JAVA集合 Map 实现类 HashMap (映射表) 源码浅析
文章目录
- [一] 简述:
- [二] 构造方法:
- 1. 无参的构造方法 HashMap():
- 2.HashMap(int)
- 3.HashMap(int, float)
- 4. HashMap(Map<? extends K, ? extends V>)
- [三] Map 方法:
- 1.put(K, V)
- a) putForNullKey(V)
- b) addEntry(int, K, V, int)
- c) hash(int)
- d) indexFor(int, int)
- e) resize(int)
- f) transfer(Entry[])
- 2.get(Object)
- 3. remove(object)
- 4. keySet()
- 5. entrySet()
- 6. values()
- 7.size()
- 8.isEmpty()
- 9.clear()
- 10. putAll(Map<? extends K, ? extends V> m)
- 11. containsKey(Object)
- 12. containsValue(Object)
- 13. equals(Object)
- 14. hashCode()
- [四] 克隆Cloneable 与序列化Serializable
- 1. clone()
- a ) putAllForCreate(Map<? extends K, ? extends V>)
- b ) putForCreate(K, V)
- c ) createEntry(int, K, V, int)
- 2. writeObject(ObjectOutputStream)
- 3.readObject(ObjectInputStream)
- [五] 迭代器:
源码来自 JDK 1.6
[一] 简述:
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
如果很多映射关系要存储在 HashMap 实例中,则相对于按需执行自动的 rehash 操作以增大表的容量来说,使用足够大的初始容量创建它将使得映射关系能更有效地存储。
注意,此实现不是同步的。 如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须 保持外部同步。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的非同步访问,如下所示:
Map m = Collections.synchronizedMap(new HashMap(...));
由所有此类的“collection 视图方法”所返回的迭代器都是快速失败 的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
此类是 Java Collections Framework 的成员。
类图
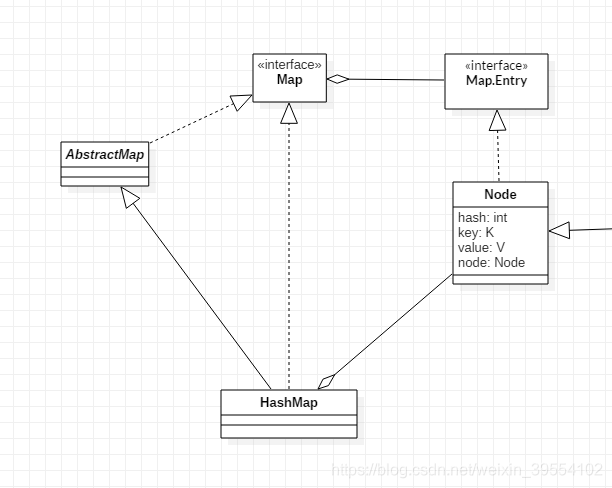
HashMap 最关键的属性:
| transient Entry[] table | 该表根据需要调整大小。 长度必须始终是2的幂。 |
| transient int size | 此映射中包含的键 - 值映射的数量。 |
| int threshold | 要调整大小的下一个大小值(capacity * load factor)。 |
| final float loadFactor | 哈希表的加载因子。 |
HashMap 存储数据的节点 接口 Map.Entry, 实现类 Entry
HashMap 存储数据的方式是, 数组 table[ ] + 链表 Entry, 即 table数组里存储的是不同链表的头节点;
关于java 链表的有关实现, 请看这里(java LinkedList 实现浅析)
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; // 记录(键)的指针
V value; // 记录(值)的指针
Entry<K,V> next; // 下一个节点的指针
final int hash; // key 的hash 值
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
/**
* 每当条目中的值被调用put(k,v)覆盖已经在HashMap中的密钥k时,就会调用此方法。
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* 只要从表中删除条目,就会调用此方法。
*/
void recordRemoval(HashMap<K,V> m) {
}
}
[二] 构造方法:
1. 无参的构造方法 HashMap():
源码注释: 使用默认初始容量(16)和默认加载因子(0.75)构造一个空的HashMap。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
/**
* 子类的初始化挂钩。 在初始化HashMap之后但在插入任何条目之前,
* 在所有构造函数和伪构造函数(clone,readObject)中调用此方法。
* (如果没有这种方法,readObject将需要明确的子类知识。)
*/
void init() {
}
2.HashMap(int)
源码注释: 使用指定的初始容量和默认加载因子(0.75)构造一个空的HashMap。
如果初始容量为负数, 抛出:IllegalArgumentException
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
3.HashMap(int, float)
源码注释: 使用指定的初始容量和加载因子构造一个空的HashMap。
如果初始容量为负数或负载因子为非正数, 抛出:IllegalArgumentException
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
4. HashMap(Map<? extends K, ? extends V>)
源码注释: 使用与指定Map相同的映射构造一个新的HashMap。 使用默认加载因子(0.75)创建HashMap,初始容量足以保存指定Map中的映射。
如果指定的映射为null, 抛出:NullPointerException
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
putAllForCreate(m);
}
[三] Map 方法:
1.put(K, V)
源码注释: 将指定的值与此映射中的指定键相关联。 如果映射先前包含键的映射,则替换旧值。
指定者:put(…)在Map中,覆盖:put(…)在AbstractMap中
存储节点设计到的方法:
红色线为, 如果 key 为 null 就调用 putForNullKey 方法,
存储一个节点完成后会调用 resizs 检测扩容.

public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
a) putForNullKey(V)
源码注释: 存储 null 键, 由源码逻辑可知, HashMap 允许 null 作为key 并且只能有一个.
因为, for 循环里找到第一个e, 就替换 value 返回;
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
b) addEntry(int, K, V, int)
源码注释: 将具有指定键,值和哈希码的新条目添加到指定存储桶。 如果合适,此方法的责任是调整表的大小。 子类重写此更改以改变put方法的行为。
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
c) hash(int)
源码注释: 将补充哈希函数应用于给定的hashCode,以防御质量差的哈希函数。 这很关键,因为HashMap使用两个幂的长度哈希表,否则会遇到低位不同的hashCodes的冲突。 注意:空键始终映射到散列0,因此索引为0。
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
d) indexFor(int, int)
源码注释: 返回哈希码h的索引。
static int indexFor(int h, int length) {
return h & (length-1);
}
e) resize(int)
源码注释: 将此映射的内容重新放入具有更大容量的新数组中。 当此映射中的键数达到其阈值时,将自动调用此方法。 如果当前容量为MAXIMUM_CAPACITY,则此方法不会调整映射大小,但会将阈值设置为Integer.MAX_VALUE。 这具有防止将来呼叫的效果。
参数: newCapacity的新容量,必须是2的幂; 必须大于当前容量,除非当前容量为MAXIMUM_CAPACITY(在这种情况下值不相关)。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
f) transfer(Entry[])
源码注释: 将当前表中的所有条目传输到newTable。
可以理解为, 复制就的映射表到新的表中,重新分配位置
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
2.get(Object)
源码注释: 返回指定键映射到的值,如果此映射不包含键的映射,则返回null。
更正式地说,如果此映射包含从键k到值v的映射,使得(key == null? k == null:key.equals(k)),则此方法返回v; 否则返回null。 (最多可以有一个这样的映射。)
返回值null不一定表示映射不包含键的映射; 地图也可能显式地将键映射为null。 containsKey操作可用于区分这两种情况。
返回: 指定键映射到的值,如果此映射不包含键的映射,则返回null
方法调用:
如果key 为空, 即调用getForNullKey 方法;
否则, 计算 key的hash 值, 再计算索引值, 获取到链表的头节, 循环链表.
当, hash 冲突(即hash 值 计算出来的索引值相等时)比较大量时, 获取value 会变得慢, 时间复杂度为 O(n)
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
a) getForNullKey()
源码注释: 卸载版本的get()来查找null键。 空键映射到索引0.为了在两个最常用的操作(get和put)中执行,这个空案例被拆分为单独的方法,但在其他操作中包含条件。
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
3. remove(object)
源码注释: 从此映射中删除指定键的映射(如果存在)。
与key关联的先前值,如果没有key的映射,则返回null。 (null返回也可以指示以前的映射与键关联的null。)
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
a) removeEntryForKey(Object)
源码注释: 删除并返回与HashMap中指定键关联的条目。 如果HashMap不包含此键的映射,则返回null。
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
4. keySet()
源码注释: 返回此映射中包含的键的Set视图。 该集由地图支持,因此对地图的更改将反映在集中,反之亦然。 如果在对集合进行迭代时修改了映射(除了通过迭代器自己的remove操作),迭代的结果是未定义的。 该集支持元素删除,它通过Iterator.remove,Set.remove,removeAll,retainAll和clear操作从地图中删除相应的映射。 它不支持add或addAll操作。
返回值: 此映射中包含的键的设置视图
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
a ) KeySet 实现类
源码分析:
KeySet 对象支持的方法只有查找的的一些功能, size iterator claer contains remove 的方法由实现它的迭代器所完成
private final class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
}
5. entrySet()
源码注释: 返回此映射中包含的映射的Set视图。 该集由地图支持,因此对地图的更改将反映在集中,反之亦然。 如果在对集合进行迭代时修改了映射(除非通过迭代器自己的remove操作,或者通过迭代器返回的映射条目上的setValue操作),迭代的结果是未定义的。 该集支持元素删除,它通过Iterator.remove,Set.remove,removeAll,retainAll和clear操作从地图中删除相应的映射。 它不支持add或addAll操作。
返回: 此映射中包含的映射的set视图
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
a ) EntrySet 实现类
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> e = (Map.Entry<K,V>) o;
Entry<K,V> candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
public boolean remove(Object o) {
return removeMapping(o) != null;
}
public int size() {
return size;
}
public void clear() {
HashMap.this.clear();
}
}
6. values()
源码注释: 返回此映射中包含的值的Collection视图。 该集合由地图支持,因此对地图的更改将反映在集合中,反之亦然。 如果在对集合进行迭代时修改了映射(除了通过迭代器自己的remove操作),迭代的结果是未定义的。 该集合支持元素删除,它通过Iterator.remove,Collection.remove,removeAll,retainAll和clear操作从地图中删除相应的映射。 它不支持add或addAll操作。
返回值: 此映射中包含的值的集合视图
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
}
a) Values 实现类
private final class Values extends AbstractCollection<V> {
public Iterator<V> iterator() {
return newValueIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
HashMap.this.clear();
}
}
7.size()
源码注释: 返回此映射中键 - 值映射的数量。
public int size() {
return size;
}
8.isEmpty()
源码注释: 如果此映射不包含键 - 值映射,则返回true。
public boolean isEmpty() {
return size == 0;
}
9.clear()
源码注释: 从此映射中删除所有映射。 此调用返回后,映射将为空。
源码分析: 此处是把 table 数组的每个元素置空, 而链表的每个节点还是各种引用,
gc 会从第一个节点开始回收, 但是gc 是否会判断这整个链表是否已经不再被引用
public void clear() {
modCount++;
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)
tab[i] = null;
size = 0;
}
10. putAll(Map<? extends K, ? extends V> m)
源码注释: 将指定映射中的所有映射复制到此映射。 这些映射将替换此映射对当前位于指定映射中的任何键的任何映射。
抛出: NullPointerException - 如果指定的映射为null
public void putAll(Map<? extends K, ? extends V> m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
/**
* 如果要添加的映射数大于或等于阈值,则展开地图。 这是保守的;
* 明显的条件是 (m.size() + size) >= threshold ,
* 但如果要添加的键与此映射中已有的键重叠,则此条件可能会导致映射具有两倍的适当容量。
* 通过使用保守计算,我们最多可以对自己进行一次额外的调整。
*/
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
for (Iterator<? extends Map.Entry<? extends K, ? extends V>> i = m.entrySet().iterator(); i.hasNext(); ) {
Map.Entry<? extends K, ? extends V> e = i.next();
put(e.getKey(), e.getValue());
}
}
11. containsKey(Object)
源码注释: 如果此映射包含指定键的映射,则返回true。
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
a ) getEntry(Object)
源码注释: 返回与HashMap中指定键关联的条目。 如果HashMap不包含键的映射,则返回null。
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
12. containsValue(Object)
源码注释: 如果此映射将一个或多个键映射到指定值,则返回true。
public boolean containsValue(Object value) {
if (value == null)
return containsNullValue();
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
a ) containsNullValue()
源码注释: 带有null参数的containsValue的特例代码
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
13. equals(Object)
源码注释: 将指定对象与此映射进行比较以获得相等性。如果给定对象也是一个映射,并且两个映射表示相同的映射,则返回true。更正式地说,如果 m1.entrySet().equals(m2.entrySet()) . 则两个映射m1和m2表示相同的映射。这确保了equals方法在Map接口的不同实现中正常工作。
此实现首先检查指定的对象是否是此映射;如果是这样,它返回true。然后,它检查指定的对象是否是一个大小与该映射的大小相同的映射;如果不是,则返回false。如果是这样,它将迭代此映射的entrySet集合,并检查指定的映射是否包含此映射包含的每个映射。如果指定的映射未能包含此类映射,则返回false。如果迭代完成,则返回true。
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<K,V> m = (Map<K,V>) o;
if (m.size() != size())
return false;
try {
Iterator<Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(m.get(key)==null && m.containsKey(key)))
return false;
} else {
if (!value.equals(m.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
return true;
}
14. hashCode()
源码注释: 返回此映射的哈希码值。 映射的哈希码被定义为映射的entrySet()视图中每个条目的哈希码的总和。 这确保m1.equals(m2)暗示对于任何两个映射m1和m2的 m1.hashCode()==m2.hashCode(),如Object.hashCode的常规协定所要求的。
此实现迭代entrySet(),在集合中的每个元素(条目)上调用hashCode(),并将结果相加。
public int hashCode() {
int h = 0;
Iterator<Entry<K,V>> i = entrySet().iterator();
while (i.hasNext())
h += i.next().hashCode();
return h;
}
[四] 克隆Cloneable 与序列化Serializable
1. clone()
源码注释: 返回此HashMap实例的浅表副本:未克隆键和值本身。
public Object clone() {
HashMap<K,V> result = null;
try {
result = (HashMap<K,V>)super.clone();
} catch (CloneNotSupportedException e) {
// assert false;
}
result.table = new Entry[table.length];
result.entrySet = null;
result.modCount = 0;
result.size = 0;
result.init();
result.putAllForCreate(this);
return result;
}
a ) putAllForCreate(Map<? extends K, ? extends V>)
private void putAllForCreate(Map<? extends K, ? extends V> m) {
for (Iterator<? extends Map.Entry<? extends K, ? extends V>> i = m.entrySet().iterator(); i.hasNext(); ) {
Map.Entry<? extends K, ? extends V> e = i.next();
putForCreate(e.getKey(), e.getValue());
}
}
b ) putForCreate(K, V)
源码注释: 使用此方法而不是由构造函数和伪辅助对象(clone,readObject)放置。 它不会调整表的大小,检查编码等。它调用createEntry而不是addEntry。
private void putForCreate(K key, V value) {
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
/**
*寻找密钥的预先存在的条目。 这绝不会发生
*克隆或反序列化。 它只会发生在建筑上
*输入Map是一个有序的映射,其排序与w / equals不一致。
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
e.value = value;
return;
}
}
createEntry(hash, key, value, i);
}
c ) createEntry(int, K, V, int)
源码注释: 与addEntry类似,只是在创建条目时使用此版本作为Map构造或“伪构造”(克隆,反序列化)的一部分。 此版本无需担心调整表的大小。 子类重写此更改以改变HashMap(Map),clone和readObject的行为。
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
size++;
}
2. writeObject(ObjectOutputStream)
源码注释: 将HashMap实例的状态保存到流中(即序列化它)。
@serialData
HashMap的容量(桶数组的长度)发出(int),后跟size(一个int,键值映射的数量),然后是每个键的键(Object)和值(Object) 键值映射。 键值映射没有特别发出
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
Iterator<Map.Entry<K,V>> i =
(size > 0) ? entrySet0().iterator() : null;
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
// Write out number of buckets
s.writeInt(table.length);
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
if (i != null) {
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}
}
3.readObject(ObjectInputStream)
源码注释: 从流中重构HashMap实例(即,反序列化它)。
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException {
// Read in the threshold, loadfactor, and any hidden stuff
s.defaultReadObject();
// Read in number of buckets and allocate the bucket array;
int numBuckets = s.readInt();
table = new Entry[numBuckets];
init(); // Give subclass a chance to do its thing.
// Read in size (number of Mappings)
int size = s.readInt();
// Read the keys and values, and put the mappings in the HashMap
for (int i=0; i<size; i++) {
K key = (K) s.readObject();
V value = (V) s.readObject();
putForCreate(key, value);
}
}
[五] 迭代器:
HashMap 有三个迭代器的实现类分别是: EntryIterator / KeyIterator / ValueIterator
类图
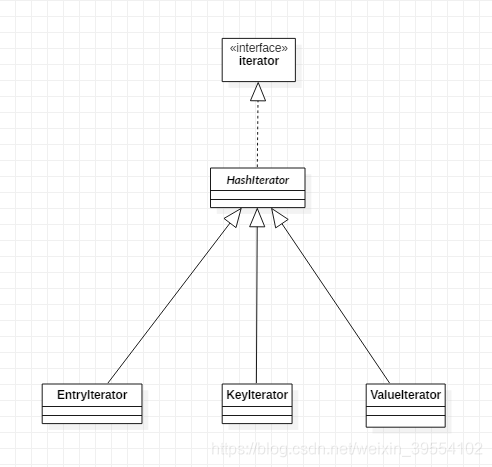
0. HashIterator
HashIterator 是一个抽象类,注意: next() 的方法没有实现, 有具体的子类实现.
字段说明:
| next | 下一个节点的指针 |
| expectedModCount | 快速失败的计数器 |
| index | 当前获取节点的次数 |
| current | 当前节点 |
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
1. EntryIterator
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
2.KeyIterator
private final class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
3.ValueIterator
private final class ValueIterator extends HashIterator<V> {
public V next() {
return nextEntry().value;
}
}
关于这个迭代器在什么地方使用, 请看对于的 entrySet() 方法 、 keySet()、values(), 具体实现;
// Subclass overrides these to alter behavior of views' iterator() method
Iterator<K> newKeyIterator() {
return new KeyIterator();
}
Iterator<V> newValueIterator() {
return new ValueIterator();
}
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
如有谬误, 欢迎指正.