HashMap
HashMap的key和value值都允许为null,线程不安全,同时不能保证元素的内部顺序不改变。底层数据结构采用数组+单向链表/红黑树,以bucket(桶)数组做为HashMap的主体,以链表或红黑树解决哈希冲突。

接下来结合JDK源码学习:
HashMap的初始容量值为16,构造函数中默认的负载因子为0.75,当达到这个值时数组将进行2倍的扩容。


也可自己传入容量和负载因子参数:

扩容机制:
1.首先判断当前容量是否已经达到最大容量,如果达到了,就不再扩容。

2.如果当前容量超过了16且扩大一倍后容量仍然小于最大容量,则容量扩大一倍。
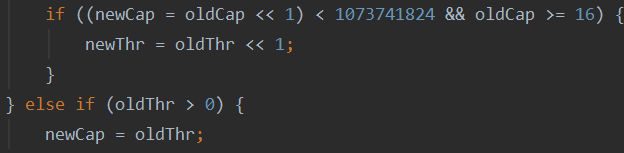
3.如果是完全新建一个桶数组,则赋值默认容量16和默认的扩容阙值(16 * 0.75 = 12)

4.如果扩容阙值为0(newThr),则根据当前的容量和负载因子计算扩容阙值。

5.最后按照上述得到的容量构建一个新的桶数组(newTab)并将原有数组存入其中。
this.threshold = newThr;
HashMap.Node<K, V>[] newTab = new HashMap.Node[newCap];
this.table = newTab;
if (oldTab != null) {
for(int j = 0; j < oldCap; ++j) {
HashMap.Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) {
newTab[e.hash & newCap - 1] = e;
} else if (e instanceof HashMap.TreeNode) {
((HashMap.TreeNode)e).split(this, newTab, j, oldCap);
} else {
HashMap.Node<K, V> loHead = null;
HashMap.Node<K, V> loTail = null;
HashMap.Node<K, V> hiHead = null;
HashMap.Node hiTail = null;
HashMap.Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null) {
loHead = e;
} else {
loTail.next = e;
}
loTail = e;
} else {
if (hiTail == null) {
hiHead = e;
} else {
hiTail.next = e;
}
hiTail = e;
}
e = next;
} while(next != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
put(K key, V value):
1.获取传入key的hash值

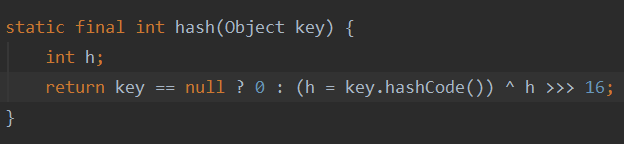
2.判断当前tab值是否为null或者长度是否为0,如果是,则进行扩容操作。
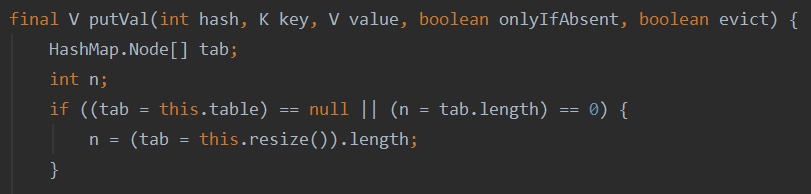
3.通过哈希函数由hash值获取table中的下标。如果当前位置没有任何元素,则构建新的node存入当前位置。
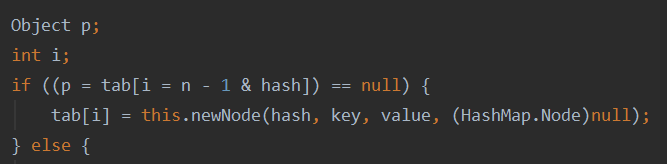
4.如果当前node的key和hash值与传入参数一致,则进行覆盖。

5.如果当前node位置存放的是红黑树,则进行红黑树的插入操作。

6.如果当前node位置存放的是链表,则遍历寻找符号第4步的节点,对其进行覆盖,否则将节点插入该链表末尾,同时判断是否需要转换为红黑树和扩容操作。

get(Object key):
get方法与put方法类似,通过key值获取对应的hash值,然后转换为数组下标,再对该位置数据进行遍历查找。


remove(Object key):
1.判断table和传入的key值对应下标是否为空

2.判断链表第一个节点是否为寻找节点,是的话就赋值给node

3.如果当前位置存放的是红黑树,则利用getTreeNode方法寻找节点。
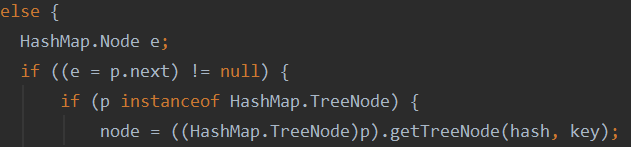
4.如果是链表,则遍历寻找节点赋值给node
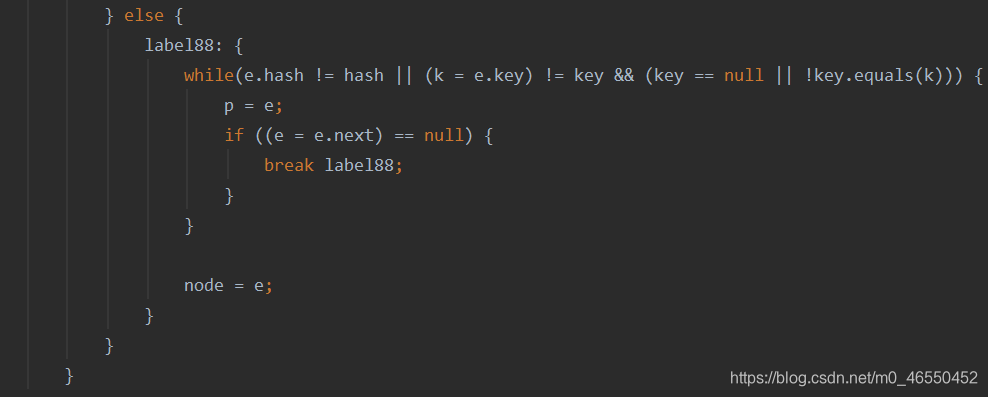
5.对node进行判空,同时判断其value值是否与传入参数相等,然后进行删除。

注意:equals方法默认是比较两个元素的内存地址,所以我们需要对equals方法进行覆盖重写,用来保证key值不会重复。