plt.matshow(data.corr())
提取特征和标签数据:
y = data.iloc[:,1] 是错误的,这其实没有标题,序号也没有!列索引即使一列也要用范围提取。

x = data.iloc[:,2:31]
y = data.iloc[:,1:2]
查看诊断结果中良性和恶性肿瘤个数:
y.diagnosis.value_counts()

划分数据集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=10)
y = y.values.ravel()
使用交叉验证优化算法:
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
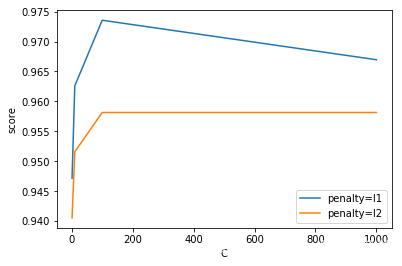
for i in ['l1','l2']:
lgrlist = []
for j in [1,10,100,1000]:
lgr = LogisticRegression(C=j, penalty=i)
lgr_cv_score = cross_val_score(lgr,x_train,y_train,cv=5)
lgr_cv_score_meanscore = lgr_cv_score.mean()
lgrlist.append(lgr_cv_score_meanscore)
plt.plot([1,10,100,1000], lgrlist, label='penalty='+str(i))
plt.legend()
plt.xlabel('C')
plt.ylabel('score')
lgr = LogisticRegression(C=100, penalty='l1')
lgr_cv_score = cross_val_score(lgr, x_train, y_train, cv=5)
lgr_meanscore = lgr_cv_score.mean()
随机梯度下降分类算法:
sklearn.linear_model.SGDClassifier
from sklearn.linear_model import SGDClassifier
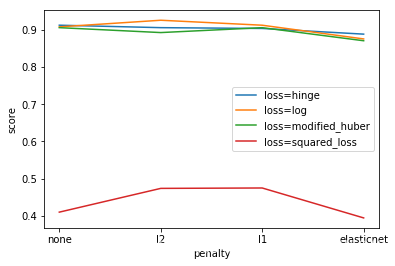
for i in ['hinge', 'log', 'modified_huber','squared_loss']:
SGDClist = []
for j in ['none','l2','l1','elasticnet']:
SGDC = SGDClassifier(penalty=j, loss=i, max_iter=1000)
SGDC_cv_score = cross_val_score(SGDC,x_train,y_train,cv=5)
SGDC_cv_score_meanscore = SGDC_cv_score.mean()
SGDClist.append(SGDC_cv_score_meanscore)
plt.plot(['none','l2','l1','elasticnet'], SGDClist, label='loss='+str(i))
plt.legend()
plt.xlabel('penalty')
plt.ylabel('score')
SGDC = SGDClassifier(loss='log', penalty='l2', max_iter=1000)
SGDC_cv_score = cross_val_score(SGDC, x_train, y_train, cv=5)
SGDC_meanscore = SGDC_cv_score.mean()
评估分类算法:
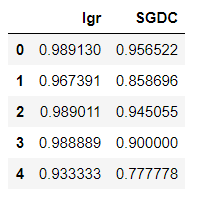
evaluating=pd.DataFrame({'lr':lr_cv_test_score,'SGDC':SGDC_cv_test_score})
evaluating
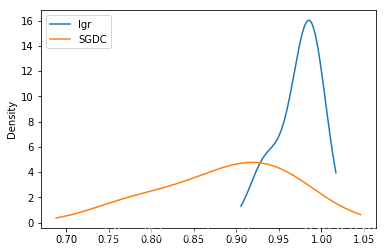
evaluating.plot.kde()
evaluating.mean().sort_values(ascending=False)

在测试集上验证模型性能:
#lgr
lgr.fit(x_train,y_train)
lgr_y_predict_score = lgr.score(x_test, y_test)
#SGDC
SGDC.fit(x_train,y_train)
SGDC_y_predict_score = SGDC.score(x_test, y_test)
predict_score = {
'lgr':lgr_y_predict_score,
'SGDC':SGDC_y_predict_score
}
predict_score = pd.DataFrame(predict_score, index=['score']).transpose()
predict_score.sort_values(by='score',ascending = False)
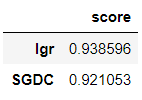
可见逻辑回归分类比随机梯度下降分类表现更好。
绘制学习曲线:
import sys
sys.path.append(r'C:\Users\Qiuyi\Desktop\scikit-learn code\code\common')
from utils import plot_learning_curve
from sklearn.model_selection import ShuffleSplit
title = 'Learning Curves (logisticRegression)'
cv = ShuffleSplit(n_splits=10, test_size=0.25, random_state=0)
plot_learning_curve(plt,lgr,title,x,y,ylim=(0.7, 1.01), cv=cv, n_jobs=4)
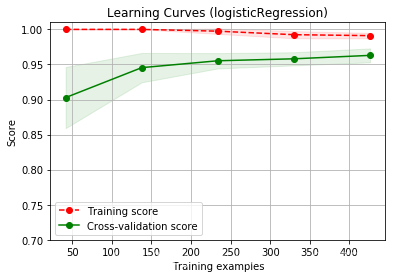
训练样本评分高,交叉验证样本评分也高,但两评分之间间隙还比较大,可以采用更多的数据来训练模型。